第一章 RTP 介绍
本章目录
- 音视频网络简史
- RTP 简况
- 相关标准
- RTP 实现的概述
互联网正在发生改变:静态内容正让位于流媒体视频,文本正在被音乐和语音所取代,大家对交互式音频和视频习以为常。这些变化需要新的应用,这给应用设计人员带来了全新且独特的挑战。
本书描述了如何构建 VOIP、电话、电话会议、流媒体视频和网络广播等这些新型应用, 同时也探讨了在 IP 网络上可靠地传输音频和视频的固有的挑战,并说明了:如何在网络异常面前确保质量,确保系统安全。本书的重点是开放标准,而不是私有解决方案,特别是由互联网工程任务组(IETF)和国际电信联盟(ITU)设计的标准。
本章开头介绍实时传输协议(RTP),并简要回顾了音频/视频网络的历史,最后简述了 RTP 与其他标准的关系。
音视频网络的简介
使用分组网络传输音视频的想法并不新鲜。分组网络上的语音实验可以追溯到 20 世纪 70 年代初。1977年就出现了 第一个关于语音实验的RFC—网络语音协议 。视频会议和流媒体的实验虽然出现的较晚,但也已经有十多年了。
早期的分组语音和视频实验
NVP最初的开发者是在ARPANET上进行分组语音传输的研究人员,ARPANET是互联网的前身。ARPANET提供了可靠流服务(类似于TCP/IP),但这导致了太多的延迟,因此开发了一种类似于现代使用RTP的UDP/IP数据报的“无控制分组”服务。NVP直接在这个无控制分组服务的基础上进行了分层。后来,这些实验扩展到了ARPANET之外,与分组无线电网络和大西洋卫星网络(SATNET)进行了互操作,通过这些网络在NVP上运行。
由于早期网络的带宽都很低,实验都局限于一两个语音通道。20 世纪 80 年代,拥有 3Mbps 宽带的卫星网络的建立使更多的语音通道成为可能,而且还促进了分组视频的发展。人们开发了一种被称为面向连接的互联网络协议的流协议(ST),用来访问卫星网络服务,这种卫星网络只有一跳,带宽预留,支持多播。NVP 的第二个版本(NVP-II)和配套的分组视频协议都通过 ST 交互,这为后面支持分组交换视频的会议服务提供了样板。
在1989年至1990年期间,卫星网络被陆地宽带网络(Terrestrial Wideband Network)和一个名为DARTnet的研究网络所取代,同时ST发展成了ST-II。分组视频会议系统开始定期支持网络研究人员和其他人在最多五个地点参会人同时进行会议。
ST和ST-II在互联网络层与IP并行运行,但仅ST和ST-II只在政府和研究网络上有限度地部署。作为替代方案,DARTnet开始部署在IP网络上,进行视频会议。而通过组播UDP/IP传输数据的NVP-II实现了多方会议。在1992年3月的IETF会议上,音频通过Internet在三个大陆的20个地点进行了组播"隧道"传输,这个"隧道"被称为Mbone(代表"组播骨干"),它是从DARTnet扩展而来的。在同一次会议上,开始了RTP协议的开发。
互联网上的音视频
经过一系列的早期实验,互联网社区对视频会议的兴趣在 20 世纪 90 年代初就开始了。大约在这个时候,工作站和个人电脑的处理能力和多媒体功能已经足以同时采集、压缩和播放音/视频流。与此同时,IP 组播的发展允许将实时数据传输到任意数量的互联网的终端。
众所周知,视频会议和流媒体都是运行良好的多播应用。研究小组着手开发视频会议工具和协议,比如劳伦斯伯克利实验室研发的 vic 和 vat,马萨诸塞大学研发的 nevot, Xerox PARC 研发的 INRIA 视频会议系统和 nv,以及伦敦大学学院研发的 rat。这些工具遵循了一种新的会议方案,基于无连接协议、端到端参数和应用级框架。会议被最低限度地管理,没有准入或最低控制,而且传输层单薄且适应性强。多播既用于广域数据传输,也用作同一机器上应用之间的进程间通信机制(用于在音频和视频工具之间交换同步信息)。由此产生的协作环境由轻度耦合的应用和高度分布式的参与者组成。
多播会议(Mbone)使人们广泛认识到通过 IP 网络传输实时媒体的固有问题:可伸缩的需求,错误恢复和拥塞控制。这些问题直接影响了协议和标准的开发关键点。
RTP 是在 1992-1996 年期间由 IETF 开发的,以 NVP-II 和原始 vat 使用的协议为基础。多播会议采用 RTP 作为唯一的数据传输和控制协议; 因此,RTP 不仅包括媒体发布,还支持会员管理、音视频同步和接收质量报告。
除了用于传输实时媒体的 RTP 之外,还必须开发其他协议来协商和控制媒体流。会话通知协议(SAP)是为了通知多播数据流而开发的。会话通知本身就是多播的,任何具有多播能力的主机都可以接收 SAP 通知并会议和传输的内容。在通知中,会话描述协议(SDP)描述了发送端和接收端在多播会话中使用的传输地址以及压缩/分组方案。多播部署的缺乏和万维网的兴起在很大程度上取代了分布式多播目录的概念,但 SDP 在今天仍被广泛使用。
最后,Mbone 社区主导了会话发起协议(SIP)的开发。SIP 用来作为一种轻量级的方法来查找参与者,并让一组指定的参与者开始多播会话。在早期的版本中,SIP 几乎不包括呼叫控制和协商的支持,因为这些方面在 Mbone 会议也没有。现在,SIP已经成为一个更全面的协议,包括广泛的协商和控制功能。
ITU Standards
与早期分组语音工作并行的是**综合业务数字网(ISDN)**的发展,ISDN是普通老式电话系统的数字版本,也是视频会议标准。这些标准基于 ITU 的提案 H.320,使用电路交换链路,因此与我们对分组音频和视频的讨论没有直接关系。然而,他们开创了许多今天大量使用的压缩算法(例如 H.261 视频)。
因特网的发展和商业世界中局域网设备的广泛部署促使国际电联扩展 H.320 系列协议。具体说来,他们试图使协议适合于“提供无保证服务质量的局域网”,IP 是一个符合描述的经典协议族。这也引起了 H.323 的系列提案书的诞生。
H.323 于 1997 年首次出版,此后几经修改。它提供了一个由媒体传输、呼叫信令和会议控制组成的框架。信令和控制功能在 ITU 提案书 H.225.0 和 H.245 中定义。最初,信令协议主要集中在使用 H.320 与 ISDN 会议的互操作上,结果导致繁琐的会话设置过程,该标准的后续版本简化了这一过程。关于媒体传输,电信联盟工作组采纳了 RTP。然而,H.323 只使用了 RTP 的媒体传输功能,很少使用控制和报告元素。
H.323 在市场上取得了一定的成功,有几个硬件和软件产品是为支持 H.323 技术套件而构建的。开发体验导致了对其复杂性的抱怨,特别是 H.323 版本的复杂设置过程和对信令使用的二进制消息格式。其中一些问题在后来的 H.323 版本中得到了解决,但在此期间,人们对替代方案的兴趣有所增加。
其中一个我们已经提到过的替代方案是 SIP。最初的 SIP 规范是 IETF 在 1999 年发布的,它是一个学术研究项目的成果,几乎没有商业利益。此后,在很多领域,它都被视为 H.323 的替代品,并被应用于更多样化的应用中,比如短信系统和 ip 电话。此外,SIP正在被考虑用于第三代移动电话系统,并已获得相当多的行业支持。
国际电信联盟最近提出了提案 H.332,它结合了紧密耦合的 H.323 会议和轻量级多播会议。该结果对于在线研讨会等场景非常有用,在在线研讨会中,会议的 H.323 部分允许一组发言者之间的密切交互,而被动的观众则通过多播观看。
音视频流
在多播会议和 H.323 发展的同时,万维网革命也发生了,它为因特网带来了精美的内容, 公众也开始普遍接受因特网。网络带宽和终端系统容量方面的进步使流媒体音频和视频与网页同时传输成为可能,RealAudio 和 QuickTime 等系统在这方面处于领先地位。这类系统的市场不断增长,促使人们希望为流媒体内容设计一种标准的控制机制。结果是实时流协议(RTSP),它能提供流媒体演示的启动和类似于录像机的控制; RTSP 于 1998 年标准化。RTSP 建立在现有的标准之上: RTSP行为上非常类似于 HTTP,但RTSP用 SDP 进行会话描述, RTP 进行媒体传输。
RTP 简况
IP 网络中音频/视频传输的关键标准是实时传输协议(RTP)及其相关配置文件和有效负载格式。RTP 旨在通过 IP 网络建立传输实时媒体传输服务,如音频和视频。这些服务包括定时恢复、丢包检测和恢复、负载和源标识、接收质量反馈、媒体同步和会员管理。RTP 最初设计用于多播会议,使用轻量级会话模型。从那时起,它已被证明对一系列其他应用有用: H.323 视频会议、网络广播和电视分发; 有线电话和移动电话都是如此。该协议已被证明可以从点对点使用扩展到具有数千用户的多播会话,从低带宽蜂窝电话应用扩展到以千兆比特速率传输未压缩的高清晰度电视(HDTV)信号。
RTP 是由 IETF 的音频/视频传输工作组开发的,后来被国际电联作为其 H.323 系列提案的一部分而采用,并被其他各种标准组织采用。RTP 的第一个版本是在 1996 年 1 月完成的,在完成之前需要对特定用途的 RTP 进行概要分析; RTP 规范定义了一个初始概要,还有几个概要正在开发中。附带几个负载格式规范的配置文件描述了特定媒体格式的传输。RTP 的开发正在进行中,在撰写本文时,一个修订已经接近完成。
在第三章会详细介绍 RTP,即实时传输协议,本书的大部分内容讨论了使用 RTP 的系统的设计及其各种扩展。
相关标准
除了 RTP 之外,完整的系统通常还需要使用各种其他协议和标准来进行会话通知、启动/控制、媒体压缩和网络传输。
图 1.1 描绘了IETF 和国际电信联盟会议框架,这个框架包含了协商和呼叫控制协议、媒体传输层(由 RTP 提供)、压缩解码算法(codecs)和底层网络之间的关系。这两套并行的呼叫控制和媒体协商标准使用相同的媒体传输框架。不管会话是如何协商的,也不管底层网络传输是什么,媒体编解码器都是通用的。
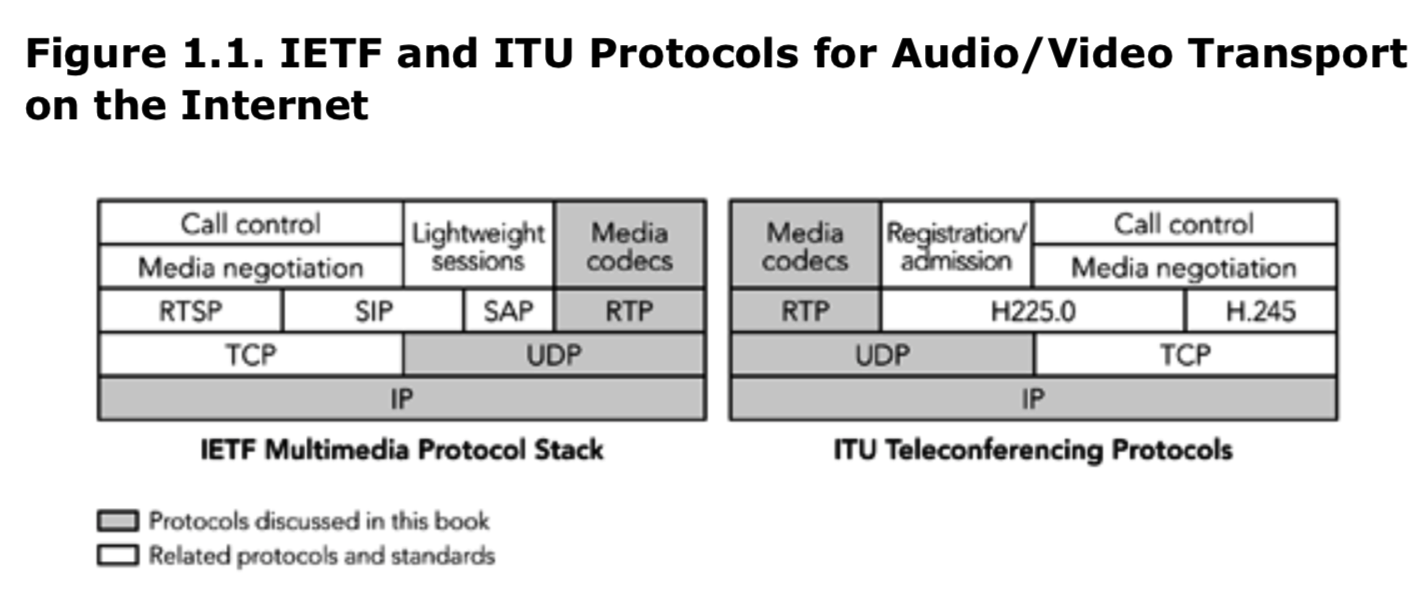
这些标准与RTP的关系在第3章“实时传输协议”中有详细描述。不过,本书的主要关注点在于媒体传输,而不是信号和控制。
RTP 实现的概述
如图 1.1 所示,任何通过IP网络传输实时音频/视频的系统的核心都是 RTP: 它提供公共的媒体传输层,独立于信令协议和应用。在我们更详细地研究 RTP 和使用 RTP 的系统设计之前,有必要了解一下系统中 RTP 发送端和接收端的职责。
RTP 发送端的行为
发送端负责采集和转换用于传输的视听数据,以及生成 RTP 包。它还可以通过调整传输的媒体流以响应接收端的反馈来参与错误恢复和拥塞控制。发送过程的关系如图 1.2 所示。
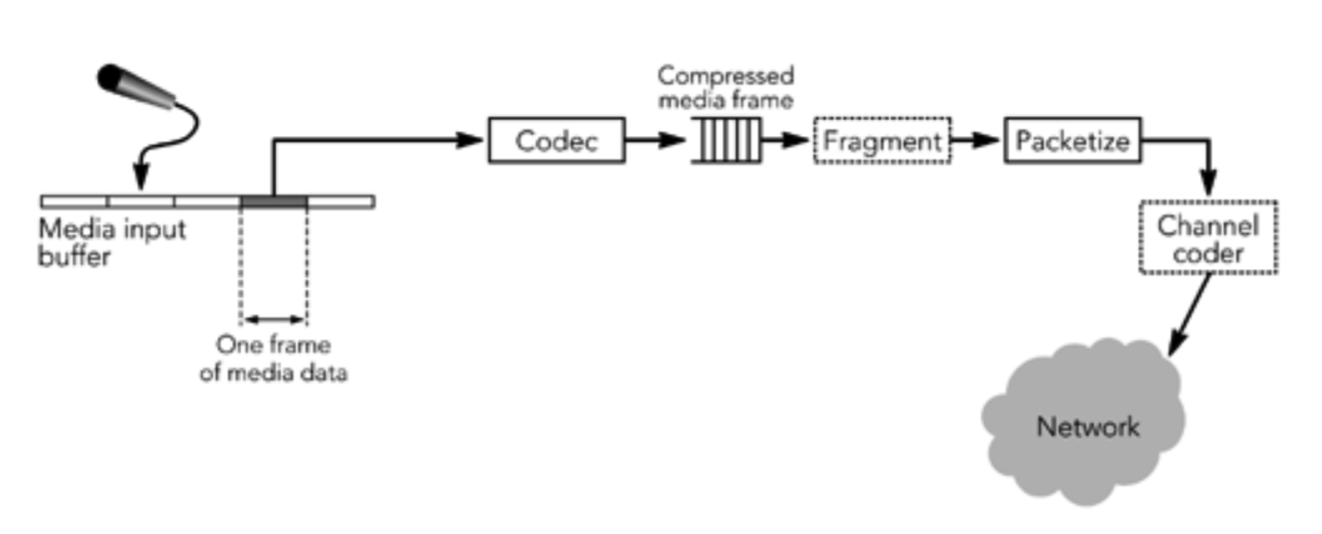
未压缩的媒体数据(音频或视频)被采集到缓冲区中,压缩为数据帧。数据帧帧可以根据使用的压缩算法以多种方式进行编码,编码后的帧可能同时依赖于之前和之后的数据。
压缩帧被装入 RTP 包中,准备发送。如果帧很大,它们可能被分成几个 RTP 包; 如果它们很小,可以将几个帧绑定到一个 RTP 包中。根据配套的错误恢复方案,可以使用信道编码器来生成错误恢复包或在传输之前重新对包进行排序。
发送 RTP 包之后,与这些包对应的缓冲媒体数据最后会被释放。发送端不能丢弃可能需要用于错误恢复或编码的数据。这意味着发送端在发送了相应的数据包之后,必须将数据缓存一段时间,这个时间取决于所使用的编解码器和错误恢复方案。
发送端负责生成它所生成的媒体流的定期状态报告,包括唇音同步所需的媒体流。它还从其他参与者那里收到接收质量反馈,并可能利用这些信息来调整其传输。
RTP 接收端的行为
接收端负责从网络中收集 RTP 数据包,恢复丢失的数据,纠正时序,解码媒体,并将结果显示给用户。同时,接收端还需要发送接收质量反馈,帮助发送端调整往接收端的传输策略,并维护会话中参与者的数据库。接收过程方框图如图 1.3 所示; 但是具体实现有时根据需要以不同的顺序执行操作。
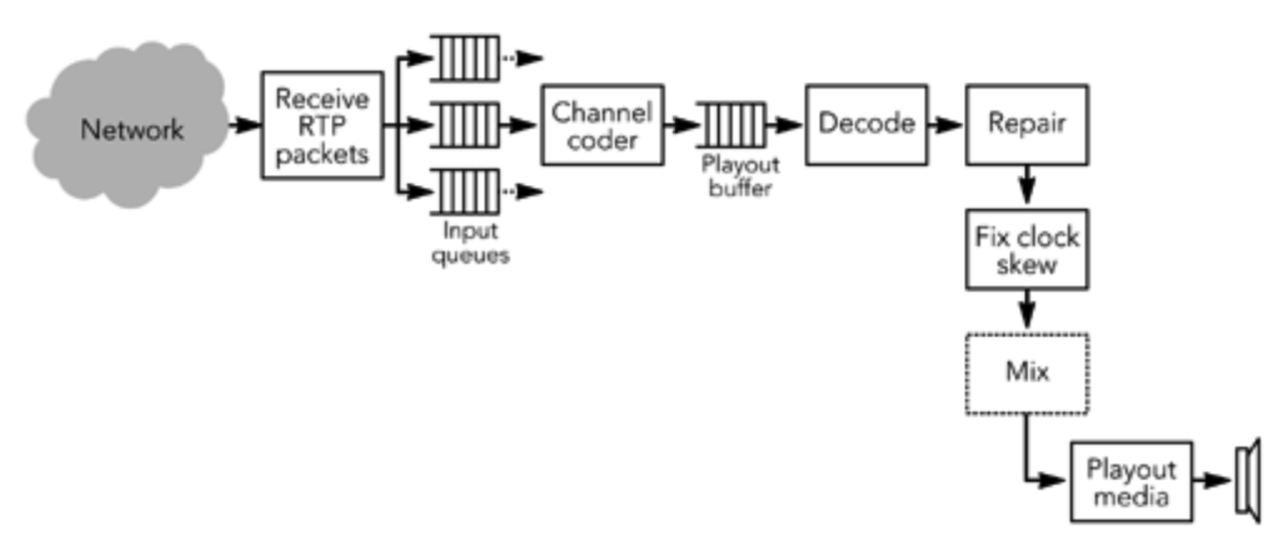
接收过程的第一步是收集来自网络的数据包,验证它们的正确性,并将它们插入到特定发送端的输入队列中。从输入队列中收集数据包,并将其传递给可选的信道编码例行程序以恢复丢失的数据。在到达编码器之后,数据包被插入到指定源的播放缓冲区中。播放缓冲区按时间戳排序,将数据包插入缓冲区的过程纠正了传输期间引起的排序错乱。数据包一直保留在播放缓冲区中,直到接收到完整的帧为止。除此之外,还对缓存数据帧,以消除由网络引起的包间到达时间抖动。计算要在各个步骤内部延迟量是 RTP 实现设计中最关键的方面之一。每个包都用相应帧所需的播放时间进行标定。
当数据包的播放时间到达后,这些包形成完整的帧,我们也需要修复损坏或丢失的帧。在进行任何必要的修复之后解码数据帧(根据使用的编解码器,在修复丢失的帧之前可能需要解码媒体)。在这一点上,发送端和接收端的名义时钟速率可能有明显的差异。这些差异表现为 RTP 媒体时钟相对于播放时钟的值的偏移。接收端必须补偿这个时钟偏差,以避免在播放中出现间隙。
从这篇简短的概述中可以明显看出,RTP 接收端的操作很复杂,它比发送端的操作更加复杂。这种复杂性的增加主要是由于 IP 网络的不确定性(大部分复杂性来自于补偿丢失的包的需要,以及恢复受抖动影响的流的时序)。
总结
本章介绍了通过 IP 网络实时传输多媒体的协议和标准,特别是实时传输协议(RTP)。本书的其余部分将详细讨论 RTP 的特性和使用。其目的是扩展标准文档,解释标准背后的基本原理和可能的实现选择及其权衡。
第二章 分组网络上的语音和视频通信
本章目录
- TCP/IP 参考模型和 OSI 参考模型
- IP 网络性能特征
- 测量 IP 网络性能
- 传输协议的影响
- 分组网络中传输音频/视频的条件
在深入研究 RTP 细节之前,应该了解IP网络的特性,以及这些特性是如何影响语音/视频通信的。
本章回顾了 Internet 体系结构的基础知识,概述了 Internet 的典型运行模式。最后,讨论传输音频和视频的条件,以及Internet如何满足这些条件。
IP 网络具有一些影响音频/视频应用和传输协议设计的独特特性。如果你想了解 RTP 设计中所涉及的权衡问题,以及IP 网络的特性如何影响使用 RTP 应用的使用,所以理解这些特性至关重要。
TCP/IP 和 OSI 参考模型
当你考虑计算机网络时,理解协议分层的概念和含义是很重要的。如图 2.1 所示的 OSI 参考模型,为分层系统的讨论和比较提供了基础模型。

OSI 参考模型分为七层,每一层都建立在较低层提供的服务之上,并为上一层提供更抽象的服务。各层的功能如下:
-
物理层 最底层(物理层)包括物理网络连接设备和协议,如电缆、插头、开关和电气标准。
-
数据链路层 数据链路层建立在物理连接的基础上;例如,它将双绞线转换成以太网。这一层为数据传输单元提供帧,定义如何在多个连接的设备之间共享链接,并为每个链接上的设备提供寻址。
-
网络层 网络层连接链接,将它们统一为一个网络。它通过网络提供消息的寻址和路由。它还可以控制交换机中的拥塞、某些消息的优先级、计费等等。网络层设备处理从一个链接接收到的消息,并将其发送到另一个链接,使用与这些链接远端节点交换的路由信息。
-
传输层 传输层是第一个端到端的层。它负责使用网络层提供的服务将消息从一个系统传递到另一个系统。此职责包括在会话层需要时提供网络层没有提供的可靠性和流控制。
-
会话层 会话层以对应用有意义的方式管理传输连接。示例包括用于检索 Web 页面的超文本传输协议 (HTTP)、电子邮件交换期间的简单邮件传输协议 (SMTP) 协商以及管理文件传输协议 (FTP) 中的控制和数据通道。
-
表示层 表示层描述了较低层所传递的数据的格式。示例包括用于描述 Web 页面表示的 HTML(超文本标记语言)、描述电子邮件格式的 MIME(多用途 Internet 邮件扩展)标准,以及更常见的问题,如 FTP 中的文本传输和二进制传输之间的差异。
-
应用层 应用本身—例如 web 浏览器和电子邮件客户机—构成系统的顶层,即应用层。
OSI 参考模型中每一层,相互之间跨主机逻辑对等通信。当一端的应用希望与另一端上的应用进行通信时,通信将向下通过源主机的各个层,最后通过物理连接的传递,然后向上到达目的地的协议堆栈。
例如,Web 浏览器使用双绞线在以太网数据链路上,通过 TCP 传输连接,通过 IP 网络,使用 HTTP 表示会话,渲染 HTML 。每个步骤都可以被看作是模型的特定层的实例化,一直到协议栈。其结果是将 Web 页面从应用 (Web 服务器)转移到应用 (Web 浏览器)。
源和目的地之间可能没有直接的物理连接,在这种情况下,连接必须在中间网关系统上提升协议栈。它需要提升到什么程度?这取决于所连接。以下是一些例子:
-
日益流行的 IEEE 802.11b 无线网络使用基站将一个物理层(通常是有线以太网)连接到另一个物理层(无线链路)。
-
IP 路由器提供了网关的一个示例,其中多个数据链路在网络级连接。在移动电话上查看 Web 页面通常需要连接一直上升到网关中的表示层,该层将 HTML 转换为无线标记语言 (WML),并将连接传递到不同的低层。
-
如上所述,我们可以使用 OSI 参考模型来描述互联网。这种契合并不完美:互联网的架构是随着时间的推移而演变的,在一定程度上早于 OSI 的模式,通常来讲,实际分层表现出的严格性比所描述的要低得多。然而,考虑互联网协议套件与 OSI 模型之间的关系,特别是 IP 作为一个通用网络层所扮演的角色,是很有意义的。
OSI 参考模型的最低两层可以直接与 Internet 相关,Internet 可以通过各种链接工作,如拨号调制解调器、DSL、以太网、光纤、无线和卫星。每个链接都可以用 OSI 模型的数据链路/物理层分割来描述。
在网络层,特定的协议将一组完全不同的私有网络转换为全球 Internet。这就是互联网协议,IP层 向上层提供的服务很简单:尽最大努力将数据报传递到指定的目的地。由于这项服务非常简单,IP层 可以广泛的部署在链路层上,使得互联网能够快速传播。
但是简单不是没有代价的:IP协议不能保证任何类型的传输时效性,甚至数据可能根本不会被正确的传递:数据包可能会丢失、重新排序、延迟或被低层损坏。IP 不会试图纠正这些问题;相反,它将数据报原封不动地传递到上层。不过同时它也提供下列服务:
- 分片,防止数据报大于底层链路层的最大传输单元。
- 一个“TTL”字段,防止循环的包永远循环
- 一种服务类型标签,可用于为某些类型的包提供优先级
- 上层协议标识符,用于将数据包定向到正确的传输层
- 端点的寻址——包括多播来寻址一组接收端——并将数据报路由到正确的目的地
这些服务如何映射到包的 IP 报头的格式呢?如图 2.2 所示。
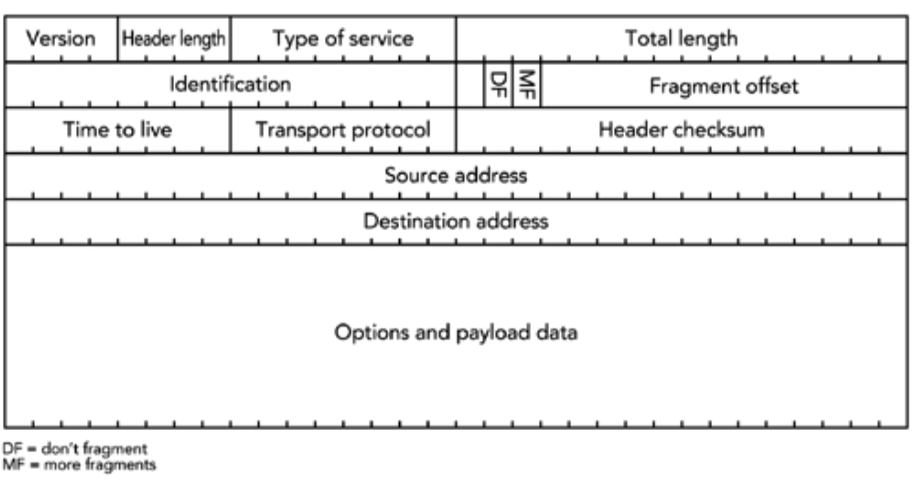
图 2.2 中描绘了当前 Internet 上的标准的 IPv4 标头。目前 IPv4正在向 IPv6 过渡,IPv6 提供了基本相同的功能,但地址空间大大增加 (128bit 地址,而不是 32bit 地址)。如果这种转变发生ーー这是一个长期的前景,因为它涉及到对连接到互联网的每一台主机和路由器的更改ーー它将使更多的机器能够连接,从而促进网络的增长,但它不会以其他方式对服务进行重大改变。
Internet 协议提供了单一网络的抽象,但这并不改变系统的基本性质。尽管互联网看起来是一个单一的网络,但实际上互联网由许多独立的网络组成,通过网关(现在通常称为路由器)连接,并由 IP 的命名服务和地址空间统一起来。图 2.3 显示了单个网络是如何组成更大的互联网的。不同的因特网服务提供商选择如何运行它们自己的全球网络部分:有些拥有高容量的网络,拥有很少的拥塞和高可靠性;有些则没有
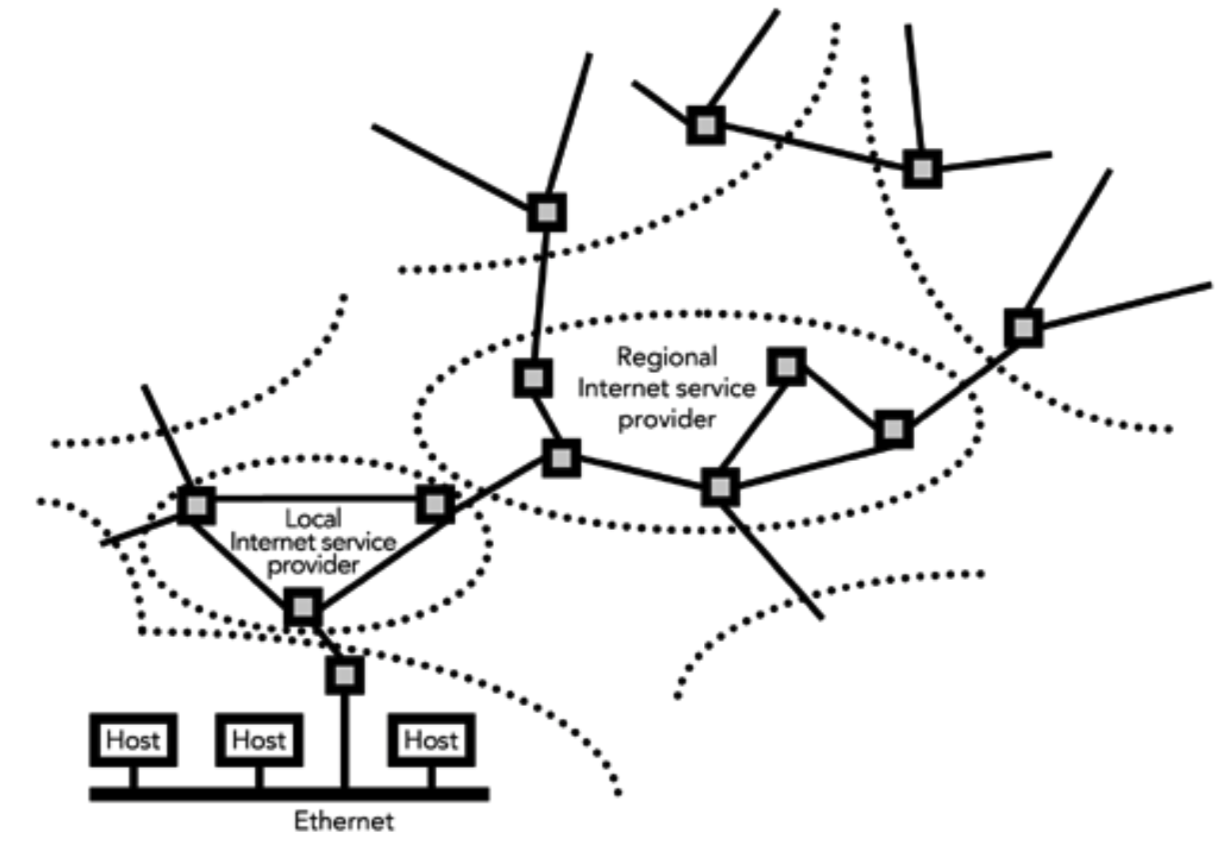
在错综复杂的互联网络中,包含 IP 数据报的数据包被独立路由到各自的目的地。路由器不需要立即发送数据包;如果在发送链路上正在传输另一个包,路由器可以让其短暂地排队。路由器还可能在拥塞时丢弃数据包。如果底层网络发生变化(例如,由于链接失败),IP 包所采取的路由可能会发生变化,这可能导致上层协议可以观察到传输质量的变化。
在 Internet 体系结构中,传输控制协议 (TCP) 和用户数据报协议 (UDP) 是常见的位于 IP 之上的两种传输协议。TCP 对原始 IP 服务进行调整,以便在每个主机上的服务端口之间提供可靠的、有序的传输,并根据网络的特性改变传输速率。UDP 提供与原始 IP 服务类似的服务,只是增加了服务端口。本章后面将更详细地讨论 TCP 和 UDP。
在这些传输协议之上,是 Internet 中常见的会话协议,例如用于 Web 访问的 HTTP 和用于发送电子邮件的 SMTP。堆栈由各种表示层 (HTML、MIME) 和应用本身完成。
从这个讨论中应该清楚的是,IP 在系统中扮演着关键的角色:它提供了一个抽象层,对应用隐藏了底层网络链接和拓扑的细节,并将底层与应用的需求隔离开来。这种体系结构称为沙漏模型,如图 2.4 所示。
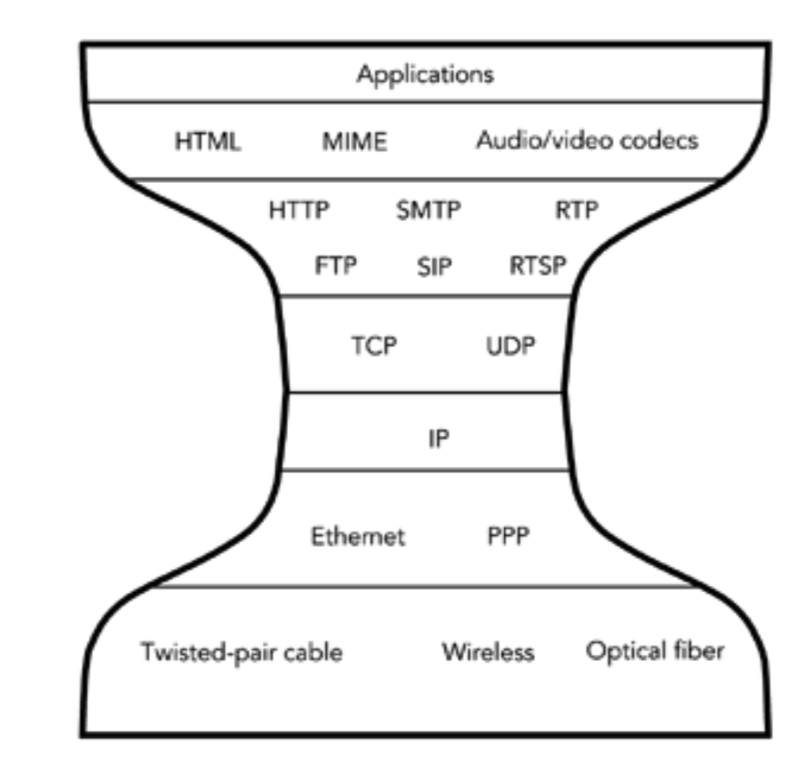
决定跨 Internet 通信系统性能的主要因素是 IP 层。较高层协议可以在一定程度上适应和补偿 IP 层的行为,但若 IP 层性能较差会导致整个系统性能较差。接下来的两个部分将详细讨论 IP 层的性能,指出它的独特特性以及它带来的潜在问题和好处。
IP 网络的性能特征
从 Internet 体系结构的沙漏模型可以明显看出,应用通过抽象隐藏了低层的细节。这意味着应用无法直接确定一个 IP 包所经过的网络类型,从 14.4 kbps的蜂窝无线电连接到kmps的光纤,也不知道该网络的拥塞程度。获取网络性能指标的唯一方法是观察和测量。
那么我们需要测量网络性能那些指标,如何测量呢?幸运的是,IP 层的设计意味着参数的数量是有限的,而且这个数量通常可以根据应用的需要进一步加以限制。我们可以问的最重要的问题是:
- 数据包在网络中丢失的概率是多少?
- 数据包在网络中被破坏的概率是多少?
- 数据包通过网络需要多长时间?传输时间是常数还是变量?
- 可容纳多大的包?
- 我们发送信息包的最大速率是多少?
下一节将介绍关于前四个参数的一些测量样例。最大速率与数据包在网络中丢失的概率密切相关,如第 10 章拥塞控制中讨论的那样。
什么影响这样的测量?最明显的因素是测量站的位置。在局域网上两个系统之间的测量与跨大西洋的测量明显会得到不同的结果!但地理因素并不是唯一的因素;遍历链接的数量(通常称为跃点数量)、经过运营商的数量以及进行度量的时间都是影响测量因素。Internet 是一个大型的、复杂的、动态的系统,因此必须小心确保任何测量都能代表要运行应用的网络。
我们还必须考虑所使用的网络类型、背景流量以及背景流量的大小。到目前为止,绝大多数网络路径是固定的、有线的(铜或光纤)连接,绝大多数流量是基于 TCP 的。这些流量模式的影响如下:
- 由于基础设施主要是有线和固定的,所以链路非常可靠,而损耗主要是由路由器的拥塞造成的。
- TCP 传输假定包丢失是一个信号,表明瓶颈带宽已经达到,拥塞正在发生,应该降低它的发送速率。TCP 流将增加它的发送速率,直到观察到丢失,然后返回,这是一种确定特定连接可以支持最大速率的方法。当然,其结果是瓶颈链接临时超载,这可能会影响其他流量。
如果网络基础设施或流量的组成发生变化,其他丢包来源可能变得重要。例如,无线用户数量的大量增加可能会增加丢包比例,这是由于包损坏和对无线链路的干扰而造成的。在另一个例子中,如果使用 TCP 以外的传输的多媒体流量的比例增加了,而这些传输对丢失的反应与 TCP 不同,那么丢失模式可能会因为拥塞控制动态的变化而改变。
当我们开发在 IP 上运行的新应用时,我们必须意识到我们给网络带来的变化,以确保我们不会给其他用户带来问题。第 10 章,拥塞控制,更详细地讨论了这个问题。
测量 IP 网络性能
本节概述可以度量 IP 网络性能的一些数据,包括平均丢包率、丢包模式、包损坏和重复、传输时间和多播对性能的影响。
有几项研究测量了公共互联网上各种条件下的网络行为。例如,Paxson 报告了 9 个国家 35 个站点之间的 20,000 例传输案例;Handley 和 Bolot 对多播会话行为的研究,Yajnik、Moon、Kurose 和 Towsley 发布了丢包统计中的时间依赖性的发现。其他数据来源包括 CAIDA(互联网数据分析合作协会)、NLANR(应用网络研究国家实验室)和 ACM(计算机械协会)维护的流量档案。
平均丢包
各种丢包相关的度量能够被研究。例如,平均丢包率提供了对网络拥塞的一般度量,而丢包模式和相关性提供了对网络动态的观察。
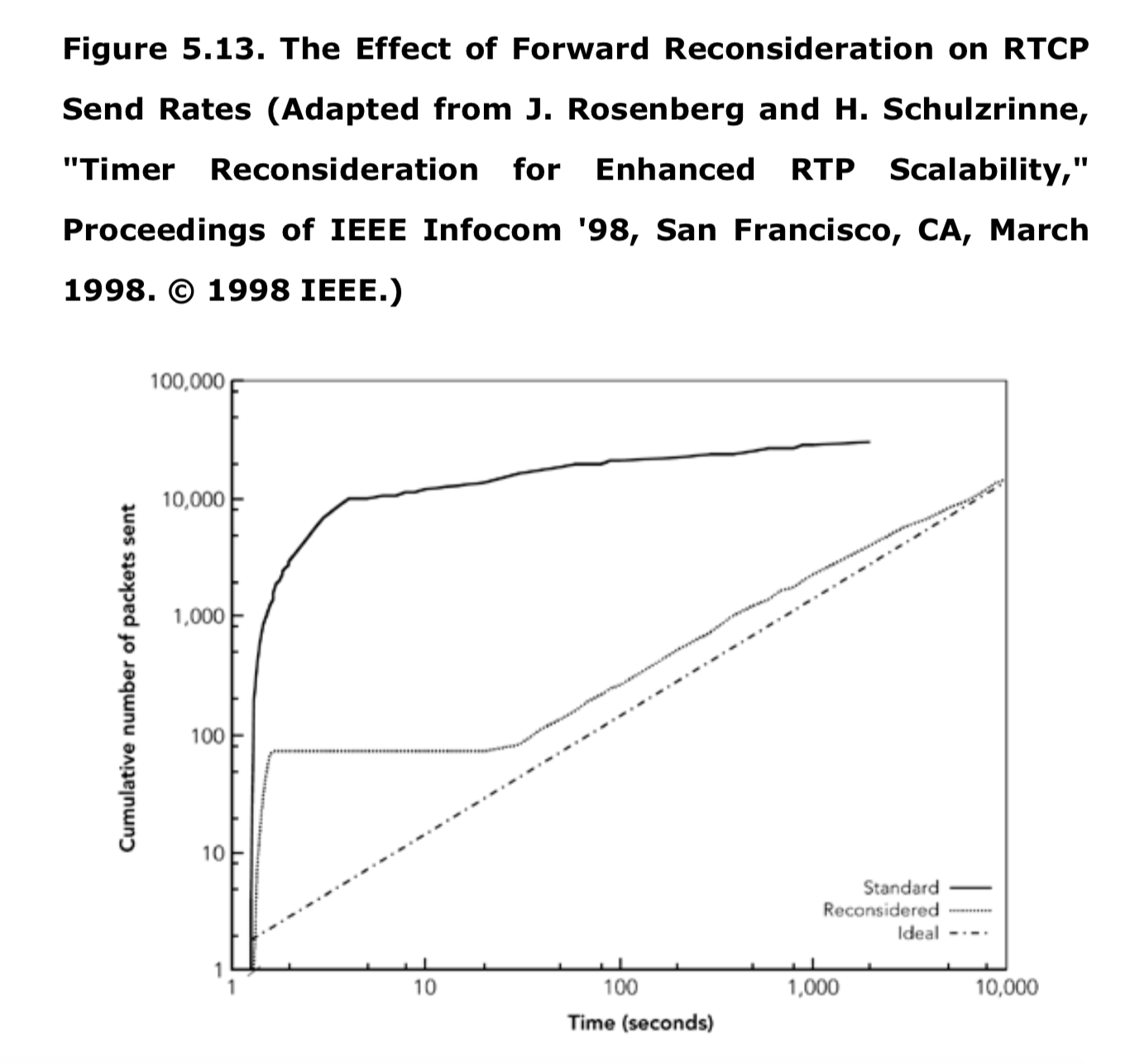
报告的平均丢包率测量显示了一系列情况。例如,由帕克森在 1994 年和 1995 年做的 TCP/IP 流量的测量显示,根据路线和日期,30%到 70%的流量显示没有包丢失,但那些显示有丢包的流量,平均丢包范围从 3%到 17%(这些结果总结在表 2.1)。来自 Bolot 的使用 64kb 的 pcm 编码音频的数据,显示了类似的模式,丢包率在 4%到 16%之间,这取决于一天的时间,尽管这些数据也可以追溯到 1995 年。Yajnik 等人在 1997-1998 年使用模拟音频流量的最新结果显示,丢包率较低,为 1.38%至 11.03%。Handley 的结果——1996 年 5 月和 9 月的两组大约 350 万包数据和多播视频的接收报告统计数据——显示,根据接收位置和时间的不同,每五秒的平均丢包在 0%到 100%之间变化。1996 年 5 月 29 日,一个特定接收端在 10 小时内的样本,如图 2.5 所示,显示了在 5 秒间隔内采样的平均丢失率在 0%到 20%之间变化。
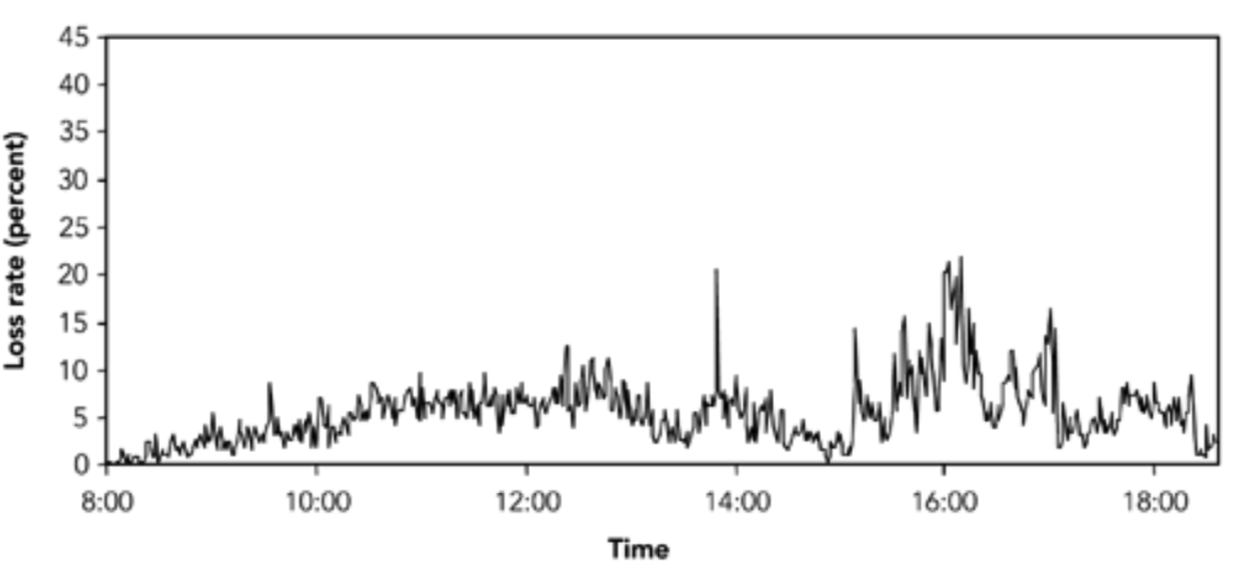
观测到的平均丢包率不一定是恒定的,也不一定是平稳变化的。例子中的丢包率是一个平均丢包率,尽管在某些点上发生了突然的变化,但总体而言,变化相对平稳。来自 Yajnik 等人的另一个示例如图 2.6 所示。这个案例显示了丢包率的一个更显著的变化:在一个小时的过程中,丢包率从 2.5%缓慢下降到 1%,10 分钟后,丢包率上升到 25%,然后恢复正常——这个过程几分钟后重复。
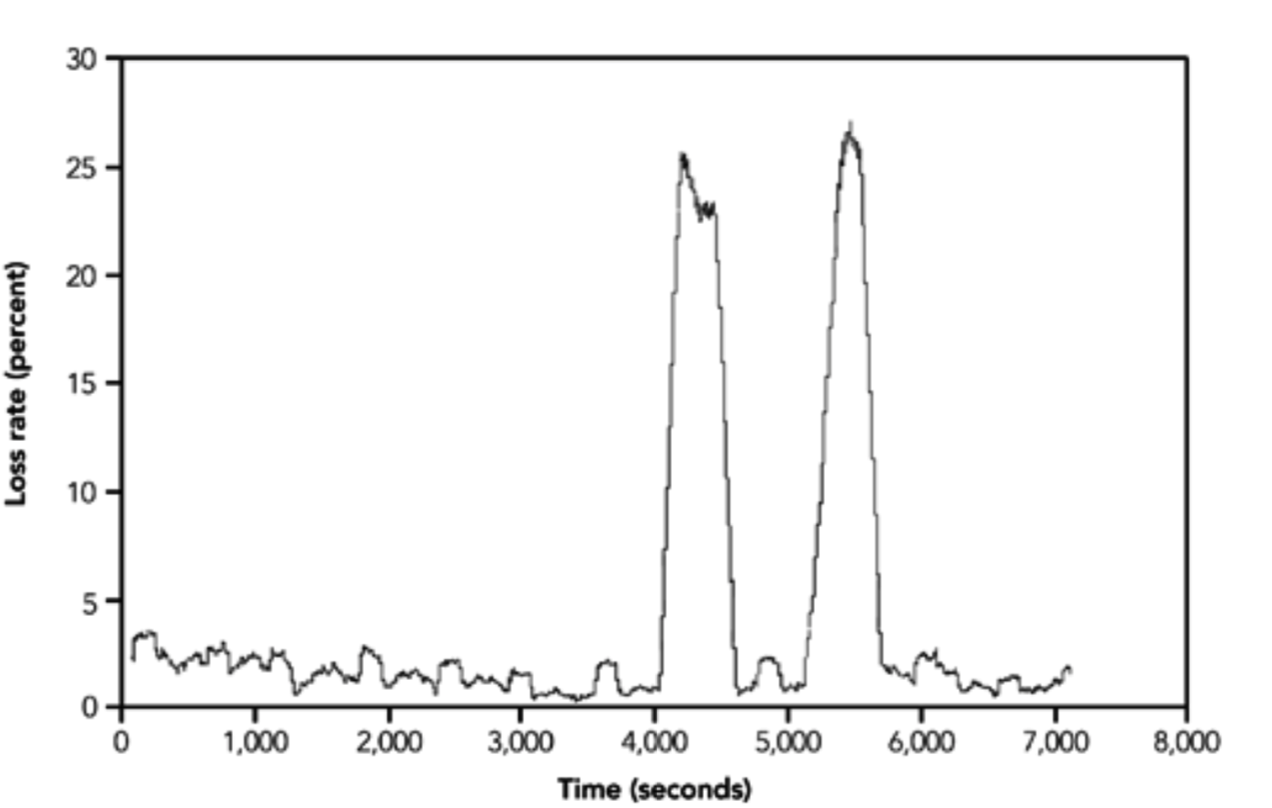
这些丢包率与目前的网络相比如何?在写这篇文章的时候,传统的观点是,可以对网络主干进行设计,这样就不会发生包丢失,所以人们可以期待最近的数据来说明这一点。在某种程度上这是真的;然而,即使有可能使网络的一部分免于丢包,这种可能性并不意味着整个网络将以同样的方式运行。今天,许多网络路径都出现了丢失,即使丢失的只是一小部分数据包。
《互联网天气报告》(Internet Weather Report) 是对互联网上一系列路由的丢包率进行的月度调查。该报告显示,截至 2001 年 5 月,根据 ISP 的不同,美国境内的平均丢包率从 0%到 16%不等。在美国,每月的平均丢包率约为 2%,但就整个互联网而言,平均丢包率略高,约为 3%。
我们可以从中学到什么?答案就是即使网络的一些组成部分已经设计的很好了,但是其他部分也会有很大的丢包。请记住,如表 2.1 所示,美国境内 70%的网络路径在 1995 年没有丢包,而其他网络的平均丢包率差不多是 5%,这个丢包率足以导致音频/视频质量显著下降。
丢包模式
除了研究平均丢包率的变化外,考虑短期的丢包模式也很有意义。如果我们的目标是恢复丢包,那么我们需要了解一个媒体流中丢包是随机分布,还是突发的。
如果丢包在时间上是均匀分布的,那么我们应该期望特定包丢失的概率与前一个包丢失的概率相同。这意味着丢包通常是孤立事件,这是一个理想的结果,因为单个丢包比连续丢包更容易恢复。然而,不幸的是,如果前面的包丢失了,那么与其相关的包丢失的概率通常会增加。也就是说,丢包往往是连续发生的。Vern Paxson 的测量表明,在某些情况下,如果之前的包丢失,其相关的包的丢失概率会增加 5 到 10 倍,这显然意味着丢包不是均匀分布的。
其他一些研究——例如,Bolot 在 1995 年、Handley 和 Yajnik 等人在 1996 年和我在 1999 年收集的测量数据——证实了包丢失概率不是独立的。这些研究表明,在几乎所有情况下,绝大多数丢包不是孤立的,这种情况约占丢包的 90%. 如图 2.7 所示,较长的突发丢包概率降低;很明显,如果丢包是孤立的,较长时间的突发丢包会发生得更频繁。
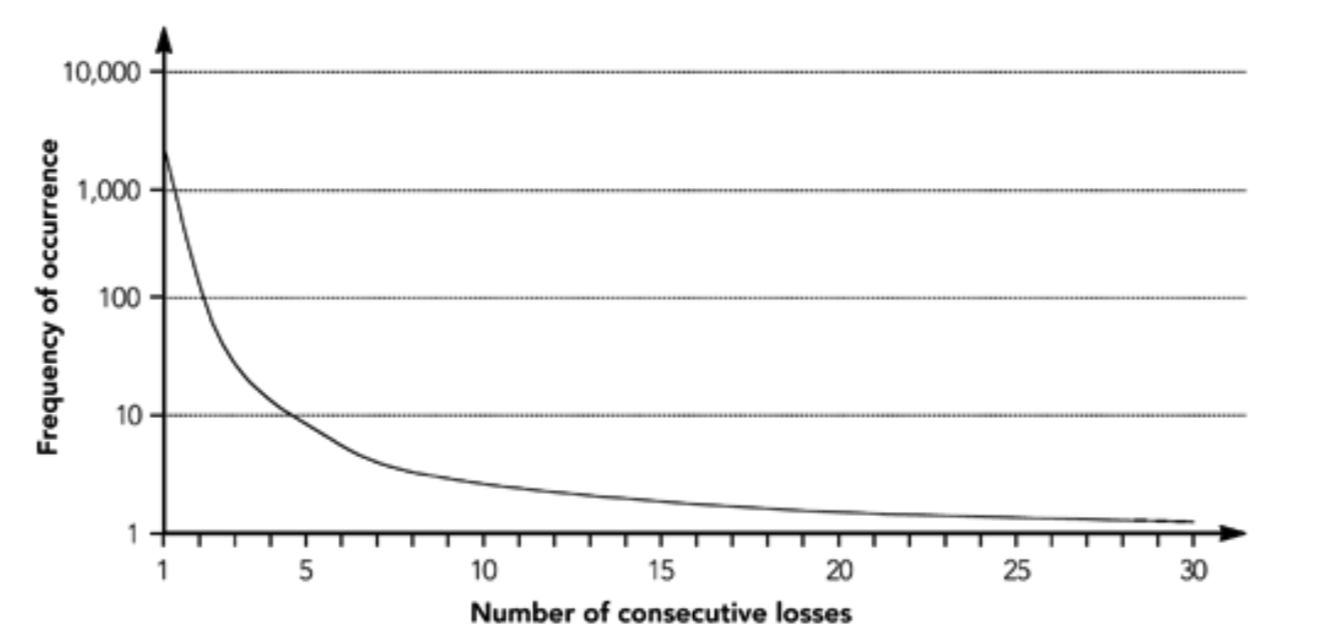
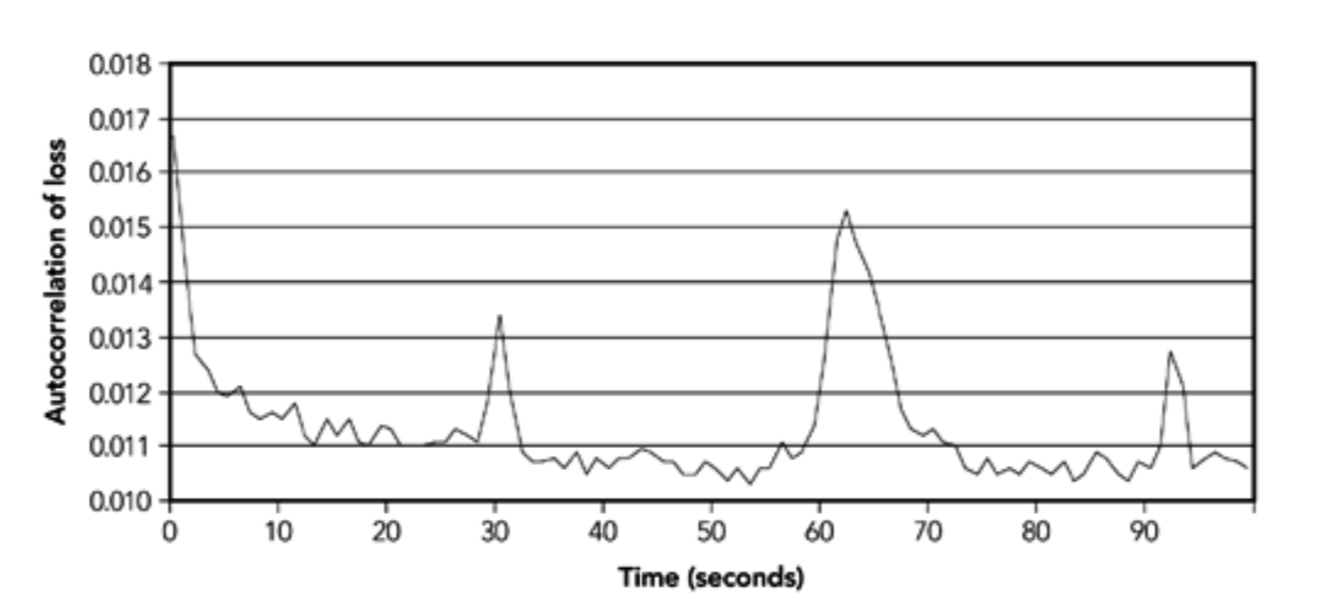
观察到的丢包模式在某些情况下也显示出明显的周期性。例如,Handley 报告说,在 1996 年的测量中,大约每 30 秒就会发生一次突发丢包(见图 2.8),2001 年 4 月也报告了类似的问题。这样的报告并不是普遍的,许多迹象表明没有这样的影响。据推测,周期性是由于某些系统路由更新引起的过载导致的,但这一结论并不确定。
数据包重复
如果数据包在网络中会丢失,那么会出现重复吗?答案是肯定的!数据源发送一个包,而接收端可能获得该包的多个副本。出现重复包,最可能的原因是由于网络中的路由/交换设备出现故障,正常流程不应出现重复。
重复包常见吗?Paxson 的测量结果展示了连续丢包的趋势和少量的包重复。在测量的 20,000 条流中,发现了 66 个重复的包,但他也指出:“我们已经观察到了一些现象,其中超过 10% 的重复包,是由于桥接设备配置不当引起的。”我在 1999 年 8 月进行的跟踪中显示,大约 125 万个包有 131 个重复。
只要开发者知道这个问题的存在,并丢弃重复包,那么不应该触发其他问题。重复包过多会浪费带宽,同时这也表示存在网络配置错误或设备故障。
包损坏
如果数据包可以丢失和重复,那么它也可能会损坏。IP 包包含一个校验码,校验码保护包报头的完整性,但不保护有效负载。虽然如此,链路层也提供了校验码,TCP 和 UDP 都支持整个数据包的校验码。理论上 协议会检测到大部分损坏的数据包,这些损坏的数据包在到达应用层之前会被丢弃。
数据包损坏频率的统计数据很少被报道。Stone 引用了 Paxson 的观察结果,即大约每 7500 个数据包中就有一个未能通过 TCP 或 UDP 校验,而这些没通过校验的包就是损坏的数据。他们还统计了包损坏的概率: 1 /1100 到 1/31900 不等。注意,这个结果是针对有线网络的;无线网络的包损坏特性很可能不一样,因为无线电干扰造成的损坏可能比电线噪音造成的损坏更严重。
当校验失败时,协议层成会认为这个包已经损坏并丢掉它。应用不会收到损坏的数据包 ,所以包损坏会导致丢包率小幅增加。
在某些情况下,应用可能需要接收损坏的包,或者获得包损坏的明确标识。UDP 为这些情况提供了一种禁用校验码的方法。第 8 章《错误隐藏》和第 10 章《拥塞控制》,更详细地讨论了这个主题。
网络传输时间
数据包通过网络需要多长时间?答案取决于所走的路线,虽然短路线比长路线花费的时间要少,但是我们需要注意对“短”的定义。
影响传输时间的因素包括链路的速度、数据包必经路由器数量,以及每跳路由器造成的排队延迟。在物理距离较短的路径中,数据包的跳数可能较长,而每一跳路由器中的排队延迟,通常是整体延迟的主要因素。在网络术语中,短路径通常是跳数最少的路径,即使它覆盖了较长的物理距离。但卫星链路是一个明显的例外,它的距离会带来显著的无线电传播延迟。表 2.2 提供了 2001 年 5 月平均往返时间的量度数据,以供比较。对电话业务的研究表明存在各种往返延迟的,人们不会注意到少于 300 毫秒的延迟。虽然,显然是一个取决于人和任务的主观度量,但关键是所测量的网络往返时间大多在这个阈值。(从伦敦到悉尼是一个例外,但这里的明显增长可能是由于传输路径上有一跳是卫星。)


对延迟的度量本身很无趣,因为它们很显然取决于源和目的地的位置。需要关注的是网络传输时间是如何随着数据包而变化的:对于应用来说,运行在固定传输延迟的网络上比在传输延迟不断变化的网络上更为轻松,尤其是传输延迟敏感的媒体数据。
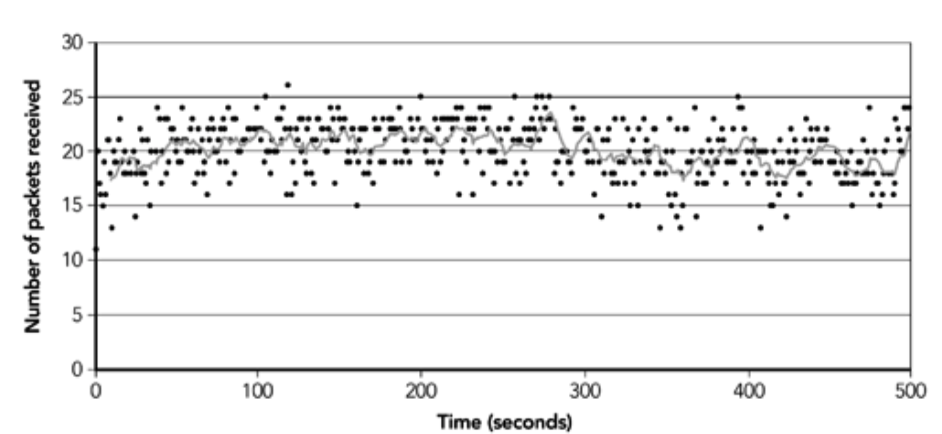
传输时间变化 (jitter) 的粗略度量是包的到达率。例如,图 2.9 显示了以恒定速率发送的流的到达率;很明显,到达率变化很大,这表明网络上的传输时间不是恒定的。
更好的测量方法是通过测量每个包的到达时间和离开时间的差值来求出传输时间,而不是假设速率不变。不幸的是,测量绝对传输时间是困难的,因为它需要源和目的地的时钟精确同步,通常是这很难达到的条件。大多数网络传输时间的追踪都包含时钟偏移,而且除了延迟的变化之外,!!! 不可能研究其他任何东西(因为不可能确定有多少偏移是由未同步时钟造成的,有多少是由网络造成的)。
图 2.10 和图 2.11 给出了传输时间变化的一些测量样本(包含由于时钟不同步造成的偏移)。我是在 1999 年 8 月测量的;Ramjee 等人 (1994 年)和 Moon 等人也提出了类似的测量方法。请注意以下几点:
- 测量值的缓慢向下倾斜是由于源和目标之间的时钟倾斜造成的。一台机器的时钟比另一台的稍微快一点,导致感知到传输时间逐渐改变。
- 可以观察到平均传输时间的几个较大的改变,这可能是由于网络中的路由改变所致。
- 传输时间不是常数;相反,它在整个过程中会有显著的变化。

这些都是应用或更高层协议必须处理的问题,如果有需要的话,必须要纠正这种偏差。
在网络中对数据包重排序也是可能发生的。例如,当路由发生了更改并且新路由更短时。Paxon 观察到,总共有 2%的 TCP 数据包是无序传输的,但是在不同的追踪之间,无序传输数据包的比例有很大的差异,其中一条追踪显示 15%的数据包是无序传输的。
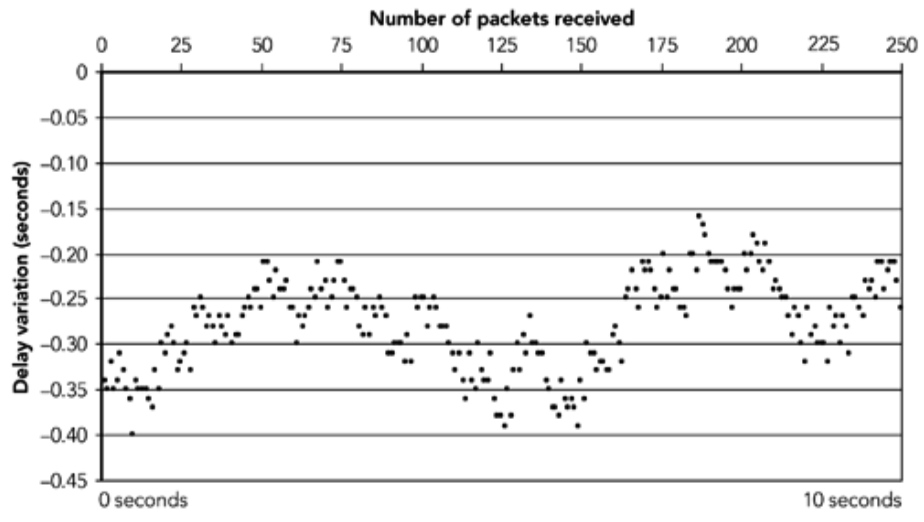
网络传输时间中的“峰值”是另一个可以被观察到的特征,如图 2.12 所示。目前还不清楚这些峰值是由于网络内的缓冲还是由于发送系统中的缓冲,但是如果试图平滑数据包的到达时间,那么这些”峰值“也是值得解决的问题。

最后,网络传输时间可以显示周期性,尽管这似乎是一种次要的影响。我们期望这种周期性与前面提到的丢包周期性有相似的原因,除非这些事件不那么严重,只导致路由器中的队列堆积,而不是队列溢出导致丢包。
合适的数据包大小
IP 层数据包长度度不是固定的, 如链路层的最大传输单元 (MTU) 不加限制,最多可达 65,535 字节。MTU 是链路可以容纳的最大数据包的大小。通常是 1500 字节,这是以太网可以传输的最大数据包。很多应用默认一个包的最大 1500字节,但是一些链路的 MTU 是低于 1500字节的。例如,拨号调制解调器链接的 MTU 普遍为 576 字节。
在大多数情况下,瓶颈在发送端或接收端附近。几乎所有的骨干网 MTU 都是 1500 字节或更多的 。
IPv4 支持数据分段,当一个数据包大小超过一个链路的 MTU 时,就会被分割成更小的片段。然而,这个通常不是好办法,因为任何一个片段的丢失都将使接收端不能重组原始的数据包。由此产生的丢包乘数效应是我们希望避免的。
几乎所有情况下,音频包大小都落在网络一个 MTU 内。对于更大的视频帧,应用需要分包传输,让每个包都适配所在网络的 MTU。
多播的影响
IP 多播允许发送端同时向多个接收端传输数据。它有一个有用的特性,即网络根据需要创建包的副本,这样只需要一个包的副本对应的一个链接。IP 多播提供了非常高效的组通信,前提是网络支持它,这使得向一组接收端发送数据的成本与该组的大小无关。
支持多播是 IP 网络的一个可选的、相对较新的特性。在撰写本文时,它比较广泛地部署在研究和教育环境以及网络主干中,但在许多商业环境和服务提供商中并不常见。
发送到一个组意味着更大的可能出错:接收质量不再受到通过网络的单一路径的影响,而是受到从源到每个单独接收端的路径的影响。在测量组播会话的损耗和延迟特性时,定义因素是均匀性。图 2.13 演示了这个概念,显示了我测量的多播会话中每个接收端的平均丢包率。
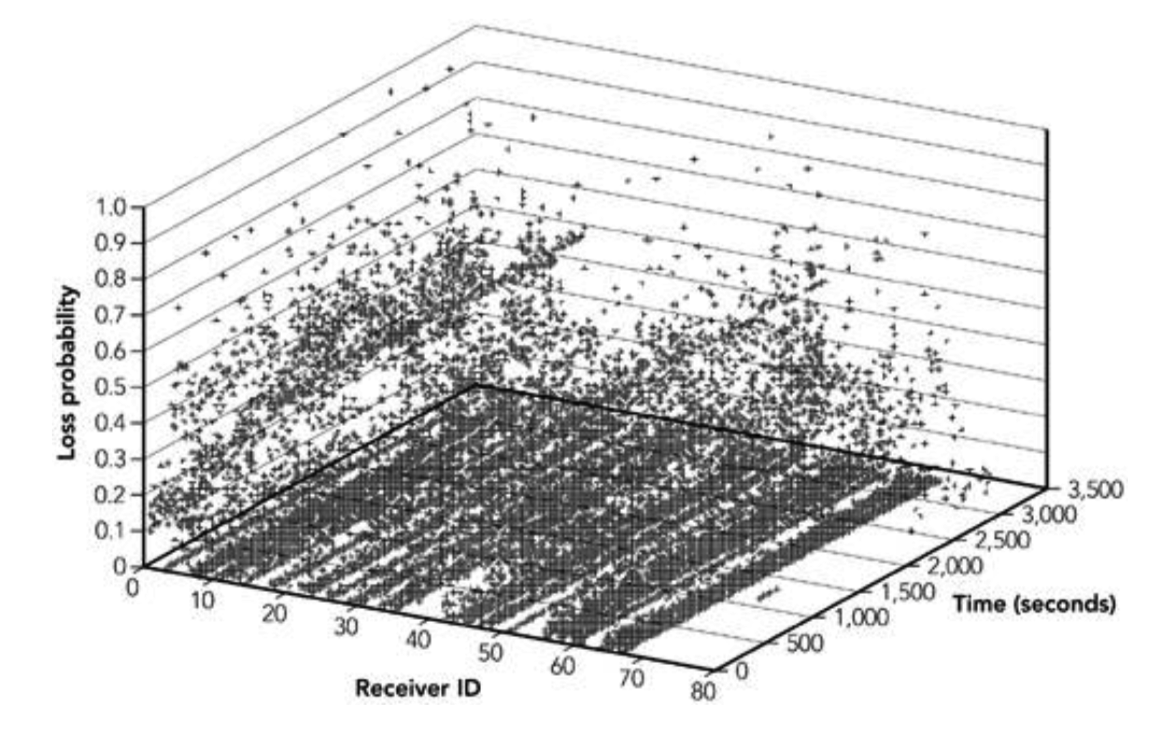
多播不会改变网络中丢失或延迟的根本原因。相反,它使每个接收端都能经历这些影响,而源只传输每个包的一个副本。网络的异构性使得源很难满足所有的接收端:有些发送太快,有些发送太慢是很常见的。我们将在后面的章节中进一步讨论这些问题。现在,只需注意多点传送为系统增加了更多的异构性就足够了。
网络技术的影响
!!!到目前为止提出的测量方法是公共的、大范围的。应用大多将在这种环境中运行,但还有大量应用部署在私有内部网、无线网络或支持增强服务质量的网络。这些情况如何影响 IP 层的性能?
许多私有 IP 网络(通常称为内部网)具有与公共互联网非常相似的特性:流量组合通常非常相似,许多内部网覆盖范围很广,链接速度和拥塞程度各不相同。在这种情况下,测试结果很可能与公共互联网上的测试结果相似。然而,如果网络是专门为实时多媒体流量而设计的,就有可能避免许多已经讨论过的问题,并构建一个没有丢包和最小抖动的 IP 网络。
一些网络使用集成服务/RSVP 或差异化服务来支持增强的服务质量 (QoS)。使用增强的 QoS 可以减少应用对丢包和/或抖动恢复的需求,因为它为满足某些性能限制提供了强有力的保证。然而,请注意,在许多情况下,QoS 方案提供的保证本质上是统计意义的,通常它不能完全消除数据包丢失,或者传输时间的变化。
在无线网络中可以观察到显著的性能差异。例如,蜂窝网络可以在短时间内表现出显著的性能变化,包括非阻塞丢包、突发丢包和高误码率。另外,一些蜂窝系统具有高延迟,因为它们在数据链路层使用交织来隐藏突发的丢包或包损坏。
不同网络技术的主要影响是增加了网络的异构性。如果你正在设计一个应用来处理这些技术的一个有限子集,那么你可以利用底层网络的功能来提高应用所看到的连接的质量。在其他情况下,底层网络可能会给健壮应用的设计者带来额外的挑战。
明智的应用开发人员会选择健壮的设计,这样当应用从最初设想的网络转移到新网络时,它仍然可以正确地运行。设计可在 IP 上运行的音视频应用的挑战是使它们在面对网络问题和意外情况时仍旧可靠。
关于测量特性的结论
测量、预测和建模网络行为是有许多微妙之处的复杂的问题。这一讨论只涉及这些问题,但一些重要的结论是显而易见的。
第一点,网络可以而且经常表现得很糟糕。如果一个工程师设计了一个应用,他希望所有的包都能及时到达,那么当这个应用被部署到 Internet 上时,他一定会大吃一惊。虽然更高层的协议(如 tcp) 可以隐藏一些这种缺点,但总有一些方面对应用是可见的。
另一个需要认识的要点是网络中的异构性。网络中某一点的测量结果不能代表另一点的情况,甚至“不寻常”的事件也一直在发生。到 2000 年底,网络上大约有 1 亿个系统,因此,即使发生在不到 1%的主机上的事件也会影响成千上万台机器。作为应用设计人员,你需要了解这种异构性及其可能的影响。
尽管存在这种异构性,试图总结丢包和丢包模式的讨论揭示了几个“典型”特征:
- 虽然有些网络路径可能不会丢包,但这些路径在公共网络中并不常见。一个应用应该被设计来处理少量的数据包丢失——比如说,达到 5%。
- 孤立的丢包组成了大多数观察到的丢包事件。
- 丢包的概率不是均匀的:即使大多数丢包是孤立的包,连续丢包的突发概率也比随机事件更常见。丢包的突发通常是短暂的;一个应用,处理两到三个连续丢失的包将足以满足大多数突发丢包。
- 很少出现长时间的突发丢包。一秒甚至更长的故障时间并不是未知的。
- 包重复很少见,但也可能发生。
- 类似地,在极少数情况下,数据包可能被破坏。其中绝大多数是由 TCP 或 UDP 校验码(如果启用)检测到的,包在到达应用之前会被丢弃。
传输时间变化的特征可以总结如下:
- 网络上的传输时间不是均匀的,而且会观察到抖动。
- 绝大多数抖动是合理有界的,但分布的长尾效应比较明显。
- 虽然重新排序相对较少,但在传输过程中可能会重新排序数据包。应用不应该假定接收数据包的顺序与发送数据包的顺序一致。
这些并不是通用的规则,每一个规则都会有一个网络路径作为反例。然而,它们确实提供了一些我们在设计高层协议和应用时需要注意的一些概念。
传输协议的影响
到目前为止,我们对网络特性的考虑主要集中在 TCP/IP 上。当然,程序员几乎从不使用原始 IP 服务。相反,它们在较高层传输协议(通常是 UDP 或 TCP) 的基础上构建应用。这些协议提供了 IP 协议之外的其他特性。这些添加的特性如何影响应用所看到的网络行为?
UDP/IP
用户数据报协议 (UDP) 提供了一组最小的 IP 扩展。UDP 报头如图 2.14 所示。它包含 64 位附加头,代表源和目标端口标识符、长度和校验码。

源端口和目标端口标识了通信主机内的端点,允许将不同的服务复用到不同的端口上,一些服务使用知名端口上;另一些则使用在调用时动态协商的端口长度字段与IP头中的长度字段冗余。校验和用于检测有效载荷的损坏,是可选的(对于不需要校验和的应用程序,它被设置为零)。
除了增加端口和校验和外,UDP 还提供原始的 IP 服务。它没有增强传输的可靠性(尽管校验码可以检测到 IP 没有检测到的负载错误),也不影响包传输的时间。使用 UDP 的应用向传输层提供数据包,传输层将数据包发送到目标机器上的一个端口(如果使用多播,则发送到一组机器)。这些包可能在传输过程中丢失、延迟或乱序,这与原始 IP 服务的情况完全相同。
TCP/IP
Internet 上最常用的传输协议是 TCP。虽然 UDP 只向 IP 服务提供了一小部分附加功能,但 TCP 添加了大量附加功能:它抽象了不可靠的 IP 包传递服务,从而在源端口和单个目标主机之间提供可靠的、连续的字节流传输。
使用 TCP 的应用向传输层提供一个数据流,传输层将其分割成适当大小的数据包,并以适合网络的速率进行传输。数据包由接收端确认,在传输过程中丢失的数据包由源重新传输。当数据到达时,在接收端进行缓冲,以便按顺序传递。这个过程对应用是透明的,应用只看到一个数据流经网络的“管道”。
只要应用提供足够的数据,TCP 传输层就会增加它的发送速率,直到网络出现数据包丢失。丢包视为已超过瓶颈链路带宽的信号,该连接应降低其发送速率以匹配。相应地,TCP 降低了丢包发生时的发送速率。这个过程会继续下去,TCP 会不断探测整个网络的传输速率;结果是一个如图 2.15 所示的发送速率。

这种重新传输、缓冲和探测可用带宽的组合有以下几个效果:
- TCP 传输是可靠的,如果连接保持打开,所有数据最终都将被传递。如果连接失败,则通知连接端失败。这与 UDP 形成了对比,UDP 不向发送端提供关于数据传输状态的信息。
- 应用对包传输的时间几乎没有控制,因为在源发送数据的时间和接收数据的时间之间没有必然的关系。这种变化与原始 IP 服务显示的传输时间变化不同,因为 TCP 层还必须考虑重新传输和发送速率的变化。发送端可以知道是否所有数据都已发送,这可能使它能够估计平均传输速率。
- 带宽探测可能导致瓶颈链路的短期过载,从而导致数据包丢失。当这种重载导致 TCP 流的丢失,该流将降低其速率;但是这个过程中它也可能给其他流造成损失。
当然,TCP 的行为也有一些微妙之处,关于这个主题已经写了很多。还有一些特性是本讨论还没有涉及到的,比如推送模式和紧急交付,但是这些特性并不影响基本行为。对于我们的目的来说,重要的是注意 TCP 和 UDP 之间的根本区别:可靠性 (TCP) 和实时性 (UDP) 之间的权衡。
分组网络中音频/视频传输的条件
到目前为止,本章已经详细地探讨了 IP 网络的特性,并简要地研究了位于它们之上的传输协议的行为。我们现在可以将此讨论与实时音视频传输联系起来,考虑通过 IP 网络传输媒体流的需求,并确定网络在多大程度上能满足这些需求。
当我们将媒体描述为实时的时候,简单讲就是接收端在接收到媒体流时就播放它,而不是简单地将完整的媒体流存储在一个文件中以供以后回放。在理想的情况下,在接收端的播放是即时和同步的,尽管在实践中网络会造成一些不可避免的传输延迟。
实时媒体对传输协议的主要条件是网络传输时间的可预测变化。例如,考虑一个以 20 毫秒帧传输编码语音的 IP 电话系统:源将每 20 毫秒传输一个数据包,理想情况下,我们希望这些数据包以相同的间隔到达,这样它们包含的语音可以立即播放出来。传输时间的一些变化可以通过在接收端插入额外的延迟缓冲来调节,但是这只有在变化可以被描述并且接收端能够适应变化的情况下才有可能实现(这个过程在第 6 章《媒体采集、播放和时序》中有详细的描述)。
一个较低的条件是通过网络可靠地传递所有数据包。显然,可靠的传输是我们期待的,但许多音频和视频应用可以容忍一些丢包:在我们的 VOIP 示例中,单个数据包的丢失将导致 1 / 50 秒的语音丢失,如果采用适当的错误隐藏方法,则人们几乎无法察觉。由于媒体流的时变特性,一些丢包通常是可以接受的,因为它的影响会随着新数据的到来而迅速得到纠正。可接受的丢包数量取决于应用、使用的编码方法和丢包模式。第 8 章《错误隐藏》,和第 9 章《错误恢复》,讨论丢包容错。
上面这些基本需求会帮我们做出选择。很明显,TCP 是不合适的,因为它更看重可靠性而不是实时性,而且我们的应用需要实时交付。在网络的传输延迟变化可以被量化且丢包率是可以接受的前提下,UDP/IP 应该是合适的。
标准实时传输协议 (RTP) 建立在 UDP/IP 上,提供实时的恢复和丢包检测,以支持健壮系统的开发。RTP 和相关标准将在本书的其余部分详细讨论。
尽管 TCP 对实时应用有限制,但一些音频/视频应用将其用于传输。这样的应用尝试估计 TCP 连接的平均吞吐量,并调整它们的发送速率以匹配。当没有严格的端到端延迟限制,并且应用有几秒钟的缓冲时间来处理由 TCP 重传和拥塞控制引起的传输时间变化时,可以使用这种方法。它对于需要端到端低延迟的交互式应用不可靠,因为 TCP 引起的传输时间变化太大。
使用 TCP/IP 传输的主要理由是许多防火墙传递 TCP 连接,但阻塞 UDP。随着基于 RTP 的系统变得更加流行,防火墙变得更加智能,这种情况正在迅速改变。我强烈建议新的应用基于 UDP/IP 的 RTP。RTP 可以通过允许应用调整以适应实时媒体的方式和通过促进互操作性(因为它是开放标准),来提供更高的质量。
基于分组的音频/视频的好处
在这个阶段,你可能想知道为什么有人会考虑 IP 网络上的基于分组的音频或视频应用。这样的网络显然对实时媒体流的可靠传输提出了挑战。尽管这些挑战是真实存在的,但 IP 网络具有一些独特的优势,可以在效率和灵活性方面获得显著的收益,这可能会超过其缺点。
使用 IP 作为实时音频和视频承载服务的主要优点是,它可以提供一个统一的、聚合的网络。这个网络可以用于语音、音乐和视频,也可以用于电子邮件、Web 访问、文件和文档传输、游戏等等。因此可以显著节省在基础设施、部署、支持和管理方面的成本。
统一的分组网络使流量的统计和复用成为可能。例如,语音活动检测可用于防止分组语音应用在静默期间进行传输,而使用 TCP/IP 作为其传输的流量将适应可用容量的变化。只要谨慎地设计音频和视频应用,减少负面影响。因此,我们可以实现更高的链路利用率,这在资源有限的系统中是很重要的。
另一个重要的好处是 IP 多播,它允许将数据低成本的传递给可能很大的一组接收端。传送的成本不受受众量的影响,IP 多播使人们能够负担得起 Internet 广播和电视以及其他组通信服务。
最后,也许是最引人注目的,基于 IP 的音视频的情况下,IP 支持新的服务。这种融合允许实时音视频和其他应用之间进行丰富的交互,使我们能够开发以前不可能开发的系统。
总结
IP 网络的特性与传统的电话、音视频分发网络有很大的不同。在设计基于 IP 的应用时,你需要了解这些独特的特性,以使你的系统在这些特性的影响下仍旧保持健壮性。
本书的其余部分将描述这种系统的体系结构,解释 RTP 及其模型,这个模型用于时间戳恢复和音视频同步、错误纠正和隐藏、拥塞控制、报头压缩、多路复用和隧道以及安全性。
第三章 实时传输协议
- RTP 的基本设计理念
- RTP 的标准元素
- 相关标准
- 未来标准的开发
本章我们从设计的理念和背景出发,描述 RTP 协议的整体设计思路。并大致介绍RTP标准协议适用的场景和协议是如何适配这些场景的,最后发散的讨论了RTP协议今后的发展方向。
RTP 的基本设计理念
在不可靠的传输层之上构建健壮的实时的媒体传输机制是RTP协议的设计者们面对的最大挑战。在兼顾了应用框架设计和端到端传输设计原则与规范的同时, 协议设计者们很好的完成了这个任务。
应用级框架
Clark 和 Tennenhouse 在 1990 年首次提出应用级框架思想,应用级框架的中心观点是:应用想作出正确数据传输决策,必须对数据有足够的了解。这意味着传输协议应该理解数据中的元素,而且传输层需要尽可能向应用层公开传输细节,以便应用在出现传输异常时能够做出适当的决策。应用层与传输层合作,共同实现可靠的传输。
应用级框架的源起是基于这样一种认识:应用程序可以通过多种方式从网络异常中恢复,具体的方法取决于具体的场景。举例来说,在某些情况下,我们可能需要重新传输丢失的数据包的精确副本。而在其他情况下,我们可能会选择使用质量较低的副本。另外,对于那些具有高时效性要求的数据,我们可以忽略丢失的数据包。只有在应用层与传输层紧密配合的情况下,我们才能做出恰当的决策。
应用级框架与TCP的设计思路在一些方面存在差异。TCP 的设计隐藏了底层 IP 网络的有损特性,牺牲时效性来实现可靠的传输。但是,应用级框架非常适合基于 UDP 的传输和实时媒体的特性。如第二章所述,分组网络上的实时音视频通信通常是能够容错的,但是实时性要求高。使用基于 UDP 传输的应用级框架,我们可以在必要时接受丢包,也可以灵活地使用端到端的恢复技术,如在适当的情况下重传和错误隐藏(PLC)。
这些恢复技术为应用提供了极大的灵活性,使其能够以适当的方式对网络异常作出处理,而不单一的受传输层的约束。
根据应用级框架的原则,设计的网络传输协议不应该针对特定的应用。相反,它应该暴露通用传输层的限制,以便应用程序能够与网络协同工作,实现尽可能最佳的传输。应用级框架意味着对OSI参考模型中严格的层次划分进行了弱化。这是一种实用的做法,既承认了层次划分的重要性,也根据实际需求暴露了底层的一些细节。
应用级框架的设计哲学就是对网络异常作出快速且正确的响应。
端到端原则
端到端原则是设计可靠网络通信系统的两种方法之一:
- 系统把正确交付数据的责任连同该数据一起传递,逐跳保证可靠性。
- 可靠传输的责任由端点负责。即使各跳不可靠,也可以由端点确保端到端的可靠性。
Internet 设计的采用了端到端保障方法,TCP 和 RTP 都遵循端到端原则。
如果使用端到端的方法,数据流逐级向上,直到协议栈的顶部。路径上的节点不负责数据保护,那么协议的实现就会简单化,而且没有健壮性的要求。 如果丢弃了无法传输的数据,在没有中间节点的帮助下,端点也有能力恢复。端到端原则意味着信息是在端点上,而不是在网络中。
其结果是一个包含智能感知网络端点和哑网络(不智能的网络)的设计。这种设计非常适合 Internet(可能是最基本的哑网络), 但是需要应用设计人员进行大量的工作。它的设计也不同于其他许多网络。以传统的电话网为例,它采用了智能网络和哑端点的模型,而 MPEG 传输模型允许哑接收端和智能发送端。这种设计上的差异改变了应用的风格,更加强调接收端的设计,使发送端和接收端在传输中更加平等。
实现灵活性
RTP协议在许多场景下可以满足需求,几乎不需要额外的协议支持。这种设计在很大程度上基于视频会议的轻量级会话模型。在这种场景中,RTCP协议提供了所有必要的会话管理功能,包括IP地址和媒体类型的映射(从媒体定义到RTP有效负载类型标识符)。这个模型也适用于一对多的场景,比如网络广播。RTCP提供的反馈信息可以给信息源提供有关观众规模和接收质量的评估。
有些人认为,在单播语音通话方面,RTP提供了多余的功能,特别是对于高度压缩的语音帧而言,这些功能是冗余且低效的。此外,RTP所提供的特性可以轻松扩展到多媒体多方会话。然而,还有一些人(例如数字电影社区)认为RTP没有充分满足他们的需求,他们认为应该包括更强大的QoS和安全支持,以及更详细的统计数据等功能。
RTP的优点在于提供了一个统一的实时音频/视频传输框架,可以满足大多数应用的需求。然而,对于那些超出其限制的应用来说,RTP是具有灵活性的。
RTP 的标准元素
IP 网络中音频/视频传输的主要标准是实时传输协议 (RTP),以及相关的 Profile 和有效负载格式。RTP 是由互联网工程任务组 (IETF) 的音频/视频传输工作组开发的,它已经被国际电信联盟 (ITU) 作为其 H.323 系列提案的一部分,并被其他几个标准组织采用。
RTP 为实时媒体的传输提供了一个框架,在完成之前对 RTP 的特定用途进行概要说明。音频和视频会议的最小控制 RTP Profile 与 RTP 一起被标准化,另外一些 Profile 正在开发中。每个 Profile 都附有几个有效载荷格式规范,每个规范描述了特定媒体格式的传输
RTP 规范
RTP 于 1996 年 1 月 6 日作为 IETF 拟议标准 (RFC1889) 发布,其标准草案的修订已基本完成。国际电联提案 H.323 的第一次修订就包括了 RTP 规范的副本;后来的修订参考了当前的 IETF 标准。
在 IETF 标准化过程中,规范经历了一个开发周期,在此期间,随着设计细节的确定,将生成多个互联网草案。当设计完成时,它作为一个提案的标准 RFC 发布。提案的标准通常被认为是稳定的,解决了所有已知的设计问题,适合实现。如果该标准被证明是有用的,并且该标准的每个特性都有独立的、可互操作的实现,那么它就可以被提升到标准草案的状态(可能包括修改以纠正在该标准中发现的任何问题)。最后,经过广泛的经验,它可以作为一个完整的标准 RFC 发布。超出所提议的标准状态的改进是造成许多协议从未实现的主要障碍。
RTP 一般运行在 UDP/IP 上,通过丢包检测和接收质量报告、时序恢复和同步、有效负载和源标识以及媒体流中重要事件的标记来增强传输。 RTP 的大多数实现是应用或库的一部分,该应用或库位于操作系统提供的 UDP/IP 套接字接口之上。 但是,这不是唯一可能的设计,且 RTP 协议中的任何内容都涉及 UDP 或 IP。 例如,某些实现基于 TCP/IP 之上的 RTP,而其他实现甚至在非 IP 网络(例如异步传输模式(Asynchronous Transfer Mode,ATM)网络)上使用 RTP。
RTP 包括两部分:数据传输协议和相关的控制协议。RTP 数据传输协议管理终端系统之间的实时数据传输,如音频和视频。RTP 为媒体有效负载定义了帧级别之外的字段,包括用于丢包检测的序列号、用于恢复时序的时间戳、有效负载类型和源标识符,以及媒体流中重要事件的标记等字段。RTP还指定了生成时间戳和序列号的规则,尽管这些规则在某种程度上依赖于使用的配置文件和有效负载格式,以及在一个会话中多路复用的流的路数。第四章进一步讨论了 RTP 数据传输协议。
RTP 控制协议 (RTCP) 提供接收质量反馈、参与者识别和媒体流之间的同步所需信息。RTCP 与 RTP 一起运行,并定期报告这些信息。虽然数据包通常每隔几毫秒发送一次,但控制协议以秒为单位进行操作。RTCP 中发送的信息对于媒体流之间的同步是必要的——例如,对于音频和视频之间的同步,并且可以根据接收质量反馈调整传输和识别参与者。第五章进一步讨论了 RTP 控制协议。
RTP支持mixer和translator的概念,这些中间件可以在媒体源和接收终端之间处理媒体流 。它们可以用于在不同的底层协议之间转换RTP会话,例如在IPv4和IPv6网络上进行参与者之间的桥接,或将仅支持单播的参与者加入到组播组中。它们还可以以某种方式调整媒体流,例如将数据格式转码以减少带宽,或者将多个流混合在一起。
很难将 RTP 放在 OSI 的参考模型中。RTP执行许多通常属于传输层协议的任务,但RTP本身并不构成一个完整的传输层。RTP 还执行会话层(跨越不同的传输连接并以与传输无关的方式管理参与者标识)和表示层(为媒体数据定义标准表示)的一些任务。
RTP Profile
了解 RTP 协议规范的限制非常重要,因为它在两方面刻意不完整。首先,该标准没有指定用于媒体播放和时序、媒体流之间的同步、错误隐藏和纠正或拥塞控制的算法。这完全是应用设计人员的职责范围,因为不同的应用有不同的需求,所以如果标准要求使用单一的行为,那就太愚蠢了。当然,它确实为这些算法提供了必要的信息,以供它们实现。后面的章节将讨论应用设计和提供这些特性必要性的权衡。
其次,传输的一些细节可以通过配置文件和有效负载格式定义进行修改。这些特性包括时间戳的解析、媒体流中感兴趣事件的标记和有效负载类型字段的使用。可以通过 RTP 配置文件指定的功能包括:
- RTP 报头中的有效负载类型标识符与有效负载格式规范之间的映射(有效负载格式规范描述了如何在 RTP 中使用单个媒体编解码器)。每个配置文件将引用多个有效负载格式并可能指示如何使用特定的信令协议(例如 SDP) 来描述映射。
- RTP 报头中的有效负载类型标识符字段的大小,以及用于标记媒体流中感兴趣的事件的位数。
- 固定的 RTP 数据传输协议报头的补充部分,如果该报头被证明不足以用于特定的应用类。
- RTP 控制协议的报告间隔——例如,以牺牲额外的开销为代价使反馈更及时。
- 如果 RTCP 所提供的某些信息对应用没有用处,则对所使用的 RTCP 包类型进行限制。此外,配置文件可以定义 RTCP 的扩展以报告额外信息。
- 附加的安全机制——例如,新的加密和认证算法。
- 将 RTP 和 RTCP 映射到底层传输协议。
在撰写本文时,只有一个 RTP Profile: 用于音频和视频会议的 RTP Profile,只有很少的控制。这个配置文件在 1996 年 1 月作为一个标准的提按 (RFC 1890) 和 RTP 规范一起发布,当时其标准状态草案的修订几乎已经完成。一些新的 Profile 正在开发中。安全性的配置文件,以及反馈和修复机制,这些内容可能很快就会提供。
RTP 有效负载格式
RTP 框架的最后一部分是有效负载格式,它定义了在 RTP 中如何传输特定的媒体类型。有效负载格式由 RTP 配置文件定义,它们还可以定义 RTP 数据传输协议的其他某些属性。
尽管配置文件可以为有效负载格式指定一些常规行为,但RTP有效负载格式和配置文件之间的关系主要是一个名称空间。名称空间将RTP包中的有效负载类型标识符与有效负载格式规范联系起来,从而允许应用将数据与特定的媒体编解码器关联起来。在某些情况下,有效负载类型和有效负载格式之间的映射是静态的;在其他情况下,映射是通过带外控制协议进行动态的。例如,具有最小控制的音频和视频会议的RTP配置文件定义了一组静态负载类型分配,并提供了一种机制用于将标识负载格式的MIME类型与使用会话描述协议(SDP)的负载类型标识进行映射。
有效负载格式和 RTP 数据传输协议之间的关系是双重的:有效负载格式将指定某些 RTP 头字段的使用,并且可以定义附加的有效负载头。媒体编解码器产生的输出被转换成一系列的 RTP 数据包—一些部分映射到 RTP 报头,一些映射到有效负载报头,大部分映射到有效负载数据。这种映射过程的复杂性取决于编解码器的设计和所需的错误恢复程度。在某些情况下,映射很简单;而另一些情况则更为复杂。
最简单的情况下,有效负载格式只定义了媒体时钟和 RTP 时间戳之间的映射,并要求将每一帧的编解码器输出直接放到一个 RTP 包中进行传输。这方面的一个例子是 G.722.1 音频的有效负载格式。不幸的是,这在许多情况下是不够的,因为许多编解码器的开发没有参考包传输系统的需要,因此需要调整以适应这种环境。其他的是为分组网络设计的,但是需要额外的头信息。在这些情况下,有效负载格式规范定义了一个附加的有效负载包头以及该包头的生成规则,其中有效负载包头放置在主 RTP 包头之后。
许多有效负载格式已经被定义,与目前使用的多种编解码器相匹配,还有许多正在开发中。在撰写本文时,以下音频有效负载格式是常用的,尽管这不是一个详尽的列表:G.711, G.723.1, G.726, G.728, G.729, GSM, QCELP, MP3,和 DTMF。常用的视频有效负载格式包括 H.261、H.263 和 MPEG。
还有指定错误恢复方案的有效负载格式。例如,RFC 2198 定义了一个音频冗余编码方案,RFC 2733 定义了一种通用的基于奇偶校验编码的前向纠错方案。在这些有效负载格式中有一个间接层,编解码器输出被映射到 RTP 包,这些包本身被映射来产生一个带容错的传输。误差校正将在第 9 章《错误恢复》中详细讨论。
可选的功能
RTP 框架的两个可选部分在这个阶段值得一提:头压缩和多路复用。
报头压缩是一种方法,通过这种方法可以在每个链接的基础上减少 RTP 和 UDP/IP 报头的开销。它用于带宽受限的链路(例如蜂窝链路和拨号链路),可以将 RTP/UDP/IP 报头的 40 字节组合减少到 2 字节,代价是压缩链路两端的系统需要额外处理。包头压缩将在第 11 章进一步讨论。
多路复用是将多个相关的 RTP 会话组合成一个的方法。同样,这样做的动机也是为了减少包头的开销,只不过这次是端到端的操作。多路复用将在第 12 章《多路复用和隧道》中讨论。
包头压缩和多路复用都可以被认为是 RTP 框架的一部分。与配置文件和有效负载格式不同,它们显然是系统的用于特殊用途的可选部分,而且许多实现都不使用这两个特性。
相关标准
除了 RTP 框架外,完整的系统通常还需要使用其他各种协议和标准来设置和控制呼叫、会话描述、多方通信和信令化QoS要求。虽然本书没有详细介绍这些协议的使用,但在本节中,它提供了这些协议规范的说明和进一步的阅读提案。
完整的多媒体协议栈如图 3.1 所示,展示了 RTP 框架与支持的设置和控制协议之间的关系。本书中所讨论的协议和功能已被重点标记。
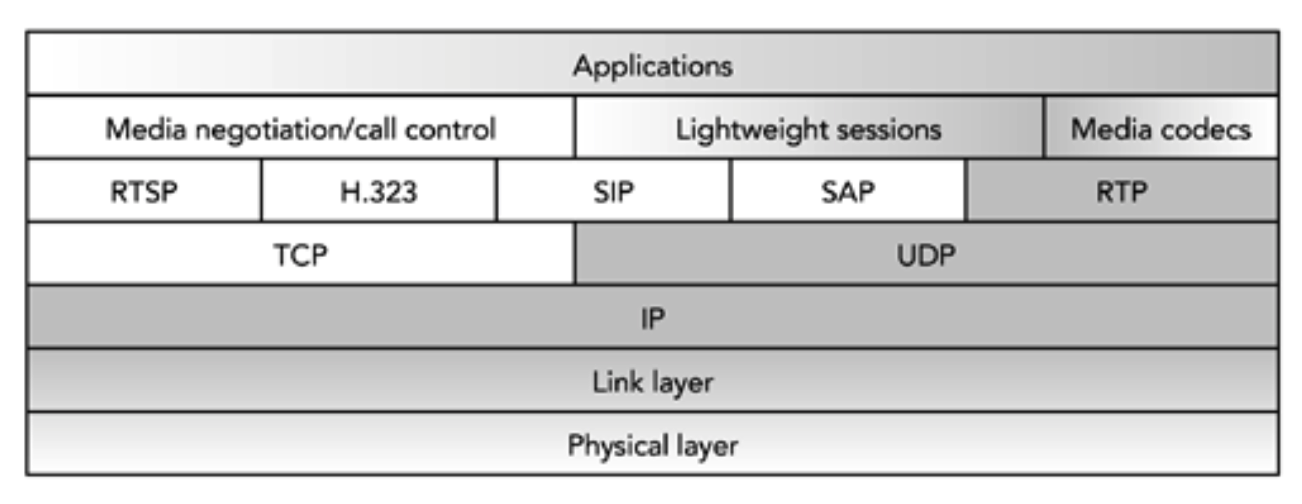
图 3.1 多媒体协议堆栈
调用设置和控制
根据应用场景,可以使用各种呼叫设置、控制和广告协议来启动 RTP 会话:
- 为了启动交互式会话,无论是语音电话呼叫还是视频会议,有两个标准。这方面的最初标准是 ITU 提案 H.323,最近 IETF 定义了会话发起协议 (SIP)。
- 为了开始一个非交互式会话,例如视频点播,主要的标准是实时流协议 (RTSP)。
- RTP 最初的用途是与 IP 组播和轻量级会议模型一起使用。本设计采用了会话通知协议 (SAP) 和 IP 多播通知正在进行的会议,如向公众开放的研讨会和电视广播。
就会话中的参与者数量和这些参与者之间的耦合而言,这些协议的需求非常不同。有些会话是松耦合的,只有有限的成员控制和参与者的知识。其他的则是严格管理的,需要明确的许可才能加入、交谈、聆听和观看。
这些不同的需求导致为每个场景设计了非常不同的协议,并且在这个领域中正在进行大量的工作。RTP 故意不包含会话发起和控制功能,这使得它适用于广泛的应用。
作为应用设计人员,除了 RTP 提供的媒体传输之外,还必须实现某种形式的会话发起、调用设置或调用控制。
会话描述
所有设置和通知协议都需要一种描述会话的方法。在这个领域中一个常用的协议是会话描述协议 (SDP),当然也可能使用其他机制。
不管会话描述的格式如何,始终需要某些信息。媒体流所在的传输地址、媒体的格式、要使用的 RTP 有效负载格式和配置文件、会话活动的时间以及会话的目的等必须传递。
SDP 将这些信息打包成一种文本文件格式,这种格式是人类可读的,并且易于解析。在某些情况下,该文件直接传递给 RTP 应用,从而提供足够的信息来直接加入会话。在另一些情况下,会话描述是协商的基础,是呼叫设置协议的一部分,然后参与者才能进入严格控制的电话会议。
第四章 RTP《数据传输协议》对 SDP 进行了详细的讨论。
QoS
尽管RTP设计用于在IP提供的尽力而为的服务上运行,但有时候能够预留网络资源以提供增强的RTP流的QoS是很有用的。再次强调,这并不是RTP提供的服务,需要借助另一个协议的帮助。目前,互联网上还没有普遍接受的资源预留的“最佳实践”。存在两个标准框架,即综合服务和差异化服务,但它们的部署都相对有限。
综合服务框架通过使用资源预留协议(RSVP)提供严格的QoS保证。路由器需要将可用容量划分为服务类别,并记录流量使用的容量。在开始传输之前,主机必须向路由器发送其需求信号,只有在所需服务类别中有足够容量可用时,预留才能成功。只要所有路由器都遵守服务类别并不过度分配资源,这个要求就能防止链路过载,提供可靠的QoS。可用的服务类别包括保证服务(提供一定的带宽、确定的端到端延迟界限和无拥塞丢包)和受控负载(提供与轻负载尽力而为网络相当的服务)。
综合服务框架和RSVP为每路流预留带宽,当时聚合计算这些预留的带宽是件很复杂的事情。由于路由器需要保留大量状态信息,将RSVP扩展到大规模的异构预留网络存在困难,这限制了RSVP的部署。
差异化服务框架的方法与传统Qos有所不同。它通过在每个数据包的IP头中设置服务类型字段,来定义几种逐跳排队行为,而不是提供端到端的资源预留,也不能做到严格的性能保证。逐跳排队使得路由器能够优先处理某些类型的流量,以降低丢包或延迟的概率。然而,由于路由器无法控制进入网络的流量,因此无法绝对保证性能边界,保证需求得到满足。差异化服务框架的优点在于不需要复杂的信令,并且相比于RSVP,它对状态的需求更小。然而,差异化服务框架的缺点,它的保证质量只能体现在统计数据。
集成和差异化服务框架的组合非常强大,未来的网络可能会将它们组合在一起。RSVP 可用于向边缘路由器发出带宽预留信号,然后路由器将这些需求映射到不同的服务。这种组合允许边缘路由器拒绝过多的流量,提高了差异化服务网络所能提供的保障,同时将 RSVP 所需的状态保持在网络核心之外。
这两个框架在各自的应用领域中有一定的用途,但在撰写本文时,它们尚未达到令人满意的水平。未来的网络可能会采用某种形式的服务质量(QoS),但目前还没有明确的结论。在此之前,我们的任务是确保应用程序在当前最佳网络环境中能够良好运行。
未来的标准开发
随着RTP标准草案状态的修订,协议规范中已经没有已知的未解决问题,并且RTP本身在可预见的将来也不会发生变化。然而,这并不意味着标准工作已经完成。新的有效负载格式仍在不断开发中,新的配置文件将扩展RTP以包含新的功能,例如用于安全RTP和增强反馈的配置文件。
从长远来看,我们期望RTP框架能够与网络的发展保持同步。网络的未来变化可能会对RTP产生影响,我们希望能够利用这些变化来开发新的配置文件。同时,我们也期待出现一系列新的有效负载格式规范,以适应编解码器技术的变化,并提供新的错误恢复方案。
最后,我们可以预期在呼叫设置和控制、资源保留和QoS方面的相关协议会有相当大的变化。这些协议比 RTP 更新,而且目前正在快速发展,这意味着这里的更改可能比 RTP、其配置文件和有效负载格式的更改更重要。
总结
RTP是一个灵活的框架,用于通过IP网络传输音频和视频等实时媒体。它的核心理念是应用级框架和端到端原则,使其非常适合IP网络的特殊环境。 本章概述了RTP的规范、配置文件和有效负载格式。与之相关的标准包括呼叫设置、控制和资源保留。RTP的两个组成部分——数据传输协议和控制协议——将在接下来的两章中进行详细讨论。
第四章 RTP数据传输协议
- RTP会话
- RTP数据传输包
- 包校验
- 转码和混流器
本章介绍了RTP数据传输协议,即传输实时媒体的方法。重点讨论了RTP的“在传输线上”的方面,即数据包格式和互操作性的要求;关于如何使用RTP设计系统的详细说明将在后续章节中进行。
RTP 会话
一个会话是由一组使用RTP进行通信的参与者组成的。一个参与者可能包含多路活跃的RTP会话,例如一路会话传输音频,另一路传输视频。对于每个参与者,会话通过网络地址和端口对来识别,用于发送数据和接收数据。发送和接收端口可以是相同的。每个端口对由两个相邻的端口组成:一个偶数端口用于RTP数据包,下一个较高的(奇数)端口用于RTCP控制包。默认的端口对是UDP/IP协议的5004和5005,但许多应用程序在会话建立过程中会动态分配端口,而不使用默认值。RTP会话被设计用来传输单个媒体类型;在多媒体通信中,每种媒体类型应该在一个独立的RTP会话中传输。
RTP规范的最新修订放宽了RTP数据端口必须是偶数编号的要求,并允许不相邻的RTP和RTCP端口。通过此更改,可以在存在某些类型的网络地址转换(NAT)设备的环境中使用RTP。如果可能,为了与较早的实现兼容,即使不严格要求,使用相邻端口也是明智的。
一个会话可以采用单播方式,在两个参与者之间直接进行(点对点会话),也可以通过中央服务器进行数据重分发。会话的地址空间也不一定需要严格限制。例如,RTP转换器可以在多播和单播之间桥接,或者在IP网络和其他网络之间(如IPv6和ATM)进行桥接。接下来的章节将讨论转换器和混流器的详细信息。
由于会话的范围可能非常广泛,RTP终端系统应该被设计成对底层传输方式基本上是无感知的。一个良好的设计是将传输地址和端口的信息限制在你的底层网络代码,并使用RTP级别的机制进行参与者识别。RTP提供了一个称为"Synchronization Source"(同步源)的机制,用于实现这一目的。对这一机制的详细描述将在本章后面给出。
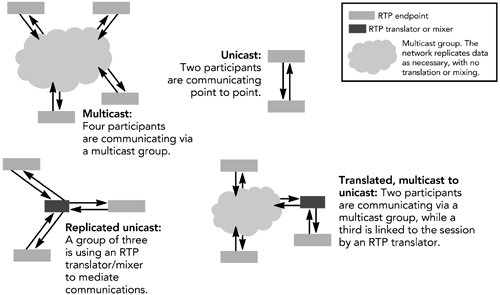
在实际应用中应注意:
- 不应使用传输地址作为参与者标识符,因为数据可能是从转换器或者合成器过来的,会隐藏原来的源地址。应该使用“同步源”标识.
- 不应该假定一个会话只有两个参与者,即使实在单播情况下。单播连接的另一端可以是RTP转换器或混流器,用作可能无限数量的其他参与者参与的网关。
优秀的设计会隐藏背后实际的参与者。
RTP 数据传输包The RTP Data Transfer Packet
RTP 数据包的格式在图4.2 中进行了说明。数据包分为四个部分:
- 固定RTP头
- 可选的包头扩展
- 可选的有效负载头(取决于所使用的有效负载类型)
- 有效负载数据本身
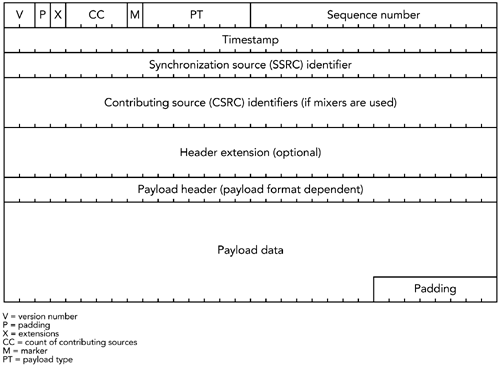
通常RTP包由更底层的协议承载,例如UDP/IP.
包头
固定RTP包头的长度通常为12字节,如果包含贡献源列表,可以将长度扩展4至60个字节。固定包头中的字段:有效负载类型、序列号、时间戳和同步源标识符。另外,还有同步源计数,mark标记,填充和标题扩展标记,以及支持以及版本号。
负载类型
RTP报头中的payload type字段标识RTP数据包中传输的负载类型。接收端检查该字段值来确定如何处理数据包中的有效负载,例如将其传递给特定的解码器。有效负载类型与格式的正式绑定是通过RTP概要文件定义的,其中将有效负载类型编号与有效负载格式规范相对应。这个关系也可以由一个非RTP方法定义。
许多应用程序在音频和视频会议的最小控制下使用RTP配置文件(RFC 1890)进行操作。这个配置文件通常被称为音视频配置文件,它定义了负载类型号和载荷格式规范之间的默认映射表。表4.1中显示了这些静态分配的示例(这不是完整的列表;配置文件定义了其他分配)。除了静态分配之外,还可以使用SIP、RTSP、SAP或H.323等带外信令来定义映射关系。在使用音视频配置文件时,96到127范围内的负载类型被保留用于以这种方式进行动态分配;其他配置文件可能指定不同的范围。
有效负载类型是根据MIME名称空间命名的。该名称空间最初是为电子邮件定义的,用于标识附件的内容,但此后它已成为媒体格式的通用名称空间,并在许多应用中使用。 MIME类型在RTP的使用相对较新(有效负载类型名称最初占用一个单独的名称空间) , 但它功能强大,为每种类型的媒体提供了一个中央存储库的传输和编码选项。
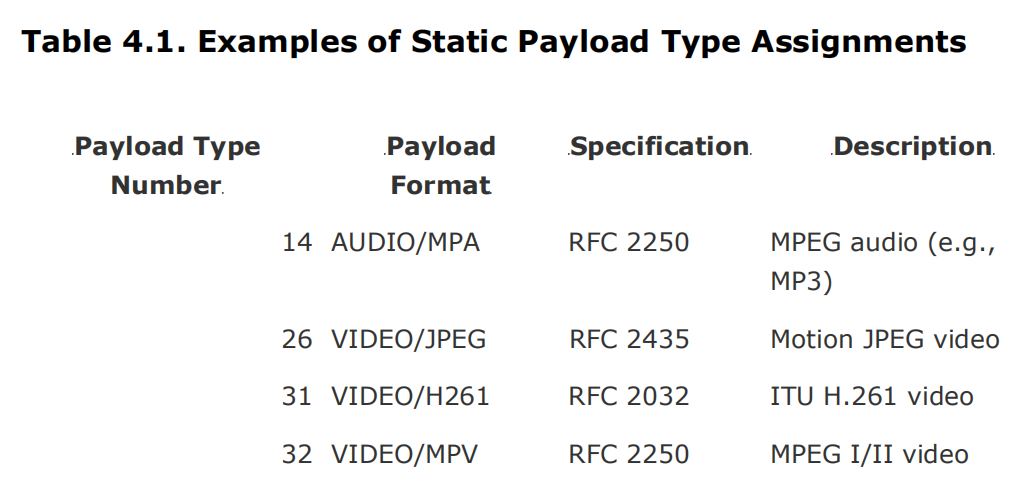
所有的有效负载类型都应该在MIME注册类型中进行注册。更新的有效负载类型应该在各自的规范中包含。
在线维护MIME类型的完整列表,网址为:http://www.iana.org/assignments/media-types.
无论负载类型是静态分配还是动态分配,都需要通知应用程序,以便应用程序知道使用的是哪种负载类型。会话描述协议(SDP)是其中一种通用方法,下面是一个SDP示例:
v=0
o=bloggs 2890844526 2890842807 IN IP4 10.45.1.82
s=-
e=j.bloggs@example.com(Joe Bloggs)
c=IN IP4 224.2.17.12/127
t=2873397496 2873404696
m=audio 49170 RTP/AVP 0
m=video 51372 RTP/AVP 98
a=rtpmap:98 H263-1998/90000
在我们讨论RTP时,需要关注的是 c 和 m 这两行(用于传递RTP会话的地址和端口并定义所使用的配置文件和有效负载类型)和 a = rtpmap 行(用于动态分配有效负载类型)。
该示例描述了两个RTP会话:音频被发送到IPv4多播组224.2.17.12的端口49170,并设置了生存时间为127;视频则被发送到相同的多播组,但端口为51372。音频和视频都使用RTP/AVP作为它们的传输协议;这是使用音频和视频会议的RTP配置文件进行最小控制的RTP传输。
音频使用的负载类型是0,这是配置文件中的静态分配,代表了音频/PCMU的载荷格式。视频的负载类型是98,通过“a=rtpmap”行将其映射到VIDEO/H263-1998的载荷格式。通过参考MIME类型分配表,我们可以找到VIDEO/H263-1998的定义在RFC 2429中。
SDP是描述RTP会话的常用解决方案,但并不是所有的RTP内容都需要使用SDP。例如,基于ITU建议H.323的应用使用RTP进行媒体传输,但使用不同的机制(H.245)来描述会话。
对于有效负载类型编号向有效负载类型的映射,静态分配与动态分配之间的优缺点存在一些争议,这可能是由于音频/视频配置文件中的静态分配列表很长,而动态分配所需的信令又太复杂。 当RTP刚出现时,用来是实验的载荷格式是很简单,这种情况下静态载荷类型分配是有意义的。接收方只需根据载荷类型号解码RTP载荷,因为编解码器不需要额外的配置,而且简陋的信令反而简化了这些新应用的开发。 但是,随着设计人员关于RTP经验的增加,并将其应用于更复杂的有效负载类型,那么很明显,静态分配是有缺陷的。 当今大多数使用的载荷格式除了载荷类型分配外还需要额外的配置,这就需要使用信令;而新兴应用,如IP电话和视频点播,需要信令来进行用户定位、身份验证和付款。既然信令已经是必需的,那么静态载荷类型分配的优点也就消失了。 使用动态分配还可以避免由于有效负载类型空间耗尽而引起的问题。只有127种静态分配类型,而可能的有效负载类型数量远远超过了该数量。动态分配仅允许将会话持续时间所需的那些格式绑定到有效负载类型编号。 因此,IETF音频/视频传输工作组的政策是不再进行更多的静态分配,应用可以用带外信令通知其有效负载类型使用情况。
RTP媒体时钟和载荷头以及载荷本身的格式。对于静态分配,时钟速率在配置文件中指定;动态分配必须在载荷类型和载荷格式之间的映射中指示时钟速率。例如,在前面的会话描述中,“a=rtpmap”行指定VIDEO/H263-1998载荷格式使用90,000赫兹的时钟。大多数载荷格式都使用有限的一组时钟速率,载荷格式规范定义了哪些速率是有效的。
RTP会话不局限于使用单个有效负载类型。会话中可以使用多种有效负载类型,不同的格式由不同的有效负载类型标识。该格式可以在会话中的任何时间更改,并且只要预先通知了从有效负载类型到有效负载类型的映射,就无需在更改发生之前发出信号。一个示例可能是在IP语音会话中对DTMF音频进行编码,以支持自动服务的“按0与操作员通话”样式,其中一种格式用于语音,另一种格式用于人工会话。
尽管在会话中可以使用多种有效负载类型,但有效负载类型并不适用于复用不同类别的媒体。举个例子,如果应用程序同时发送音频和视频,应该将它们作为两个不同的RTP会话通过不同的地址/端口发送,而不是将它们作为单个RTP会话发送后再进行有效负载类型的多路分解。通过将媒体分离,应用可以为不同的媒体需求提供不同的QoS,并且这对于RTP控制协议的正确运行也是必要的。
序列号 SEQUENCE NUMBER
RTP序列号用于标识数据包,并在数据包丢失或乱序发送时向接收端提供指示。 尽管序列号可以让接收端按发送顺序重新组织数据包,但它不用于数据包的播放顺序(这是时间戳的作用)。
序列号是一个无符号的16bit整数,每个包 +1,并在达到最大值时翻转归零。 16bit整数的最大影响就是需要会频繁的翻转:典型的VOIP应用以20毫秒的数据包发送音频,大约每20分钟就会翻转一次序列号。
这意味着应用不应该依赖序列号作为唯一的数据包标识符。相反,建议大家使用一个32bit或者更大扩展序列号,在内部识别数据包,其中低16bit是来自RTP数据包的序列号,高16bit是序列号包绕的次数的计数:
extended_seq_num = seq_num + (65536 * wrap_around_count)
由于可能会丢包或乱序,因此在序列号回零时,保持翻转计数器(wrap-around-count)并不只是增加计数那么简单。 RTP规范中用于维护翻转计数器的算法:
uint16_t udelta = seq – max_seq;
if (udelta < max_dropout) {
if (seq < max_seq) {
wrap_around_count++
}
max_seq = seq;
} else if (udelta <= 65535 – max_misorder) {
// The sequence number made a very large jump
if (seq == bad_seq) {
// Two sequential packets received; assume the
// other side has restarted without telling us
...
} else {
bad_seq = seq + 1;
}
} else {
// Duplicate or misordered packet
...
}
注意,所有计算均使用取模和16bit无符号数进行。seq和max_seq都是RTP数据包中未扩展的序列号。 RTP规范建议max_misorder = 100,max_dropout = 3000。
如果扩展的序列号是在接收到数据包后立即计算并使用,大多数应用都不知道序列号翻转。隐藏翻转大大简化了丢包检测,隐藏数据包重排,以及统计信息的维护。除非数据包速率很高,否则32bit序列号的翻转时间使大多数应用可以忽略这种可能性。例如,前面给出的IP语音的例子来翻转扩展的序列号需要两年多的时间。
如果数据发包频率很高,那么应用运行时,可能会翻转32bit扩展序列号。在此类环境中设计应用时,必须使用更大的扩展序列号(例如64位)来避免该问题,或者通过使用32bit模运算对序列号执行所有计算来构建应用以处理翻转。序列号翻转期间的错误操作是个常见问题,尤其是当数据包在翻转期间丢包或重新排序时。
序列号的初始值应随机生成,而不是从零开始。**这个措施的目的是: 对加密RTP的流进行已知的纯文本攻击更难。**即使源未加密,随机初始序列号的使用也很重要,因为流可能会经过源不知道的加密转换器,并且在转换器中添加随机偏移也不是一件容易的事(因为序列号要在RTCP接收报告数据包中报告;请参见第五章,RTP控制协议)。一个常见的实现错误是假设序列号从零开始。不论初始序列号如何开始 ,接收端应该能够正常播放。
序列号应始终是连续的序列,对于每个数据包,序列号应增加一,并且永远不要向前或向后跳转(当然,翻转除外)。而不管媒体如何生成,即使负载类型发生变化,例如,当你将视频剪辑拼接在一起时(也许是为了插入广告),RTP序列号空间必须是连续的,并且不得在每个剪辑的开头重置它。这会影响流媒体服务器的设计,不依赖媒体文件中的序列号,而对读出的文件重新组包,重新生成序列号。
序列号的主要用途是丢包检测。序列号空间中的间隔向接收端表明必须采取措施来恢复或隐藏丢包。这在第8章《错误隐藏》和第九章《错误恢复》中有更详细的讨论。
序列号的第二个用途是允许重新组织发送数据包的顺序。接收端不必关心这一点,因为许多负载类型允许以任意顺序解码数据包-但是在接收到数据包时按顺序对数据包进行排序可能会使丢包检测更加容易。播放缓冲算法的设计在第六章《媒体采集、播放和时序》中有更详细的讨论。
时间戳 Timestamp
RTP Timestamp表示数据包中媒体数据的第一个字节的采样时刻,用于编排媒体数据的播放。时间戳是一个32bit无符号整数,其增速与媒体类型相关,并在超过最大值时翻转归零。对于典型的视频编解码器,使用90kHz的时钟频率,相当于大约13个小时的翻转。对于8kHz音频,间隔大约为6天。
时间戳的初始值是随机生成的,而不是从零开始。与序列号一样,此预防措施旨在使对加密RTP流的已知纯文本攻击更加困难。即使源未加密,使用随机初始时间戳也很重要,因为流可能会通过源未知的加密转换器。一个常见的实现问题是假设时间戳从零开始。接收端应该能够播放流而不管初始时间戳如何,并准备处理翻转信号;因为时间戳记并非从零开始,所以可能随时发生翻转。
时间戳翻转是RTP正常操作,应由应用处理。使用扩展的时间戳记(比如64位)可能会使大多数应用感受不到翻转。但是,不建议使用扩展时间戳,因为在当今的处理器上64位运算通常效率低下。
更好的设计使用32bit模运算来执行所有时间戳计算。这种方法允许计算时间戳之间的差,前提是所比较的数据包都位于时间戳空间的同一半。
时间戳是从媒体时钟派生而来的,该媒体时钟必须以线性单调的方式梯增(当然,翻转除外),从而为每个RTP会话生成单调的时间轴。这与媒体流的生成方式无关。
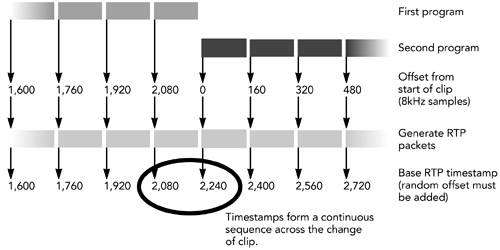
可以使用一个示例来阐明时间戳增加方式的含义:当音频剪辑在单个RTP会话中拼接在一起时,RTP时间戳必须形成连续的序列,并且不得在每个剪辑的开头重置。这些要求在图4.3中进行了说明,该图表明RTP接收端无法从RTP包头中识别出已经发生更改。
当发生快进或快退操作时,也是如此,时间戳记必须形成连续的序列,并且不能跳来跳去。这个要求在实时流协议(RTSP)的设计中很明显,该协议包括“正常播放时间”的概念,代表了流中的时间索引。由于必须保持RTP时间戳的连续性,因此RTSP服务器必须在seek操作期间在RTP时间戳和正常播放时间之间发送更新映射。
RTP时间戳的连续性对流媒体服务器的设计有影响。服务器不能依赖存储在媒体文件中的时间戳(或序列号),而必须考虑到媒体内的seek操作以及RTP会话中已播放的任何先前数据的持续时间,即时生成它们。
对以线性和单调方式增加的媒体时钟的要求,并不一定意味着媒体数据的采样顺序就是其发送顺序。在生成媒体帧并获得其时间戳之后,可以在打包之前对它们进行重新排序。所以,即使序列号顺序得到维护,数据包也可能不按时间戳顺序发送。接收端必须重建时间戳顺序才能播放媒体。
MPEG视频就是一个例子,它既包含关键帧又包括从中预测的前向(P帧)和向后(B帧)预测的增量编码帧。当使用B帧时,它们是从后面的数据包中预测出来的,因此必须延迟并乱序发送。结果是RTP流将具有非单调递增的时间戳。另一个例子,用交织编码减少突丢包的影响(请参见第八章错误隐藏中标题为交织的部分)。任何情况下,接收端都必须重构单调时间线播放媒体。
RTP数据包上的时间戳在每个翻转周期内不一定是唯一的。如果两个数据包包含来自同一采样时刻的数据,则它们将具有相同的时间戳。时间戳的重复通常发生在将大视频帧拆分为多个RTP数据包进行传输时(这些数据包将具有不同的序号,但具有相同的时间戳)。
用于生成时间戳的媒体时钟的标称速率由使用中的配置文件和/或负载格式定义。对于具有静态负载类型分配的负载格式,当使用静态负载类型时(它被指定为负载类型分配的一部分),时钟速率是隐式的。动态分配过程必须指定速率以及负载类型(参见本章前面的标题为Payload Type的部分)。所选速率必须足以按期望的精度执行唇同步,并测量网络传输时间的变化。时钟频率不能任意选择;大多数载荷格式定义了一个或多个可接受的速率。
音频有效负载类型通常使用采样率作为其媒体时钟,因此,每次读取完整的样本时,时钟将增加一。有两个例外:MPEG音频使用90kHz时钟以与非RTP MPEG传输兼容。 G.722是16kHz语音编解码器,它使用8kHz媒体时钟来向后兼容RFC 1890,后者错误地指定了8kHz而不是16kHz。
视频有效载荷格式通常使用90kHz的时钟,来兼容MPEG,因为这样做产生了典型的24Hz、25Hz、29.97Hz和30Hz帧率以及今天广泛使用的50Hz、59.94Hz和60Hz字段率的整数时间戳增量。例如PAL (相位交替线)和NTSC ( 国家电视标准委员会 )电视,以及HDTV (高清晰度电视)格式。
重要需要记住的是,RTP不能保证媒体时钟的刻度,准确性,稳定性,这些属性被认为与应用有关,并且不在RTP的范围之内。通常,已知的只是其标称频率。除非应用有相反的特定知识,否则应用应该能够应对发送端和接收端媒体时钟的变化。
在某些情况下,可以定义媒体时钟的刻度,准确性和稳定性,并使用此知识来简化应用设计。通常只有在单个实体同时控制发送端和接收端,或者两者都针对具有严格时钟规范的配置文件时,才有可能。
接收端根据时间戳重建媒体流的正确时序的过程在第六章《媒体采集、播放和时序》中进行了描述。
同步源synchronization source
synchronization source(SSRC)标识RTP会话中的参与者。SSRC是临时的,每个会话的标识符通过RTP控制协议映射到长期的规范名称CNAME(请参阅第五章RTP控制协议标题为RTCP SDES:Source Description的部分)。
SSRC是一个32bit整数,由参与者加入会话时随机选择。选择了SSRC标识符后,参与者就可以在发送数据是使用它。由于SSRC值是在本地选择的,因此两个参与者可能会选择相同的值。当一个应用发现从另一个应用收到的数据包包含为其自身选择的SSRC标识符时,可以检测到此类冲突。
如果某个参与者检测到当前使用的SSRC与另一参与者选择的SSRC之间发生冲突,则它必须向原始SSRC发送RTCP BYE(请参阅第五章RTP控制协议标题为RTCP BYE:Membership Control的部分)并选择另一个SSRC。这种冲突检测机制可确保SSRC对于会话中的每个参与者都是唯一的。
重要的是,使用高质量的随机源来生成SSRC,并实现冲突检测。尤其是,随机数生成器的种子不应基于会话加入的时间或会话的传输地址,因为如果多个参与者同时加入,会导致冲突。
具有相同SSRC的所有数据包均构成单个时序和序列号空间的一部分,因此接收端必须按SSRC对数据包进行分组才能进行播放。如果参加者在一个RTP会话中生成多个流(例如,来自不同的摄像机),每个流都必须标识为不同的SSRC,以便接收端可以区分哪些数据包属于每个流。
贡献源 CONTRIBUTING SOURCES
在正常情况下,RTP数据由单个数据源生成,但是当多个RTP流通过混流器或转换器时,多个数据源都可能对RTP数据包有所贡献。 贡献源(CSRC)列表标识了对RTP数据包做出了贡献的参与者,但不负责其时序和同步。每个贡献源标识符都是一个32bit整数,对应数据包做出贡献的参与者的SSRC。 CSRC列表的长度由RTP包头中的CC字段标识。
包含CSRC列表的数据包是通过RTP混流器的处理生成的,如本章后面的Mixers部分所述。当接收到包含CSRC列表的数据包时,SSRC将以常规方式将数据包分组来播放,并将每个CSRC添加到已知参与者列表中。由CSRC标识的每个参与者将具有相应的RTP控制协议数据包流,从而提供对参与者的完整标识。
标记 Maker
RTP包头中的 marker(M) 位用于标记媒体流中的关注事件;它的确切含义由所使用的RTP配置文件和媒体类型定义。
对于在RTP以最小的控制配置文件下在音频和视频会议下运行的音频流,标记位设置为1,表示在一段静默期后发送的第一个数据包,否则设置为0。将标记位设置为1可以告诉应用,这可能是调整播放点的好时机,因为听众通常不会注意到静音期长度的微小变化(而播放音频时播放点的变化是可以听见的)。
对于在RTP配置文件,在音频和视频会议中运行的视频流,标记位设置为1以标识视频帧的最后一个数据包,否则设置为0。如果设置为1,则该标记用作应用可以开始解码该帧的提示,而不是等待下一个具有不同时间戳的数据包来检测应显示该帧。
在任何情况下,标记位仅向应用提供提示,即使具有标记集的数据包丢失,程序也必须正常运行。对于音频流,因为静默期结束时序列号和时间戳之间的关系会发生变化,可以通过这个感知到其结束。可以通过观察时间戳的变化来检测视频帧的开始。如果包含标记位的数据包丢失,则应用可能会使用这些手段观察,但是程序性能降低。
RTP配置文件可以指定其他标记位,但以较小的有效负载类型字段为代价。例如,配置文件可以要求两个标记位和一个六位有效负载类型。当前没有任何配置文件使用此功能。
填充 PADDING
RTP包头中的padding(P)位用于标识有效负载已被填充超过其自然长度。如果将填充添加到RTP数据包,则设置P位,并用填充字节的计数填充有效负载的最后一个字节。填充很少使用,但是对于某些与特定块大小配合使用,并使有效负载类型适应固定容量信道的加密方案来说,填充是必需的。
作为填充的使用示例,图4.4展示了以RTP打包的GSM音频帧,该帧已从其自然长度45个字节(GSM帧为33个,RTP头为12个)的自然长度填充为48个八位字节。如果使用数据加密标准(DES)对数据包进行加密,则需要填充数据,因为DES需要8字节(64位)的块。

版本号 VERSION NUMBER
每个RTP数据包都包含一个版本号,由V字段表示。 RTP的当前版本定义了其他版本号,但RTP的版本号并未得到广泛使用。版本号字段的唯一有意义的用途是作数据包有效性检查。
头扩展 Header Extensions
RTP允许这样一种可能性,即扩展位包头(由X位设置为1表示)出现在固定RTP包头之后,但在任何有效负载包头和有效负载本身之前。扩展头的长度是可变的,但它们以16bit类型字段开头,后跟16bit长度字段(该字段以八位字节为单位计算扩展的长度,不包括起始的32bit),如果接收端不能解析扩展头可以忽略。
扩展包头用于需要比固定RTP包头提供更多包头信息的情况。它们很少使用。需要额外的、与有效负载类型无关的头信息的扩展最好更新的RTP配置文件。如果特定的有效负载类型需要其他包头,它们不应使用扩展头,而应在数据包的有效负载部分中作为有效负载包头传输。
尽管头扩展名极为罕见,但是为程序的健壮性考量,可以通过忽略扩展头来处理无法识别的包头扩展。
负载头 Payload Headers
强制性RTP包头提供了所有有效负载类型所共有的信息。通常情况下,负载头都需要额外的信息,来辅助实现正确的处理数据,这些额外的数据形成一个附加的头,这个头被定义为有效负载类型规范的一部分。有效负载包头在固定包头、CSRC列表和包头扩展之后的RTP数据包中。有效负载头的定义通常构成有效负载类型规范。
有效负载头中包含的信息可以是静态的(对于使用特定有效负载类型的每个会话都相同),也可以是动态的。有效负载类型规范会规定有效负载头的哪些部分是静态的,哪些是动态的,并且必须在会话的基础上进行配置。那些动态的部分通常通过SDP配置,其中a = fmtp属性用于定义“格式参数”,尽管有时会使用其他方式。但是可以指定的参数分为三类:
1.影响有效负载包头格式的信息,这些信息表明包头字段的存在与否,以及其大小和格式。例如,某些有效负载类型具有几种操作模式,这些模式由负载头决定。
2.不影响有效负载包头格式但定义了各种包头字段的用法。例如,某些有效负载类型定义了交织编码,并要求头字段指示交织序列内的位置。
3.代替有效负载头而影响有效负载类型的变量。例如,参数可以指定音频编解码器的帧大小或视频帧率。
使用有效负载头的主要原因是为那些不是设计用于有损数据包网络的格式提供错误恢复能力。第一个示例是RFC 2032和RFC 2736中讨论的H.261视频的有效负载类型。 在第8章《错误隐藏》和第9章《错误恢复》中进一步讨论了容错的问题。
用于H.261视频的RTP有效负载类型在设计上提供了有趣的教训,以提高错误恢复能力。 H.261编解码器允许视频块组的最大长度为3 KB。有效负载类型的原始版本规定,每组块都应直接插入RTP数据包中,或者如果太大,则应在数据包之间任意拆分。然而,这种方法留下了这样一种情况,包到达接收端并且必须被丢弃,因为先前的包丢失了,部分块组不能独立地被解码。这是我们要避免的丢包乘数效应。 实际上,块组不是H.261视频中的最小单位。有一些较小的单元,称为macro-blocks,但是如果不从块组的开始进行解析就无法识别它们。然而,在每个包的开始处包括附加信息就可以恢复通常从块组的开始进行解析而找到的信息。此技术用于定义有效负载类型,如果该有效负载超出了网络MTU,则会在宏块边界上拆分H.261流。 对于H.261,这不太明显,但确实意味着智能解码器可以从丢失的RTP数据包流中重建有效的H.261视频,而不必丢弃任何已经到达的数据。它显示了有效负载类型的容错设计的优势。
有效负载数据
直接在负载包头之后的一帧或多帧媒体负载数据构成RTP数据包的最后部分(除了有填充)。有效负载数据的大小和格式取决于会话建立期间选择的有效负载类型和格式参数。
许多负载类型允许在每个数据包中包含多个数据帧。接收端可以通过两种方式确定存在多少帧:
1.许多情况下,帧的大小是固定的,可以通过检查数据包的大小来确定存在的数目。
2.其他负载类型在封装的帧中包括一个标识符,该标识符指示帧的大小。应用需要解析封装的帧,以确定帧的数量及其起点。当帧长是可变大小时,通常是这种情况。
通常,对可包含的帧数没有限制。预计接收端将处理各种大小的数据包:音视频配置文件中的准则建议,以帧大小的倍数为单位,最多200毫秒的音频,而视频编解码器应同时处理分片帧和完整帧。
选择每个数据包中要包括的有效负载数据量时,要考虑两个关键问题:将要遍历的网络路径的最大传输单位(MTU),以及等待更多数据来填充一个长包产生的延迟。
超过MTU的数据包要么被碎片化,要么被丢弃。如果丢弃过大的数据包显然是不可取的;碎片化带来的问题不太明显。当所有碎片到达接收端时,将在接收端重新组装一个碎片包。如果丢失任何片段,即使正确接收到了其中的某些部分,整个数据包也必须被丢弃。结果是一个损失乘数效应,如果数据包大小合适,并且设计有效载荷格式使得每个数据包能够独立解码,就可以避免这个效应
延迟也需要考虑的问题,只有在生成数据的最后一个字节之后,才能发送数据包。数据包开始处的数据会缓存直到完整的数据包就绪为止。在许多应用中,与MTU相比,延迟问题在应用上提供了更严格的约束。
包校验 Packet Validation
由于RTP会话通常使用动态协商的端口对,因此验证接收到的数据包确实是RTP而不是其他数据尤为重要。乍一看,确并非易事,因为RTP数据包不包含显式协议标识符;然而,通过观察多个数据包的包头字段,我们可以快速验证RTP流有效性。
RTP规范的附录A中列出了可以对RTP数据包流执行的有效性检查。有两种类型的测试:
1.基于包头字段的固定已知值进行Per-packet checking,例如,版本号不等于2的数据包无效,有效负载类型不对的数据包也无效。
2.基于包头字段中的模式的Per-flowchecking。例如,如果SSRC恒定,并且每个接收到的数据包序列号加1,并且时间戳间隔适用于有效负载类型,那么几乎可以肯定这是RTP流,而不是流向错误的流。
流检查更有可能检测到无效数据包,但它们需要将其他状态保留在接收端中。有效源需要这些状态,但必须小心,因为保持过多状态以检测无效源可能导致拒绝服务攻击,在这种攻击中,恶意源向接收端发送大量的虚假数据包,会用尽资源。
一个可靠的实现将使用强大的Per-packet checking来清除掉尽可能多的无效数据包,然后再将资源提交Per-flowchecking检测其他数据包。它还应准备好主动丢弃状态疑似虚假的源,以减轻拒绝服务攻击的影响。
此外,还可以利用相应的RTCP控制包验证RTP数据流的内容。为此,应用丢弃RTP包,直到收到具有相同SSRC的RTCP源描述包为止。这是一个非常强大的有效性检查,但是会导致显着的验证延迟,尤其是在大型会话中(因为RTCP报告间隔可能是几秒钟)。因此,我们建议应用直接验证RTP数据流,使用RTCP作为确认而不是主要的验证方 法。
转换器和混流器
除了普通的终端系统,RTP还支持可在会话中的媒体流上运行的中间件。定义了两类中间件:转换器和混流器。
转换器
转换器是在RTP数据上运行,同时保持流的同步源和时间轴的中间系统。例如:在媒体编码格式之间进行转换而不进行混合,在不同的传输协议之间桥接、添加或删除加密或过滤媒体流的系统。除非RTP终端系统具有未转换媒体的先验知识,否则转换器对RTP终端系统透明。有几类转换器:
•Bridges。桥接器是一对一的转换器,不会更改媒体编码,例如,不同传输协议之间的网关,例如RTP / UDP / IP和RTP / ATM,或RTP / UDP / IPv4和RTP / UDP / IPv6。桥接器是最简单的转换器类,通常它们不会对RTP或RTCP数据造成任何影响。
•Transcoders。转码器是一对一的转换器,它们可以更改媒体编码(例如,解码压缩数据并以不同的有效负载类型对其重新编码),以更好地适应输出网络的特性。有效负载类型通常会更改,填充也会更改,但其他RTP包头字段通常保持不变。这些转换需要保持状态,以便可以调整RTCP发送端报告以使其匹配,因为它们包含源比特率的计数。
•Exploders。Exploders是一对多转换器,它们接收单个数据包并产生多个数据包。例如,Exploders接收一个流,其中每个RTP数据包中包括多个编解码器输出帧,Exploders生成包含单个帧的数据包,生成的数据包具有相同的SSRC,但其他RTP包头字段可能必须更改,具体取决于转换。这些转换需要维持双向状态:转换器必须调整RTCP发送端报告和返回的接收端报告以匹配。
•Mergers。Mergers是多对一转换器,将多个数据包合并为一个。这是上一类别的反面,并且存在相同的问题。 转换器的定义特征是每个输入流都产生具有相同SSRC的单个输出流。转换器本身不是RTP会话的参与者,它没有SSRC且本身不生成RTCP,并且其他参与者不可见。
混流器 Mixer
mixer 是一个中间系统,它从一组源中接收RTP数据包并将其组合为单个输出,在转发结果之前可能会更改编码。例如:音频混合平台或视频画中画设备等网络设备。
因为输入流的时序通常不同步,所以混流器将不得不在合并它们之前进行调整以使媒体同步,因此它成为输出媒体流的同步源。混流器可以对每个到达的媒体流使用播出缓冲器,以帮助维持流之间的定时关系。混频器具有自己的SSRC,它将其插入自己生成的数据包中。来自输入数据包的SSRC标识符被复制到输出包的CSRC列表中。
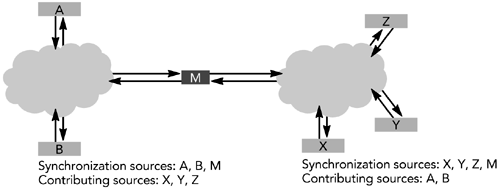
混流器具有会话的唯一视图:它将所有源视为同步源,而其他参与者则看到一些同步源和一些贡献源。例如,在图4.5中,参与者X从三个同步源(Y,Z和M)接收数据,而A和B在来自M的混合数据包中贡献源。参与者A将B和M视为同步源,X、Y和Z是M的贡献源。混流器为会话的每一半分别生成RTCP发送端和接收端报告,并且不在各自之间转发它们。它转发RTCP源描述和BYE数据包,以便可以识别所有参与者(在第五章,RTP控制协议中讨论了RTCP)。
图4.5 混频器M将所有源视为同步源。其他参与者(A,B,X,Y和Z)则看到了同步源和贡献源的组合。 混流器不需要在会话的每半部分使用相同的SSRC,但是它必须将RTCP源描述和BYE数据包发送到两个会话的所有SSRC标识符。否则,一半的参与者不会知道SSRC正在另一半使用,他们可能会与之发生冲突。
跟踪转换器或混流器每一侧上存在哪些源非常重要
当错误的配置产生了环路时(例如,如果两个转换器或混流器并行连接,则将数据包循环转发)。如果检测到循环,则转换器或混流器应停止操作,并记录尽可能多的诊断信息。循环数据包的源IP地址最有用,因为它标识了导致循环的主机。
总结
本章已经详细描述了RTP数据传输协议在审议中的主要内容。我们考虑了RTP包头的格式及其用途,包括用于标识数据格式的有效负载类型,用于检测丢包的序列号,用于显示何时播放数据的时间戳以及作为参与者标识符的同步源。我们还讨论了次要的包头字段:标记,填充和版本号。
有效负载类型的概念及其到有效负载类型标识符和有效负载包头的映射现在应该很明显了,显示了RTP是如何针对不同类型的媒体量身定制的。这是一个重要的主题,我们将在后面的章节中讨论。 最后,我们讨论了RTP转换器和混流器:以受控方式扩展RTP范围的中间系统,允许会话桥接网络的异构性。 与RTP数据传输协议相关的是控制通道RTCP,本章已多次提及。下一章将更深入地讨论此控制信道,从而完成我们对RTP网络方面的讨论。
第五章 RTP控制协议
- RTCP的组成
- RTCP包如何传输
- RTCP包格式
- 安全和隐私
- RTCP包校验
- 参与者数据库
- 时序规则
RTP协议由两个部分组成:数据传输协议和控制协议。在本章中,我们将详细介绍数据传输协议,而在上一章中,我们介绍了控制协议RTCP。RTCP用于定期上报如下信息:
- 接收质量
- 参与者标识
- 数据源描述信息
- 会话成员变化
- 同步媒体流所需的其他信息。
RTCP的组成
RTCP的实现主要包括三个方面:数据包格式、时序规则和参与者数据库。
RTCP数据包有多种类型。本章的后续部分 "RTCP数据包格式" 详细描述了五种标准数据包类型,以及它们在发送前如何被聚合成复合数据包。此外,在"Packet验证"部分介绍,校验RTCP数据包正确性的算法。
根据本章后面RTCP时序规则中的规则,定期发送聚合数据包。数据包之间的间隔我们称之为传输间隔。所有RTCP活动都发生在整数倍的间隔时间内。除了作为包间隔的时间外,还是计算接收质量统计信息的时间,以及更新源描述和音视频同步信息的时间。时间间隔会根据所使用的媒体格式和会话的大小而有所不同。通常,小型会话连接的间隔时间大约在5秒,但是大型的会话会增加到几分钟。在计算报告发送间隔时优先从发送者考虑,因此发送者的发送源信息和音视频同步信息发送得比较频繁。而接受者的上报通常较少。
每一个实现都应该基于从RTCP包接收到信息维护一个参与者数据库(Participant database),此数据库除了用于定期填写发送的接收报告的数据包外,还用于在接收到音频和视频流之间进行音视频同步,并且维护源描述信息。本章后面的标题为《安全和隐私》的部分中,会提到参与者数据库中的隐私问题。同样,在本章中的《参与者数据库》部分描述了如何维护参与者数据库。
RTCP数据包传输
每一个RTP的会话都是由一个网络地址和一对端口号做为标识:一个端口用于RTP数据,另一个端口用于RTCP数据,RTP数据端口应为偶数,RTCP端口应该是RTP端口加 1,例如,如果媒体数据使用 UDP 5004 端口,那么控制信道将在与RTP相同的IP地址上的端口 5005 上。
所有的会话参与者都必须发送复合的RTCP包,然后接收其他参与者传输过来的聚合数据包。注意,接收后的应答信息(feedback)是需要发送给多方会话中的所有参与者的。反馈信息可以单播(unicast)的形式发送给转换器(translator)再通过转换器分发,也可以通过多播发送。RTCP的P2P特性让会话中的每个参与者了解其他参与者的信息、它们的存在、接收质量以及可选的个人信息如姓名、邮箱、地址和手机号。
RTCP包格式
RTCP协议规范中定义了五种类型的RTCP包 :
- 接收者报告(RR)
- 发送者报告(SR)
- 源描述(SDES)
- 结束(BYE)
- 应用定义(APP)
它们遵循统一的格式(图5.1),每种类型都不同。
图5.1 基本的RTCP包格式
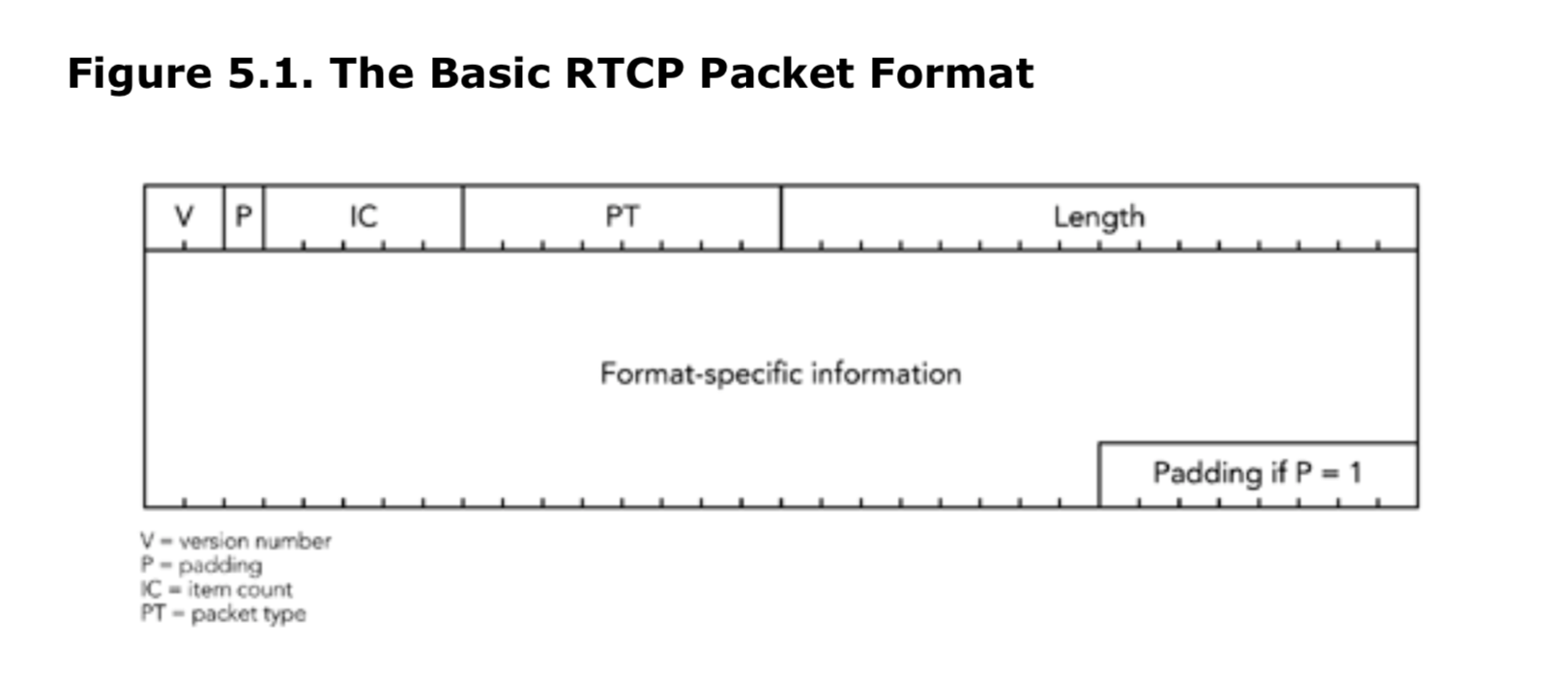
上述五种包类型的包头都由4个字节组成,包含五个字段。
- 版本号(V):对于当前版本的RTP协议,版本号为2(截止到本书编纂为止),目前还没有推出新版本的计划,之前的版本也并没有广泛的被使用。
- 填充(P):填充(P)字段用于在包头中进行填充位操作,当前位数已满的情况下继续添加数据。如果该字段被设置为1,表示包尾有一个或多个字节填充,最后一个字节的内容表示了填充的总字节数。填充位的用法类似于RTP数据包中的填充位,在第四章的RTP数据传输协议中有详细介绍。在使用RTCP协议时,错误地填写填充位是一个常见问题,而正确的用法将在本章的《打包和包校验问题》部分进行描述。
- 条目计数(IC):一些RTCP类型包含一组多条条目,这些条目是固定的、特定于类型的信息。这些RTCP类型使用项目计数字段来指示数据包中包含的条目数量(根据使用情况,不同数据包类型的字段名称可能不同)。每个RTCP数据包最多可以包含31个条目,但也受网络的最大传输单元限制。如果需要超过31个项目,则应用程序必须生成多个RTCP数据包。当项目计数为零时,表示项目列表为空(这并不一定意味着数据包本身为空)。不需要项目计数的数据包类型可以将此字段用于其他目的。
- 包类型(PT):字段用于标识传输的包中携带的信息类型。在RTP的规范中,定义了五种标准的数据包类型。未来可能还会定义其他类型,例如用于报告额外统计信息或传递特定源信息的类型。
- 长度:此字段用于标识包头之后内容的总长度。由于所有RTCP数据包的长度必须是4字节的整数倍,因此该字段的值表示以4字节为单位的数量。当长度为0时,表示该包只包含4字节的包头(此时字段IC也为0)。
RTCP的包头之后存储的是包数据(其具体格式要根据包类型来决定)和可选的填充字段。包头和后面的具体数据组成了一个完整的RTCP包。下面几个小节将详细描述五种标准类型的RTCP包。
RTCP包不会独立发送,需要打包在一起形成复合包(compound packets)发送。每一个复合包都会经过一个更底层的封装(通常是UDP/IP包)来传输。如果要对复合包进行加密,那么RTCP的包组的前缀通常是一个4字节的随机数。复合包的结构如图5.2所示。
RTCP包中复合包的结构
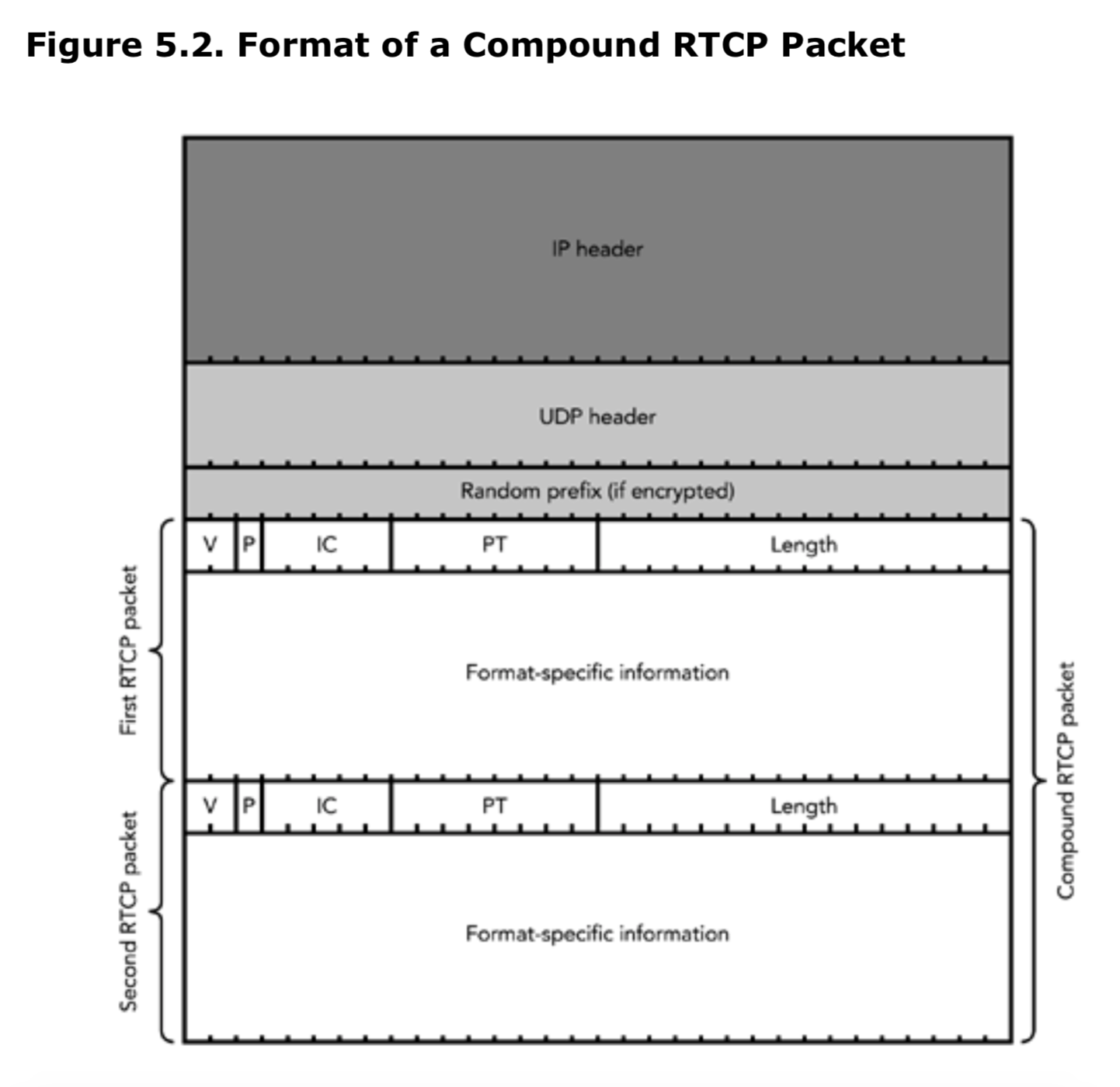
RTCP复合包打包由一系列规则来控制。在对五种RTCP包进行更详细的描述之后,打包规则将在本章的“打包问题”部分进行描述。
RTCP中的RR:接收报告(receiver reports)
RTCP的主要用途之一就是报告接收者质量,通过所有接收数据的参与者发送的RTCP的接收报告(RR)包来完成。
RTCP协议中RR数据包格式
接收报告由类型由201标识,格式如图5.3。接收报告中包含发送报告的参与者的SSRC(同步源),后面跟着0个或多个报告块,用RC字段表示。
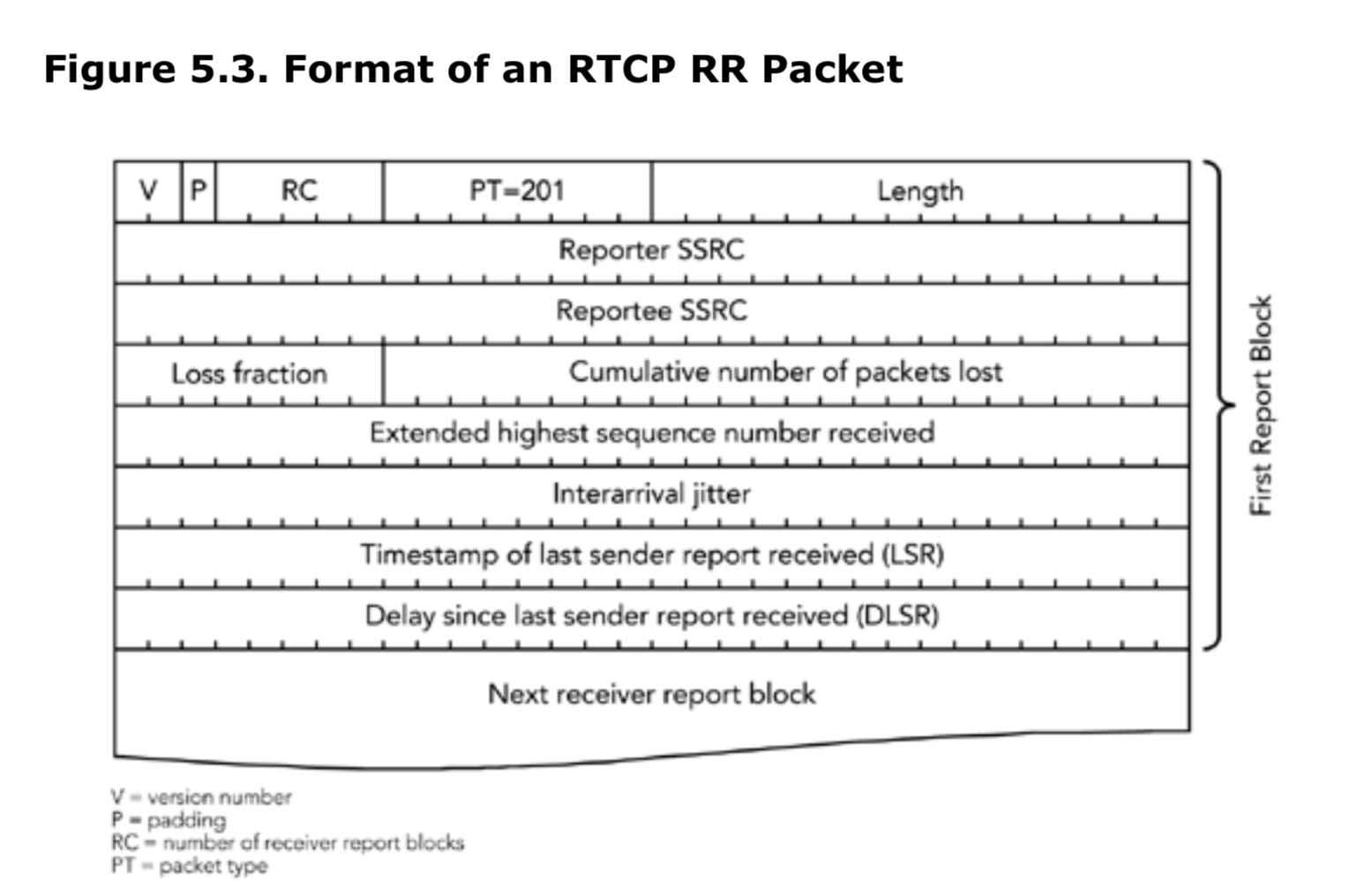
许多RTCP的包类型在固定部分的后面有一个条目列表(Item List),这个结构类似于接收者报告。此处需要注意,即使条目列表是空的,数据包的固定部分仍然保持不变,这也就是说,如果接收者报告中没有报告块(report block),那么要将数据包中的RC设置为0,长度设置为1,对应4个字节的固定RTCP包头,外加4个字节的报告者SSRC。
每一个报告块(report block)都是描述单个SSRC的接收质量,而报告者(reporter)在当前报告的间隔周期,接收从该同步源发过来的RTP包。每一个RTCP的RR包最多31个报告块。如果有超过31个活跃的发送者,那么接收者应该在一个聚合数据包中发送多个RR数据包,每个报告块有7个字段,总共24个字节。
Reportee(被报告者)SSRC标识此报告块相关的参与者。报告块中的统计数据,表示的是在生成RR数据包的参与者针对被报告方接收的数据包的接收质量。
累计丢包数是一个24位带符号的整数,它表示预期应该到达的包的数量,减去实际接收到的包的数量。预期的包数的定义是,最后接收到的序列号,减去接收到的计算周期内最小序列号。接收到的包的总数包括任何延迟到达或者重传过来的包,因此可能会大于预期的数量,因此累计丢包数有可能是负值。累计丢包数的计算区间是统计的整个会话期间的,而不是在每个间隔期间。如果在会话期间丢包的总数大于0x7FFFFF,那么此字段会在0x7FFFFF处于最大饱和值。
许多RTCP的统计信息是基于整个会话期间,而不是报告间隔的区间。但是,如果发生了SSRC冲突,或者序列号空间中存在一个非常大的间隙,使得接收者无法判断此字段是否已经被翻转,那么统计信息重置为0.
在同步源的RTP数据包中接收到的扩展最高序列号(extended highest sequence number)的计算,是在第四章《RTP数据传输协议》的序列号一节中讨论的方法。由于可能存在包重新排序的情况,所以并不一定是接收到的最后一个RTP包的扩展序列号。扩展序列号是基于会话计算的,而不是基于包间隔计算的。
丢包率(loss fraction)的定义是在这个报告间隔中所丢失包的数量,除以预期到达的数量。丢包比例以固定小数点数的形式表示,其中小数点位于字段的左边缘,相当于将丢包比例乘以256后得到的整数部分(例如,如果有1/4的数据包丢失,则丢包比例为1/4 x 256 = 64)。如果接收到的数据包数量大于预期的数量,因为存在重复数据包而导致丢包数量为负数,则丢包比例被设为零。
到达间隔抖动(Interarrival jitter)是对被报告者(Reportee)同步源发送的数据包的网络传输时间统计方差的估计。它是以时间戳单位衡量的,因此它像RTP时间戳一样用32bit无符号整数表示。
为了测量网络传输时间的方差,需要对传输时间进行测量。通常 ,由于发送者和接收者没有设置时钟同步,绝对的传输时间无法监测。相对传输时间是以相同的度量单位计算的,它计算了包到达时的RTP时间戳与接收者的RTP时钟之间的差值。为了进行这个计算,接收者需要为每个源维护一个时钟,并以相同的速率与该源的媒体时钟同步,来获取时间戳。(这个时钟可能是接收者本地的播放时钟,如果它与源的时钟运行速率相同的话)。由于发送者和接收者之间的时钟缺乏同步机制,相对传输时间包含一个未知的恒定偏移。然而,这并不是问题,因为我们只关心传输时间的方差,即接收者两个数据包的时间戳与离开发送者时的时间戳之间的差值。在后续的计算中,会减去由于不同步时钟引起的恒定偏移。
如果Si是来自包i的RTP时间戳,Ri是包i到达的时间(以RTP时间戳单位),那么相对传输时间就是(Ri - Si),对于两个包i和j,相对传输时间的差异可以表示为:
$$D(i,j) = (R_j - S_j) - (R_i - S_i)$$
注意,时间戳Rx 和 Sx是32bit无符号整数,而D(i,j)是有符号的整数,使用模运算来计算(在C语言中,这意味时间戳类型为unsigned int,假设 sizeof(unsigner int) == 4)).
每当收到一个数据包,使用该数据包与前一个数据包(不一定是按照序列号顺序的前一个数据包)的相对传输时间D(i,j)之差来计算到达间隔抖动(interarrival jitter)。根据以下公式,抖动是以滑动平均的形式存在。
$$ J_i = J_{i-1} + \frac{(|x_{i-1},i| - J_{i - 1})}{16} $$
无论何时生成接收报告,被报告对象SSRC的Ji的当前值就作为到到达间隔抖动(interarrival jitter)。
最后一个发送者报告(last sender report,LSR)时间戳是64位NTP(网络时间协议(Network Time Protocol))格式的时间戳中间的32bit,包含在最近从被报告者的SSRC接收到的RTCP的SR包中。如果SR没有收到,那么此字段可以设置为0.
自上次发送者报告起的延迟(delay since last sender report,DSLR)是从被报告者SSRC接收到最后一个SR数据包到发送此接收报告块之间的延时,以1/65,536秒为单位。如果没从该被报告者收到SR,则DLSR字段设置为0.
RR数据解析
RR包中的接收质量反馈不仅对发送者有用,对其他参与者和第三方监控工具也有用。通过RR包提供的反馈,发送者可以根据情况调整传输。此外,其他参与者可以确定当前问题是由自身引起的还是多个接收者共有的问题。网络管理人员可以使用仅接收RTCP包的监控器来评估网络性能。
发送者可以使用LSR和DLSR字段来计算它与每个接收者之间的往返时间(rtt)。当接收到一个与之相关的RR包时,发送者用当前的时间减去LSR字段,以得到发送SR到接收此RR之间的延迟。发送者然后再减去DLSR字段以消除接收者延迟带来的偏移,从而获得网络往返时间。该流程如图5.4所示,这是取自RTP规范的一个示例。(注意,RFC1889标准中有一个错误,此错误已经在RTP新版本中得到更正)
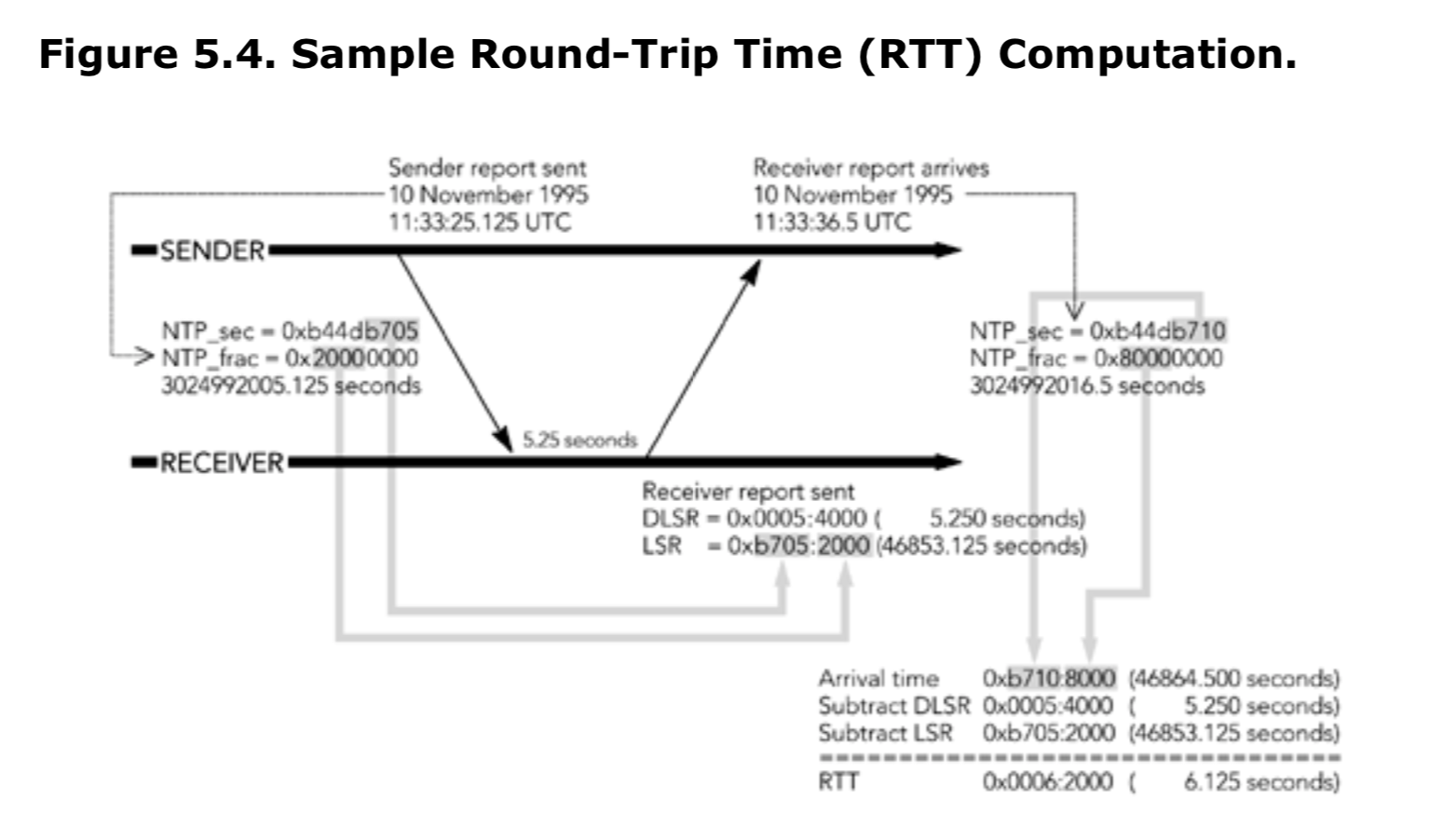
注意,计算结果是网络往返时间(RTT),它不包括任何在端上的处理时间。例如,接收者必须缓冲数据以用来消除抖动所带来的影响,然后才能去播放媒体(参见第六章《媒体采集、播放和时序》)。
由于延迟会阻碍交流,所以RTT在交互应用中是相当重要的。研究表明,当RTT超过300毫秒(这个时间是大概的,这取决于通话双方以及正在做的事情)时,很难进行对话。发送者可以利用RTT来优化媒体编码,例如通过生成包含较少数据的包来减少打包延迟,或者推动使用纠错码的方式(参见第九章《错误恢复》)。
丢包率(loss fraction)指示的是接收者短期的丢包,通过观察报告统计中的趋势,发送者可以判断丢包是短暂的还是长期的。RR数据包中的许多统计数据是累加值,以便进行长期均值的计算。通过对比两个RR数据包之间的差异,可以进行长期和短期的评估,从而让丢包报告更灵活。
例如,我们可以通过统计数据累加值得到的RR数据包间隔的丢包率,也可以直接上报丢包率。丢包的累加值的差值表示该时间间隔内的丢包数量,扩展后的最后序列号的差值,表示该时间间隔期望收到的包数。这两个值的比例就是丢包率。如果使用连续的RR包进行计算,这个数字应该等于RR包中的Loss Fraction字段,但是这个比率也给出了对一个或者多个RR包丢失时的丢包率的预估,当有重复的包时,它可能显示负的丢失率。使用Loss Fraction字段的优点是它可以用单个RR包提供丢包信息。这一点在大型会话中非常有用,在这些会话中,如果报告的间隔过大,可能会导致暂时没法收到两个RR数据包。
可以根据丢包率来选择适当的编码格式和纠错方式(请参阅第九章《错误恢复》)。特别是,当丢包率较高时,我们应该选择更具容错能力的格式,并且如果可能的话,还应该降低数据传输速率(因为大多数丢包是由于网络拥塞引起的;请参阅第二章《分组网络中的音视频通信》和第十章《拥塞控制》)
通过观察抖动字段的变化,还可以检测拥塞的发生:抖动的突然增加通常会先于数据包丢失的发生。这个效应与网络拓扑和流量数量有关,在高度复用的情况下统计,抖动增加与数据包拥塞发生之间的相关性会减少。
发送者应该注意,对抖动的预估应该取决于发送的数据包的间隔和时间戳的匹配。如果发送者延迟发送某些数据包,则该延迟应该被视为网络抖动的一部分。这可能是视频的一个问题,在视频领域,多个包通常产生相同的时间戳,但这些包是间隔传输而不是突然一起发送。当然,这也不一定是一个问题,因为对抖动的测量还会给出关于接收者所需要的缓冲空间的估计(因为缓冲空间需要适应抖动和发送延迟)。
RTCP SR:发送报告
除了接收者的接收质量报告,RTCP还传递了由最近发送数据的参与者发送的发送者报告(SR)数据包。这些报告提供了关于正在发送的媒体的信息,主要是为了使接收者能够同步多个媒体流,例如实现音视频的同步。
RTCP中SR包的格式
发送者报告的包类型为200,其格式如图5.5所示。有效负载包含一个24字节的发送者信息块,后面跟着0个或多个接收者报告块,由RC字段标识,类似于接收者报告报。当发送者也是接受方的时候携带接收者报告块。
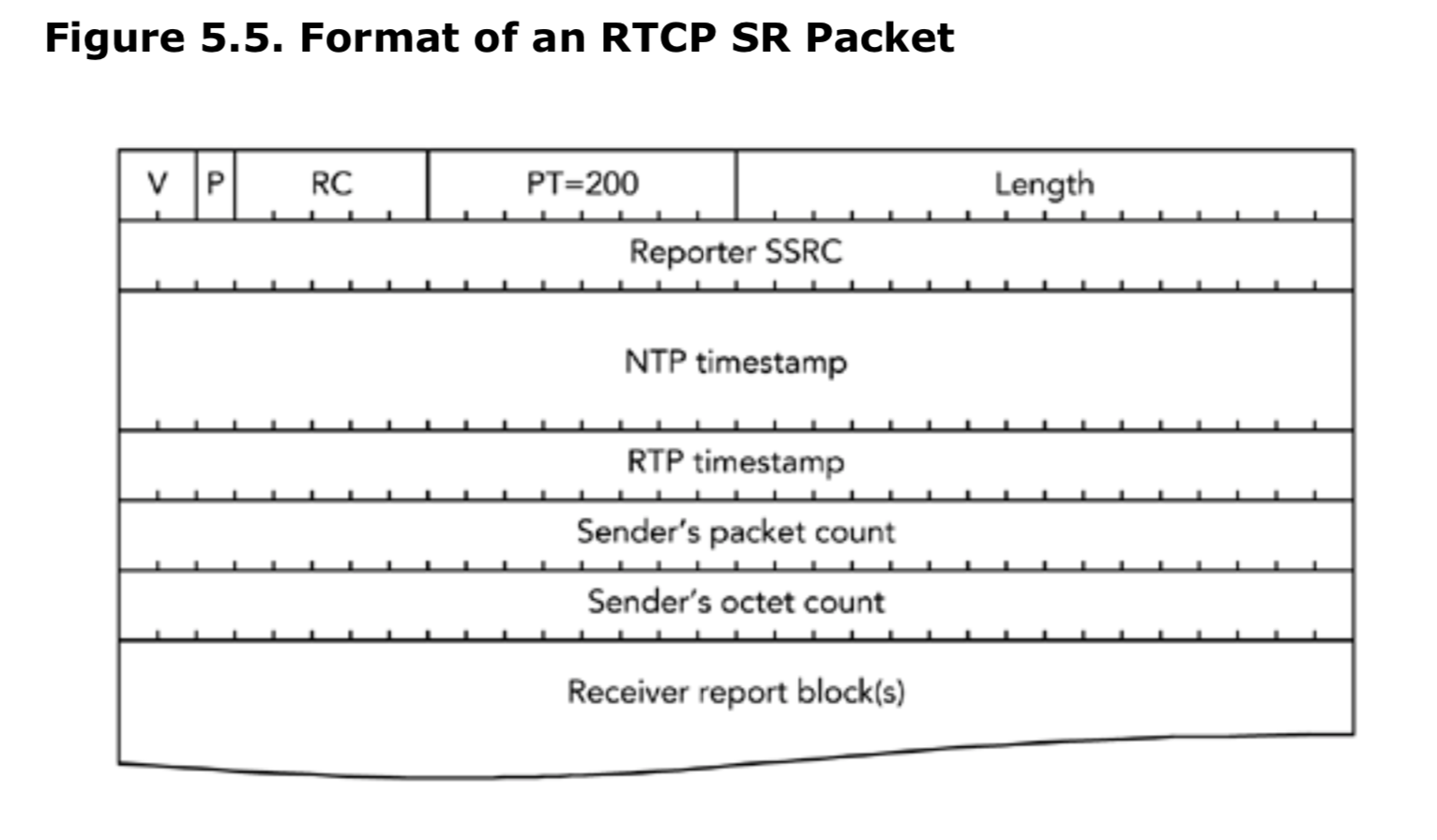
NTP时间戳是一个64位的无符号值,表示发送这个RTCP SR包的时间。它的格式是NTP时间戳,时间从1900年1月1日开始计算秒,低32bit代表秒的小数部分(fractions of second)(也就是64位定点值,二进制小数点位于32bit之后)。如果要将UNIX的时间戳(从1970年1月1日开始的秒数)转化为NTP时间,那么需要添加2,208,988,800秒。
虽然RTCP的SR包的NTP字段使用了NTP时间戳格式,但是,时钟并不见得必须要与网络时间协议(Network Time Protocol)同步,也不必具有任何特定的精度及稳定性。但是,对于要同步的两个媒体流的接收者,这些流必须要有相同的时钟。NTP协议有时对同步发送时钟很有用,但是只有当要同步的媒体流由不同的系统生成时才需要它。这些问题将在第七章《音视频同步》中进一步讨论。
RTP时间戳与NTP时间戳的对应时间是相同的,但是,它是以RTP媒体时钟的基准单位表示的。这个值,通常与前一个数据包的RTP时间戳不同,因为该数据包中的数据被采样已经经过了一段时间了。图5.6显示了SR包时间戳的一个示例。SR包具有与发送它的时间相对应的RTP时间戳,这与前后的RTP数据包都不相同。

发送者的包计数,是这个同步源自会话开始以来,生成的数据包的总数。发送者的字节计数是这些数据包的有效负载(playload)中包含的字节数(不包括包头或者填充)。
如果发送者改变SSRC(例如,由于产生冲突),则会重置发送者的包计数以及字节计数字段。如果发送者长时间运行,最终计数会产生翻转,但是这通常不会带来问题。如果使用32bit模运算,且两者之间的计数不超过2的32次方,则即翻转,从新的值中减去旧的值也将得到正确的结果(在C语言中,计数器的类型为无符号整型sizeof(unsigned int) == 4)。对发送者的数据包计数和字节计数,可以使得接收者能够计算发送者的平均数据速率。
SR数据的解析
应用程序可以通过SR信息,在不接收数据的情况下计算平均有效负载数据速率和平均包速。这两者的比值就是平均有效负载。可以假设数据包的丢失与数据包大小无关,通过将特定接收者接收的数据包数量乘以平均有效负载大小(或相应的数据包大小),可以得出该接收者可用的表现吞吐率(apparent throughput)。
时间戳用于将媒体时钟与已知的外部参考(NTP格式时钟)相互转换。这样可以实现音视频同步,详细解释请参考第七章所述。
RTCP SDES:源描述(Source Description)
RTCP还可以用来传递源描述(SDES)数据包,提供参与者认证和附加细节,例如位置、电子邮件地址和电话号码。SDES包中的信息通常由用户输入,并在应用程序的图形用户界面中显示,具体取决于应用程序的性质(例如,电话系统到RTP网关的系统可能使用SDES包传递呼叫者ID)。
RTCP中SDES包格式
源描述包在RTCP中类型定义为202,具体如图5.7所示。SDES包包含0个或者多个SDES项列表,具体个数由包头SC字段表示,每个SDES项包含一个源的信息。
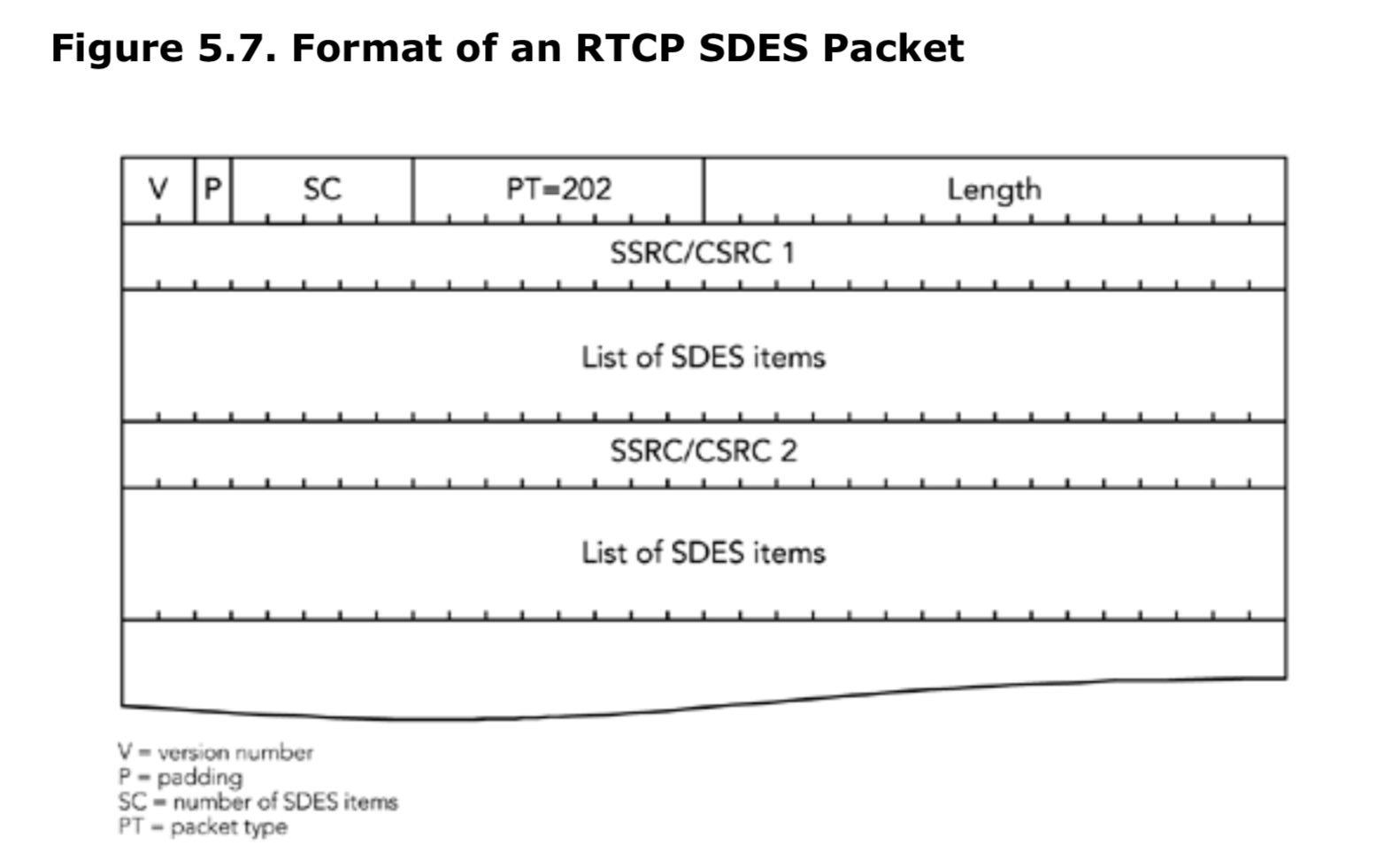
应用有可能生成SDES项为空列表的包,在这种场景下,RTCP公共包头中的SC和length字段都为0.在正常情况下,SC应该为1(混流器(mixers)和转换器(translators)聚合转发,所以产生的包会有较长的SDES列表)。
每个SDES项目列表从所描述的源的SSRC开始,然后是一个或者多个条目,具体格式参见图5.8所示。每个条目以类型和长度字段开始,然后是UTF-8格式的项目文本本身。length字段标识文本中有多少字节;文本不是以NULL结尾的。

每个SDES项中的条目都是以连续的方式打包到包中,没有分隔或者填充。条目列表(list of item)以一个或者多个空的字节结束,当解析到第一个字节为0类型的时候,意味着这个列表结束。0类型字节后面不会跟长度字节,但是如果需要填充,则包括其他的空字节,直到达到32-bit边界为止。这个填充(padding)与RTCP包头中的P位表示的填充是分开的。带有零项的列表(四个空字节)是有效的,但是没有意义。
在RTP规范中定义了几种类型的SDES条目,其他的条目可能在未来被定义。条目类型为0的是预留项,标识了条目列表的结束。其他标准条目类型有CNAME、NAME、EMAIL、电话、LOC、工具、注释和PRIV。
SDES的标准条目
CNAME(type=1)为每个参与者提供了一个规范名称。CNAME项提供了一个独立于同步源的稳定且持久的标识符(因为如果应用重启或发生SSRC冲突,SSRC会发生变化)。CNAME可以用于关联来自不同RTP会话的参与者的多个媒体流(例如,关联需要同步的语音和视频),以及在媒体工具重启时命名参与者。这是唯一的强制性的SDES条目,所有实现都需要发送SDES CNAME项。
CNAME是根据参与者的用户名和主机ID地址并通过算法计算而得。例如,如果作者是使用基于IPv4的应用,那么CNAME可能是csp@10.7.42.16。如果是IPv6应用,那么使用冒号分隔的数字形式的地址。如果应用运行在一个没有用户名概念的系统上,则只使用主机IP地址(无用户名或@符号)。
只要每个参与者只加入一个RTP会话(或一组要同步的相关会话),使用用户名和主机的IP地址,就可以生成一致的唯一标识符。如果要同步来自多个主机或多个用户的媒体流,则这些流的发送者必须联合起来生成一致的CNAME(通常是由一个参与者通过算法选择的名称)。
使用私有地址和网络地址转换(NAT)服务意味着,IP地址会存在全局不唯一的情况。为了使音视频同步和相关的RTP会话的其他用途能正确的被NAT操作,转换器(translator)还必须在穿过域边界(domain boundaries)时将RTCP CNAME转换为唯一的形式。这个转换在跨越多个RTP流时必须是一致的。
NAME(type = 2)表示参与者的名称,主要用于在参与者列表中显示,做为用户界面的一部分。这个值通常由用户输入,因此应用一般不假定它是任何值,特别的它不应该是唯一标识。
EMAIL(type = 3)负责传递参与者的电子邮件地址,格式符合rfc822 - 例如,jode@example.com。应用在发送前,应该验证电子邮件的值是否符合电子邮件的语法,然后再将其包含在SDES中。因为接收者不会假定这个地址的拼写是有效的。
PHONE(type = 4)表示参与者的电话号码。RTP规范建议用一个完整的国际电话号码,它带有一个加号来代替国际访问码(例如,+1 918 555 1212是一个美国的号码),但是许多实现允许用户输入这个值而不需要去校验格式。
LOC项(type = 5)表示参与者的位置。许多实现允许用户直接输入值,但是可以用各种格式来表示位置。例如,有一个实现方案与全球定位系统相连,并将GPS坐标做为位置信息。
TOOL项(type = 6)表示参与者使用RTP实现方案。此字段主要用来调试以及营销目的(marketing purposes)。它应该包含实现的名称和版本号。通常,用户无法编辑此字段的内容。
NOTE项(type = 7)允许参与者对任何事情进行简短陈述。对于“五分钟后回来”这样的便笺,它效果不错。但是由于RTCP包之间的潜在长时间延迟,它并不适用于即时通讯。
PRIV项(type = 8)是一种私有扩展的机制,用于定义实验的或特定于应用的SDES扩展。此项的文本,从一个字节长度的字段和前缀字符串开始,后面紧跟着值字符串来填充其余部分。其目的是初始化扩展前缀名和后面的扩展字段值。PRIV这个项很少被使用,如果定义了新的SDES类型,那么可以更有效的管理扩展。
CNAME是应用中必需填写的唯一SDES项(其他项可选)。实现中应该做接收任何SDES项的准备,即后续使忽略它们。SDES存在各种隐私问题(请参阅本章后面的《安全和隐私》一节),这意味着除非经过用户明确授权,否则在实现中不应发送任何额外的信息,仅限于CNAME项。
图5.9显示了一个包含CNAME和NAME项的完整RTCP源描述包的示例。请注意在SDES项list的末尾使用了填充(padding),以确保数据包是32bits的倍数。
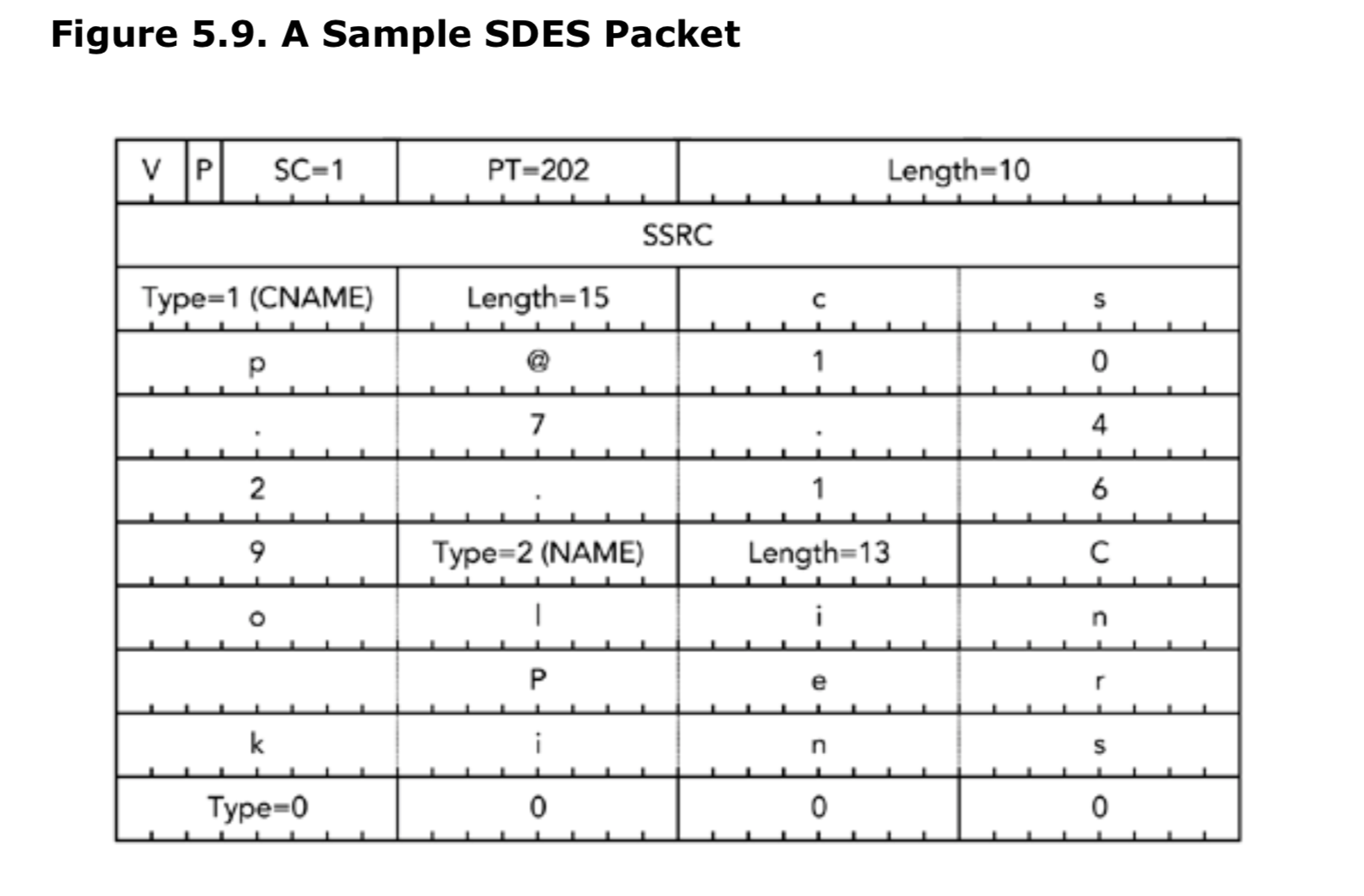
解析器(parser)问题
在解析SDES包的时候,有三点需要注意:
- SDES条目的文本最后不是以null作为结尾的,这也就是说在以null为结尾的字符串的语言中操作SDES条目需要特别小心。例如,在C语言中,应该使用strcpy()操作,因为它允许拷贝指定长度的字符串(使用srtcpy很危险,因为文本不是以null结尾)。如果不小心使用,非常容易造成缓冲区溢出,就很严重了。
- SDES条目的文本使用UTF-8编码,本地字符集在使用前需要转换。在使用前应该先查询本地系统使用的语言环境,之后再在系统字符集和UTF-8之间进行转换。很多应用会在不经意间生成错误的字符并填充到SDES包中。实现中要对这种错误做容错,并使其更加健壮(例如,如果使用不正确的字符集,会导致UTF-8解析出无效的Unicode字符)。
- SDES项的文本由于可能被用户操作,所以不能相信其具有安全性。特别是它还可能包含一些有意想不到的副作用的通配符(metacharacters)。例如,一些用户使用脚本语言允许触发通配符并进行指令替换,这种方法可以使攻击者有办法执行任意的代码。所以,实现中应该采取措施确保安全的处理SDES数据。
RTCP 释放连接(bye) : 成员控制
RTCP通过RTCP BYE数据包提供了松散的成员控制,RTCP BYE表示参与者已经离开了会话。当参与者离开会话或者更改其SSRC(例如由于冲突)时,会生成一个BYE数据包。由于BYE数据包在传输中可能会丢失,并且某些应用程序不会生成它们,因此接收方必须准备好在一段时间内没有收到某个参与者的消息时进行超时处理,即使没有收到该参与者发送的BYE数据包。
Bye数据包的重要性在一定程度上取决于应用。它仅表示一个参与者准备RTP会话,但是参与者之间可能存在额外的信令连接关系(例如,SIP、RTSP或H.323)。RTCP BYE包不会终止参与者之间的任何其他关联关系。
Bye包的标识类型为203,其格式如图5.10所示。公共的RTCP包头中的RC字段表示SSRC标识符的数量。存在为0的可能性,标识为0时无效。在接收到Bye包时,应该假设发送源已经离开了会话,并忽略来自该源的后续的任何RTP和RTCP包。但是,当收到Bye包之后,需要为此参与者保留一段时间的连接状态,因为要允许延迟到达的数据包被接收到。

本章后面的《参与者数据库》一节,专门对参与者超时和RTCP Bye包相关的状态维护的问题进行了说明。
Bye包还可以包含表示离开会话原因的文本,适合在用户界面中显示。然而,这个文本是可选的,我们在实现过程中需要接收它(即使文本可能会被忽略)。
RTCP APP:应用定义的RTCP包
最后一类RTCP包(APP)允许应用来自己定义扩展。它的包类型为204,格式如图5.11所示。应用定义的包名(application-defined packet name)由4个字符组成唯一的标识,每个字符都得从ASCII字符集中选择,并区分大小写。建议选择包名称来匹配它所代表的应用,并由应用来协商子类型值的选择。包其余部分被用于应用的特定需求。
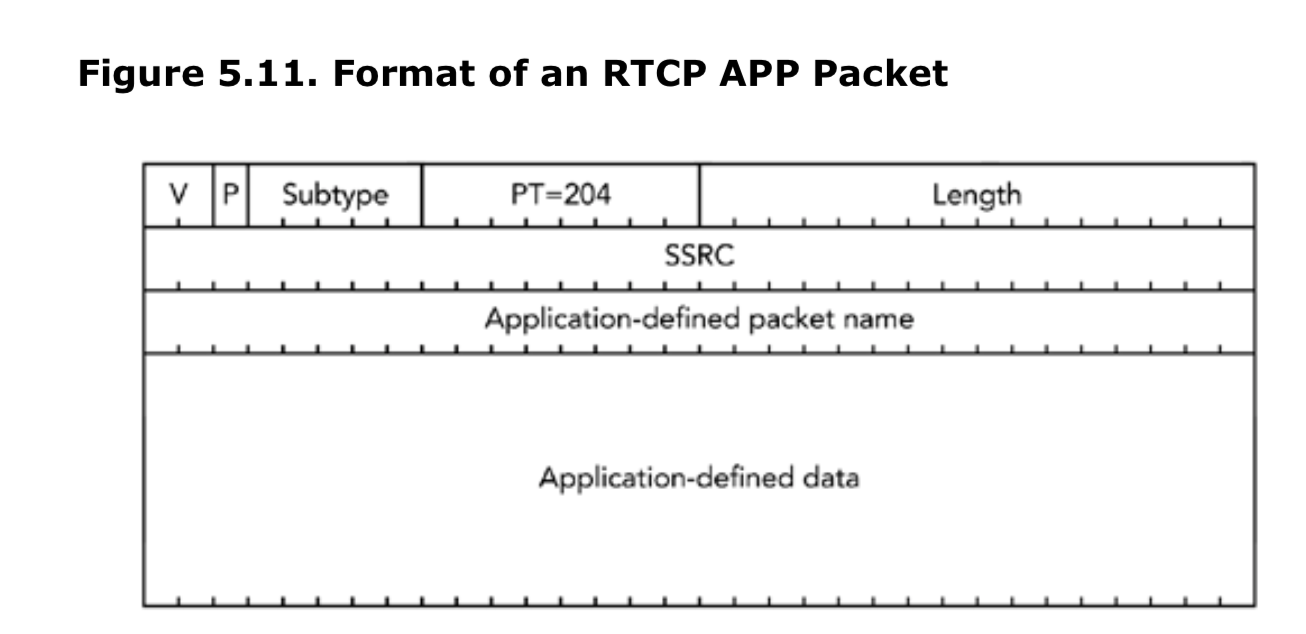
应用自定义的包用于RTCP的非标准扩展和验证新特性。目的是,验证者首先使用APP来验证新特性,然后如果新特性有广泛的用途,那么就注册为新的包类型。一些应用生成的包或实现方案,应该忽略识别不出来的应用包。
组包(Packing)问题
如前所述,RTCP包不会单独发送,而是组包成一个聚合数据包进行传输,下面详细介绍下复合包的组包规则和结构。
如果生成复合RTCP包的参与者是活跃的数据发送者,那么该复合包必须以RTCP SR包开始。否则必须从RTCP RR包开始。即使还没有发送或接收数据,在这种情况下,SR/RR包不会包含接收者的报告块(包头字段RC为0)。另一方面,如果从多个源接收数据,并且报告过多,无法将它们放入一个SR/RR包中,则复合RTCP包应以一个SR/RR包开始,后面跟着多个RR包。
在SR/RR数据包之后是一个SDES数据包。该数据包必须包含一个CNAME项,也可以包含其他项。其他(非CNAME)SDES项的包含频率由使用的RTP配置文件决定。例如,音频/视频配置文件指定每发送三个复合RTCP数据包时可以包含其他项,在该时间窗口内,以八个包为一周期,其他字段只能在最后一个包含。其他配置文件可能有不同的选择。
当准备好开始传输数据后,Bye包必须做为最后一个数据包发送。要发送的其他RTCP包可以按任何顺序。这些严格的排序规则,旨在使数据包的校验更容易,因为错误的数据包,大概率不会满足这些约束。
在生成复合RTCP包时,一个潜在的问题就是如何处理大量活跃发送者的会话。如果存在超过31个活跃的发送者,那么有必要在复合包中增加额外的RR包。可以根据需要重复此过程,直到达到MTU的上限。如果发送者太多,以致于接收者报告不能被MTU容纳,则必须忽略某些发送者的接收报告。如果出现这种情况,那么被忽略的报告,应该在生成的下一个复合包中被包含(要求接收者跟踪每个间隔中报告的源)。
当包中包含的SDES条目超过最大包大小时,也会出现类似的问题。在决定是包含额外接收报告还是包含源的描述信息之间需要权衡,需要根据实际情况进行考虑。
有时需要将一个复合RTCP包填充并扩展其原始大小。在这种情况下,填充只是添加到复合包中的最后一个RTCP包中,最后一个包中的P位(P bit)被设置为1。填充是某些实现中的常见问题之一,本章的后续部分将在“包校验”一节中讨论这个问题。
安全与隐私
在使用RTCP过程中,涉及到许多隐私问题,尤其是在源描述包中。尽管这些信息包是可选的,但是它们的使用可能会暴露个人重要的信息。因此,应用程序在发送SDES信息之前,应该事先告知用户。
使用SDES CNAME包是一个例外,因为这些包是强制性的。在CNAME包中包含IP地址会存在一个潜在的问题。不过包的IP头也包含相同的信息。由于RTP包会通过NAT转发,所以IP协议头中的地址转换,也应该在CNAME中的地址上进行。但在实践的过程中,许多NAT的实现时,并不知道上层协议是RTP,因此会存在内部IP地址泄露的问题。
一些接收者可能不希望对方知道他们的存在。如果这些接收者完全不发送RTCP包,那是可以的,但这样做将阻止发送方使用质量信息来调整传输策略, 来适配他们的网络特性。
为了实现媒体流的保密性,可以对RTCP包进行加密,当加密时,每个复合包包含一个额外的32bit随机前缀,如图5.12所示,来避免明文攻击。
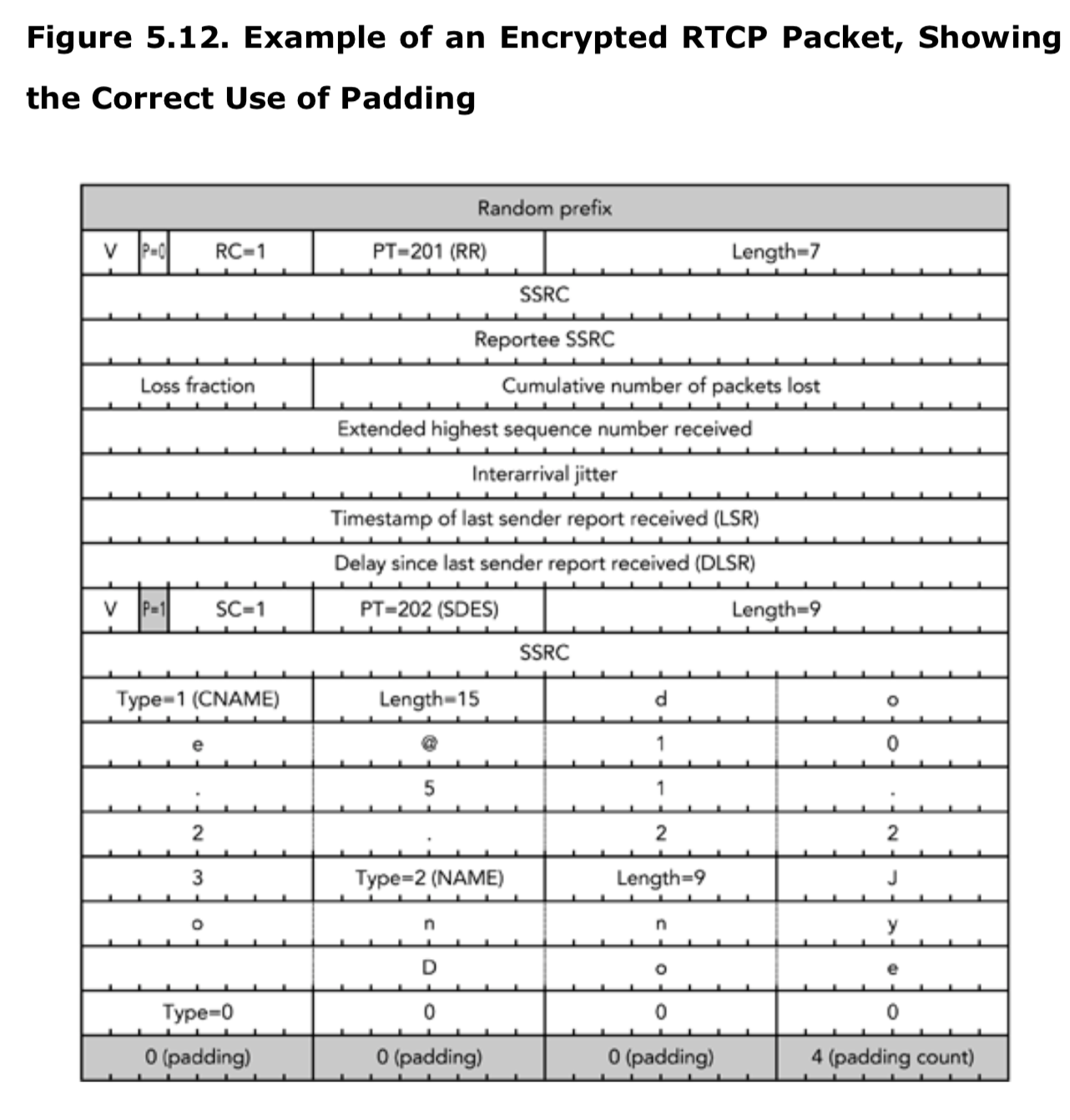
隐私和安全会在第13章《安全注意事项》中进行详细的讨论。
包校验
确认接收到的数据包是RTP还是RTCP非常重要。如前所述,封包规则允许对RTCP包进行严格的校验。成功验证RTCP流可以保证应用对RTP流的校验也是有效的,但这并不意味着RTP包的校验可以忽视。
List 5.1 展示了校验过程的伪代码,以下是要点:
- 所有的包必须是复合的RTCP包。
- 所有包的版本号必须等于2
- 复合包中的第一个RTCP包的包类型必须等于SR或者RR
- 如果需要填充,只添加到复合包中的最后一个包。复合RTCP包中所有的其他包的填充标志位必须为0.
- 各个RTCP数据包的长度字段,必须总计接收到的复合RTCP数据包的总长度。
因为未来可能会定义新的RTCP包类型,所以验证过程不应该要求每个包类型必须是RTP规范定义中的五种包类型之一。
List5.1 包校验的伪代码
validate_rtcp(rtcp_t *packet, int length)
{
rtcp_t *end = (rtcp_t *) (((char *) packet) + length); rtcp_t *r = packet;
int l=0;
int p=0;
// All RTCP packets must be compound packets
if ((packet->length+ 1) * 4) == length)
{
... error: not a compound packet
}
// Check the RTCP version, packet type, and padding of the first
// in the compound RTCP packet...
if (packet->version != 2)
{
...error: version number != 2 in the first subpacket
}
if (packet-> p != 0)
{
...error: padding bit is set on first packet in compound
}
if ((packet->pt != RTCP_SR) && (packet->pt != RTCP_RR))
{
...error: compound packet does not start with SR or RR
}
// Check all following parts of the compound RTCP packet. The RTP
// version number must be 2, and the padding bit must be zero on
// all except the last packet.
do
{
if (p == 1)
{
...error: padding before last packet in compound
}
if (r-> p)
{
p = 1;
}
if (r-> version != 2)
{
...error: version number != 2 in subpacket
}
l += (r->length + 1) * 4;
r = (rtcp_t *) (((uint32_t *) r) + r->length + 1);
} while (r < end);
// Check that the length of the packets matches the length of the
// UDP packet in which they were received...
if ((l != length) || (r != end))
{
...error: length does not match UDP packet length
}
...packet is valid
}
一个很容易犯的错误,会导致数据包不能通过有效性校验:当你在超出复合RTCP数据包的自然长度时进行填充时,你需要确保填充只添加到复合中的最后一个数据包。而实现者填充添加到最后一个数据包中,但在错误的将复合包中的第一个数据包的P位设置为1。正确的做法是P位只能在最后一个数据包中设置。
通过包类型字段,可以检测到RTCP包被错误地发送到RTP端口上的情况。标准的RTCP包在高位封装包的类型值,如果RTCP包被错误地发送到RTP端口,那么高位的包类型字段就会落在RTP包头的M位上。去掉高位后,标准的RTCP包类型对应于RTP有效负载类型范围在72到76之间。这个范围在RTP规范中被保留,不会用于传输有效的RTP包,因此如果检测到这个范围内的数据包,意味着流被错误地发送。同样地,通过包类型可以区分发送到RTCP端口的RTP包,因为它们的类型超出了RTCP包类型的有效范围。
参与者数据库(Participant Database)
RTCP会话中的每个应用将维护一个关于参与者和会话自身信息的数据库。RTCP时序从会话信息中获得,会话信息将被存储为一组变量:
- RTP带宽 -- 在应用启动时需要配置的常见会话带宽
- RTCP带宽占比 -- RTCP报告在RTP带宽中的百分比。通常为5%,但是可以通过修改配置文件的方法来更改这一比例(也可以配置为0%,但是这并不意味着不传输RTCP数据包)。
- 该参与者发送和接收的所有RTCP数据包的平均大小
- 会话中成员的数量,该参与者上次发送RTCP数据包时的成员数量,以及在前一段报告间隔期间发送RTP数据包的成员比例。
- 程序最后一次发送RTCP包的时间,以及下一次预定的传输时间
- 一个标志位,指示了自发送最后两个RTCP数据包以来,程序是否发送了任何RTP数据包。
- 一个标志位,表名实现何种RTCP数据包。
此外,实现时还需要维护RTCP SR包中包含的变量:
- 发送的RTP数据的包和字节数
- 使用的最后一个序列号
- 正在使用的RTP时钟与NTP格式时间戳之间的对应关系
会话数据结构适合存储包含这些变量的信息:正在使用的SSRC、程序的SDES信息以及RTP和RTCP套接字的文件描述符。另外,会话数据结构还应该包含一个数据库,用于保存每个参与者的信息。
实现方面,可以简单的存储会话数据的C语言结构体,以及面向对象语言中的类。除了参与者特定的数据之外,结构体或类中的每个变量都是一个简单的类型:整型、文本字符串等。接下来描述参与者特定数据的格式。
正确生成RTCP包,每个参与者需要跟踪会话中其他成员的状态。一个好的设计会使参与者数据库成为系统运行的关键组成部分,数据库不仅包含RTCP相关信息,还包含每个参与者的完整状态。参与者数据库可能包含以下信息:
- SSRC标识符
- 源描述信息:CNAME是必须的;以及其他可能包含的信息(注意,这些值不是以null结尾的,在处理他们需要注意)
- 接收质量统计信息(丢包和抖动),以生成RTCP RR包。
- 从发送者报告收到的信息,以允许音视频同步(见第七章)。
- 最后一次接收到该参与者的信息,这样不活跃的参与者可以做超时处理
- 一个标志位,标识了该参与者是否在当前RTCP报告间隔内发送了数据
- 媒体播放缓冲区,以及所需要的任何编解码器的状态(参见第六章《媒体采集、播放和时序》)。
- 信道编码和错误恢复所需要的任何信息 -- 例如,在解码之前等待接收修复包的数据(参见第八章《错误隐藏》和第九章《错误恢复》)。
在RTP会话中,成员由其同步源标识符表示。因为可能存在许多参与者,并且他们的访问顺序很随机,所以参与者数据库的数据结构应该是一个哈希表,由SSRC标识符索引。在只处理单一媒体格式的应用中,这是足够的。音视频同步也需要具备根据它们的CNAME查找其源的能力。因此,参与者数据库应使用双哈希表索引结构;一次使用SSRC作为索引键,一次使用CNAME作为索引键。
在一些实现中,选择SSRC标识符时,使用不完全随机数生成器。这意味着一个简单的哈希函数 -- 例如,使用SSRC的最低几位做为表的索引 -- 可能导致不平衡和低效的操作。尽管SSRC的值应该是随机的,但是他们应该与高效的哈希函数一起使用。有些人建议使用SSRC的MD5散列做为索引的基础,尽管这可能被认为有点过了。
在收到来自参与者验证过的包之后,应该将参与者添加到数据库中。这个验证的步骤很重要:除非确定参与者是有效的,否则程序不应为参与者创建状态。以下是一些指导方案:
- 如果接收到一个RTCP包并进行了校验,则应该将参与者输入到数据库中。对RTCP包的有效性检验很严格,伪造数据包是很难的。
- 除非是收到多个带有连续序列号的包,否则,不能只根据RTP包进行录入。对单个RTP包的有效性检验是不可靠的,而伪造的无效数据包有可能满足测试。
这意味着我们在实现过程中应该维护一个附加的轻量级的源的临时列表(仅仅接收到一个RTP包的源)。为了防止伪造的RTP和RTCP数据源占用太多内存,这个表应该有个主动超时机制,并应有固定的最大容量。很难防止攻击者故意生成许多不同的源来耗尽接收者的所有内存,但是这些预防措施可以防止在接收到错误定向的非RTP流时,意外的耗尽内存。
有效RTP包中的每个CSRC(贡献源)也算一个参与者,应该添加到数据库中。你应该期望只收到CSRC中的参与者的源描述信息(SDES)。
当将参与者添加到数据库时,应用还应该更新会话级别的成员计数和发送者百分比(sender fraction)。添加一个参与者也可能导致RTCP前向重估(forward reconsideration),稍后将对此进行讨论。
在收到Bye包或在指定的非活跃期(specified period of inactivity)后,可以将参与者从数据库中删除。这听起来很简答,但是有几个微妙的地方需要注意。
由于不能保证接收到数据包的顺序,因此可能在来自源的最后一个数据包被收到前,提前接收到Bye数据包。为了防止状态被破坏后,又重新建立连接,参与者应该在收到bye数据包之后将其标志为已离开,并且其状态应该保留几秒钟(本书作者在实现中使用的是固定2秒的延迟)。重要的一点是,延迟要比最大的期望重排序(expected reordering)和媒体播放延迟都大,以便使延迟数据包和播放缓冲区中的任何数据都能在延迟期间到达。
如果源在报告间隔期间内,未被收到超过5次消息,就可以被置为超时。如果报告间隔小于5秒,那么这里使用5秒做最小值(即使在发送RTCP包时使用更小的间隔)。
当收到一个Bye数据包或某个成员超时时,将发生RTCP的逆向重估(reverse reconsideration takes place),本章后面的《Bye重处理》一节,会对此进行描述。
时序规则
每个参与者发送RTCP数据包的速率都是不固定的,会根据其会话的大小和媒体流的格式而变化。这么做的目的是将RTCP流量总量限制在一个固定的比例(通常是会话带宽的5%)。当会话增加时,每个参与者发送RTCP数据包的速率会降低,从而实现上述的目标。在双方使用RTP拨打电话时,每隔几秒会发送一次RTCP报告;在有成千上万参与者的会议中(例如,一个因特网无线电台)每个听众的RTCP报告间隔可能是几分钟。
每个参与者根据本书后面描述的规则决定何时可以发送RTCP包。遵循这些规则非常的重要,特别是可能用在大型会话场景中的程序,如果实现了正确的规则,RTCP可以扩展到具有数千个成员的会话。否则,RTCP的流量将随着成员数的增长而线性增长,最终将导致严重的网络拥塞。
报告时间间隔
复合的RTCP包会使用随机定时器周期性发送。发送RTCP包之间每个参与者的平均等待时间称为报告间隔。它是根据以下几个因素计算的:
-
RTCP带宽的分配是一个固定的分配策略 ,通常是会话带宽的5%。会话带宽是会话期望的传输数据的速率;通常是单个音频或视频数据流的比特率,乘以同时发送者的典型数量(typical number)。会话带宽在会话期间是固定的,并在RTP应用启动时做为参数传递过去。分配给RTCP的会话带宽比例,可以根据使用中的RTP配置文件而变化。重要的是会话所有成员使用相同的比例(same fraction),否则某些成员的状态可能会过早的超时。
-
发送和接收的RTCP数据包的平均大小。平均大小不仅包含RTCP数据,还包括UDP和IP包头的大小(即,实现一个典型的IPv4,每个包需要添加28个字节)。
-
参与者的总数以及参与者中发送者的比例 这需要实现一个所有参与者的数据库,标记它们是否是发送者(也就是说从他们那里收到了RTP包或者RTCP SR包)还是接收者(如果只收到了RTCP RR、SDES或者APP数据包)。前面的“参与者数据库”一节对此进行了详细的说明。
为了防止在没有发送数据时,就发送SR包的错误,监听数据的参与者应该只在收到数据包后,才将另一个参与者视为发送者。只发送数据且不监听他人数据(如媒体服务器)的程序可以使用RTCP SR包做为发送者的标识,但是它应该验证包和字节计数字段为非零,并且是每个SR包的这些字段都有变化。
如果发送者的数量大于零,但不到参与者总数的四分之一,那么报告时间间隔取由协议决定,报告间隔被设置为,发送者的数量乘以RTCP数据包的平均大小,再除以分配给RTCP带宽的25%。
If ((senders > 0) and (senders < (25% of total number of participants))
{
If (we are sending)
{
Interval = average RTCP size * senders / (25% of RTCP bandwidth)
}
else
{
Interval = average RTCP size * receivers / (75% of RTCP bandwidth)
}
}
如果没有发送者,或者超过四分之一的成员是发送者,则报告间隔计算为RTCP数据包的平均大小乘以成员总数,再除以所需的RTCP带宽:
if ((senders = 0) or (senders > (25% of total number of participants)) {
Interval = average RTCP size * total number of members / RTCP bandwidth
}
这些规则确保发送者可以占用很大一部分RTCP带宽,至少占到总RTCP带宽的四分之一。因此,对发送者进行音视频同步和识别RTCP所需的数据包,可以相对较快的被发送,同时还有富余的带宽允许接收来自接收者的报告。
计算出的间隔会与绝对最小间隔进行比较,该最小间隔默认设置为5秒。如果时间间隔小于最小间隔,那么就把它设置为最小间隔。
If (Interval < minimum interval)
{
Interval = minimum interval
}
在某些情况下,希望发送RTCP的频率超过使用默认最小间隔。例如,如果数据率很高,而应用需要更及时的接收质量统计数据,则需要一个较短的默认间隔。最新修订版的RTP协议规范,允许在这种情况下减少最小间隔。
Minimum interval = 360 / (session bandwidth in Kbps)
``` c++
对于大于72bps的会话带宽,最小间隔可减小至小于5秒。在使用最小间隔时,重要的一点是要记住,一些参与者可能仍然在使用默认的5秒,在决定是否因为参与者处于不活跃状态而算其超时,要考虑到这一点。
计算出的间隔是RTCP数据包之间的平均时间。然后使用下面描述的传输规则,将该值转换为每个数据包实际发送的时间。每当会话中参与者的数量发生变化,或者发送者的比例发生变化时,都应该重新计算报告间隔。
### 基本传输规则
当应用启动时,根据对报告间隔的初始预估,安排第一个RTCP包进行传输。当发送第一个包时,将调度第二个包,以此类推。数据包之间的时间是随机的,在报告间隔的1/2到1.5倍之间,这是为了避免与参与者报告产生同步,以免它们每次都同时到达。最后,如果这是发送的第一个RTCP包,间隔减半,以提供新成员加入的更快的反馈,从而计算下一次发送时间,如下所示:
``` c++
I = (Interval * random[0.5, 1.5])
if (this is the first RTCP packet we are sending)
{
I *= 0.5
}
next_rtcp_send_time = current_time + I
例程random[0.5,1.5]是在0.5到1.5之间产生一个随机数。在某些平台上,它是调用系统的rand()来实现;在其他平台上,像drand48()这样的调用可能会产生更好的随机源。
以基本的传输规则为例,考虑一个使用RTP-over-IP多播发送128Kbps的MP3音频的Internet电台,其听众为1000人。使用最小报告间隔(5秒)和RTCP带宽占比(5%)的默认值,假设RTCP数据包的平均大小为90字节(包括UDP/IP包头)。当一个新的听众成员启动时,它不会知道其他的听众,因为他还没有收到任何RTCP数据。它必须假设发送者是唯一的其他成员,并相应地计算其初始报告间隔。发送者(单一来源)已知成员(来源和这个接受者)的比例超过25%,因此计算报告间隔如下:
Interval = average RTCP size * total number of members / RTCP bandwidth
= 90octets * 2 /(5%of128Kbps)
= 180 octets / 800 octets per second
= 0.225 seconds
因为0.225秒小于最小值,所以使用5秒的最小间隔做为间隔。然后将这个值随机化并减半,因为这是要发送的第一个RTCP包。因此,第一个RTCP包在应用启动后1.25到3.75秒之间发送。
在启动应用和发送第一个RTCP包之间的这段时间内,将从会话的其他成员接收到几个接收者报告,从而允许程序更新预估的成员数量。这个更新会用于调度第二个RTCP包。
我们将在后面看到,1000个听众足以使平均间隔大于最小间隔,因此,从所有听众接收到RTCP数据包的总速率为 75% * 800字节/秒 / 90字节/数据包 = 6.66数据包/秒。应用在2.86秒之后发送它的第一个RTCP包,已知的用户大小大约是 2.86秒 * 6.66秒 = 19.
因为发送者的比例现在小于已知成员的25%,所以第二个包的报告间隔是这样计算的:
Interval = receivers * average RTCP size / (75% of RTCP bandwidth)
= 19 * 90 / (75% of (5% of 128 Kbps))
= 1710 / (0.75 * (0.05 * 16000 octets/second))
= 1710 / 600
= 2.85 seconds
再次,这个值被增加到最小间隔并被随机化。第二个RTCP包在第一个包之后2.5秒到7.5秒之间发送。
重复此过程,从发送第一个RTCP数据包到第二个RTCP数据包之间平均要监听到33个新的接收者,总共已知成员数为52。结果是平均间隔为7.8秒,由于大于最小间隔,因此可以直接使用。随后,在第二分组之后的3.9秒到11.7秒之间发送第三分组。数据包之间的平均间隔,随着其他接收者的发现而增加,直到收到完整的接收者为止。间隔的计算如下:
Interval = receivers * average RTCP size / (75% of RTCP bandwidth)
= 1000 * 90 /(75%of(5%of128Kbps))
= 90000 / (0.75 * (0.05 * 16000 octets/second))
= 90000 / 600
= 150 seconds
150秒的间隔,相当于每秒1/150 = 0.0066个包,如果有1000个监听器,则平均的RTCP接收速率为每秒6.66个包。
RTP的标准版本,仅使用这些基本的传输规则,虽然这些对于许多应用来说已经足够了,但是它们有一些限制,这些限制会在成员迅速变化的会话中会造成问题,重估(Reconsideration)概念的提出就是为了避免这些问题。
前向重估(Forward Reconsideration)
正如上一节所建议的,当会话比较大时,新成员需要一定数量的报告间隔,才能知道会话的总大小。在这个过程中,由于获取到的信息不完整,新成员发送数据包的速度要比“正确”的速度快(“correct” rate)。当许多成员同时加入时,这个问题就会变得非常严重,这种情况叫做“步进加入(step join)”。一个“步进加入”的连接可能发生的典型场景,就是在当应用同时自动启动多个参与者。
在“setp join”的情况下,如果只使用基本的传输规则,每个参与者将在初始预估为0参与者的基础上加入,并调度它的第一个RTCP包。它将在最小间隔的平均一半之后,发送该数据包,并且它将根据当时观察到的参与者数量,安排下一个RTCP数据包,可能是几百,甚至是几千个。由于对组大小的初始预估比较低,所以当所有参与者加入会话时,RTCP流量会激增,这可能会阻塞网络。
Rosenberg研究了这一现象,并报告了案例,在这个案例中,有一万名成员同时加入了一个会话。根据他的模拟,在这样的一个步进连接(step join)中,所有10000个成员都试图在开始的2.5秒内发送一个RTCP包,这几乎是预期速率的3000倍。这一的数据包骤长的极端情况将导致网络阻塞 -- 这并不是低速率控制协议所期望的结果。
持续更新参与者的数量和发送者比例,然后使用这些数字重估每个RTCP包的发送时间,可以解决以上问题。在预定的传输时间到达后,根据组的大小重新预估并计算间隔时间,并使用此值计算新的发送时间,如果新的发送时间,比现在要晚,则不发送数据包,而是修改此包的新的发送时间。
这是一个听起来很复杂,但是实现起来很简单的方案。只考虑基本传输规则的情况下,可以这样写伪代码:
if (current_time >= next_rtcp_send_time)
{
send RTCP packet
next_rtcp_send_time = rtcp_interval() + current_time
}
加上前向重估后,以上代码可以优化为:
if (current_time >= next_rtcp_check_time)
{
new_rtcp_send_time = (rtcp_interval() / 1.21828) + last_rtcp_send_time
if (current_time >= new_rtcp_send_time)
{
send RTCP packet
next_rtcp_check_time = (rtcp_interval() /1.21828) + current_time
}
else
{
next_rtcp_check_time = new_send_time
}
}
这里,函数rtcp_interval()是基于当前会话的大小的预估,返回报告间隔的随机抽样。注意,rtcp_interval()除以1.21828(欧朗常数 e - 1).这是一个会受补偿因子影响的重估算法(reconsideration algorithm),它最终会收敛到一个低于期望5%的带宽占比的值。
Rosenberg研究了这种现象,并报告了一次有10,000名成员参加会议的情况。 他的模拟显示,在这样的步进连接中,所有10,000个成员都尝试在前2.5秒内发送RTCP数据包,这几乎是所需速率的3,000倍。这样的数据包突发将导致极端的网络拥塞,这对于低速率控制协议而言并不是理想的结果。
作为另一个示例,考虑上一节“基本传输规则”中讨论的场景,其中一个新的听众,使用多播RTP的方式加入到一个已经建立的互联网电台。当听众加入会话时,第一个RTCP包,像之前一样被调度,在应用启动的1.25秒到3.75秒之间。当预定的传输时间到达时,就会出现差异:应用不是发送数据包,而是根据当前成员数量重新考虑发送时间。如前所述,假设一个随机的初始时间间隔为2.86秒,应用将从其他成员接收到大约19个RTCP包,新的平均时间间隔变为2.85秒:
Interval = number of receivers * average RTCP size / (75% of RTCP bandwidth)
= 19 * 90 / (0.75 * (0.05 * 16000 octets/second))
= 1710 / 600
= 2.85 seconds
结果小于最小值,因此使用最小值5秒,随机化并除以比例因子。如果结果值小于当前时间(在本例中是应用启动后的2.85秒),则发送数据包。如果不是,例如,新的随机值是5.97秒,则修改数据包发送时间为后者。
在新的计时器到期之后(本例中为应用启动后的5.97秒),重新开始处理。此时,接收者将从大约5.97秒 * 6.66/秒 = 40个其他成员处接收到RTCP数据包,重新计算的RTCP间隔为6秒(随机化和缩放之前)。此过程会重复的进行,直到重新预估的发送时间小于当前时间。此时发送第一个RTCP包,并调度第二个RTCP包。
重估(Reconsideration)是很容易实现的,建议在实现的过程中都要包括它,即使它只有在参与者达到几百人的时候才有显著效果。不管会议规模多大,或者同时有多少参与者加入,包含前向重估的实现都是安全的。只使用基本传输规则的实现可能会过于频繁的发送RTCP包,从而使得在大型会话场景中造成网络拥塞。
反向重估
如果步进接入(step join)存在问题,那么许多参与者快速离开时,我们可以合理地预期将会出现问题。基本的传输规则确实是这样,虽然问题不在于发送RTCP太频繁而导致拥塞,而在于发送不够频繁,导致参与者过早的超时。
当大多数(但不是所有)成员离开大型会话时,问题就出现了。结果是,报告间隔迅速缩短,可能从几分钟缩短到几秒。然而,使用基本的传输规则,虽然更新了超时间隔,但是在更新之后不会重新调度数据包。结果是那些没有离开的成员被标记为超时;它们的包在新的超时时间内没有到达。
这个问题的解决方法类似于步进(step join);当收到每个Bye数据包,更新参与者的预估数量,重新考虑下一个RTCP数据包的发送时间。与前向重估的不同之处在于,预估值会变得越来越小,因此下一个数据包的发送将比原来的发送时间更早。
当收到一个Bye数据包时,新的传输时间是根据Bye之后,仍然存在的成员比例,和在原计划传输时间之前的剩余时间来计算的。例程如下:
if (BYE packet received)
{
member_fraction = num_members_after_BYE / num_members_before_BYE time_remaining = next_rtcp_send_time – current_time next_rtcp_send_time = current_time + member_fraction * time_remaining
}
结果就是新的传输时间比原始的早,但是比当前时间晚。因此,包会被安排的足够早,以使得其余的成员不会超时,从而防止错误地将参与者数量的预估值降为0.
在实践中,反向重估可以显著减少由于过早超时而导致的问题,但不能完全解决问题。在某些情况下,在步进离开后,组成员的预估值可能会在短时间内降为零,但很快就会恢复到正确值。在重估的实现中,彻底解决这一问题的复杂性会超过其收益。
反向重估的实现是一个次要问题:它只是在有几百名参与者且成员迅速变化的会话中才会出现,而不实现它会导致错误的超时,但是不会造成全网范围的问题。
Bye包重估
在RTP标准中,希望离开会话的成员需要立即发送一个Bye数据包,然后再退出。如果许多成员立即离开,这可能会导致大量的Bye数据包,并可能导致网络拥塞(就像如果不用前向重估RTCP数据包在步进加入时发生的情况一样)。
为了避免这个问题,当前的版本中的RTP只允许在参与者决定离开时的成员小于50个时,才允许立即发送Bye数据包。如果超过50人,则成员在准备离开时,如果收到其他成员的Bye数据包,则应延迟发送Bye数据包,这个过程称作Bye数据包重估。
Bye重估与前向重估类似,但其是根据收到的报文数量,而不是根据其他成员的数量。一个参与者想要离开一个会话,它会暂停RTP/RTCP数据包的正常处理流程,并根据前向重估规则调度一个Bye数据包,就像没有其他成员,或者就像这是第一个要发送的RTCP数据包一样。在等待预估的传输时间时,参与者会忽略所有的RTC/RTCP包,除了Bye包。对接收到的Bye包进行计数,并且当调度的Bye数据包的传输时间到达时,基于该计数重估所接收到的Bye数据包。该过程将继续持续到发送Bye包,然后参与者离开会话。
正如这个描述所表明的,在发送Bye数据包之前的延迟依赖于离开的成员数量。如果只有一个成员决定离开,Bye将延迟1.026到3.078秒(基于5秒的最小报告间隔在减半,因为Bye包会被当做初始的RTCP包对待)。如果很多参与者决定离开,在决定离开会话和能够发送Bye包之间可能会有相当长的延迟。如果需要快速退出,不发送Bye包就可以安全退出,其他参与者最终对其按超时处理。
使用Bye重估是一个相对次要的决定,只有当许多参与者同时离开一个会话,并且参与者关心离开通知时,Bye重估才有用。离开大型会话而不发送Bye包是安全的,而不是去实现一个Bye的重估算法。
对重估算法的评论(Comments on Reconsideration)
重估算法规则的引入,使得RTCP能够扩展到成员迅速变化并且人数极多的会话中。作者建议所有的实现最好都包含重估算法,即使它们原本在极小规模的会议中使用。这样会避免产生一些设计者没有预见到的问题。
第一次读的时候,会感觉重估的规则复杂难以实现。实际上,只需要增加少量的代码。本书作者的RTP和RTCP的实现中大约包含了2500行C语言代码(不包括套接字和加密部分)。正向和反向重估部分的代码只有15行。Bye重估代码比较复杂,但是也只有33行,这显然不是最大的问题。
重估规则的正确运行,在很大程度上取决于大量参与者行为的统计均值。在大型会话中,单个错误实现的影响不会很大,但是许多错误实现的话,就可能会造成严重的拥塞问题。对于小的会话,更大程度是一个理论上的问题,但是随着会话体量的增加,糟糕的RTCP实现会被放大,并可能造成网络拥塞,从而影响AV的质量。
实现过程中常见的问题
RTCP在实现的过程中最常见的问题是与基本传输规则以及带宽计算相关的:
- 没有随参与者数量同比伸缩。固定的报告间隔,将导致流量随着成员数量的增加而线性增长,最终超过发送音视频数据的量,最终造成网络拥塞
- 缺乏报告时间间隔的随机性。使用非随机报告间隔的实现方案,可能会无意间同步发送报告,从而导致RTCP包突增,导致接收者阻塞。
- 忘记在带宽计算的过程中的网络底层协议的开销。在计算报告间隔时,所有数据包都要包含UDP和IP包头(典型的基于IPv4实现,28个字节大小)。
- 填充(padding)错误。如果需要填充,应该只添加到复合RTCP包中的最后一个包。
在测试一个RTCP的实现时,一定要使用多种场景。大型和小型会话都可能会测出问题,在这些会话中,可以设置成员快速变化,可以设置大多数的参与者是发送者,可以设置少部分参与者是发送者,还可以加入步进接入和退出机制,来测试会话。测试大型会话本就是复杂的。如果实现中可以构建一个独立于底层网络传输机制的系统,那么可以允许在单个测试机上模拟大型会话。
IETF 音视频工作组编写了一份RTP实现的测试策略文档,可以参考,这非常有帮助。
总结
本章着重描述了RTP的控制协议,RTCP。它由三部分组成: 1. RTCP包格式,以及生成复合包的方法 2. 将参与者数据库作为基于rtp应用的主要数据结构,及存储RTCP正确操作所需要的信息。 3. 控制RTCP包的时序规则:定期传输、适应会话大小和重估策略。
我们还简要讨论了安全性和隐私的问题(这些问题会在第十三章《安全性考虑》中深入讨论),及RTCP数据包的正确性校验中深入讨论。
RTP控制协议是RTP的一个组成部分,用于接收质量报告、源描述、成员控制和音视频同步。正确的实现RTCP可以显著的增强RTP会话,它允许接收者同步音视频以及识别会话的其他成员,并且允许发送者掌握足够的信息,以选择错误保护方案以实现最佳的通信质量。
第六章 媒体采集、播放和时序
- 发送者行为
- 媒体采集和编码
- RTP 包生成
- 接收者行为
- 包的接收
- 播放缓冲区
- 播放点自适应(adapting the playout point)
- 解码、混流(mixing)和播放
这一章我们不再讨论网络和协议,转入 RTP 系统设计。实现 RTP 需要兼顾很多功能,根据需求,有些是必须得,有些是可选得。本章主要讨论媒体采集、播放时序两个基本功能。后面章节描述了提高接收质量,减少资源开销的方法。
我们先讨论发送者的行为:媒体采集和编码、RTP 包封装以及底层的媒体时序模型。后面,主要讨论接收者,在不确定传输场景下,媒体播放以及时序恢复的问题。接收者最关键的部分是播放缓冲区是设计,本章的大部分内容都将集中在这方面的讨论。
需要牢牢记住的是,发送者和接收者在 RTP 的规范的允许下,实际可以有很多实现方案。这里讲的设计是其中一种考虑各种制约,折中的实现方案。实践中,应该根据特定的场景设计特定的方案(文献中描述了很多实现方案,例如:McCanne 和 Jacoboson 描述了一个RTP视频会议系统设计,这个设计有一定影响力)。
发送者的处理
如第一章 RTP 介绍中所述,发送者负责采集音视频数据(无论是实时采集还是来自文件),对音视频数据进行编码后封装 RTP 数据包传输。它还可以通过根据接收者反馈调整传输的媒体流的方式,进行纠错和拥塞控制。第一章中的图 1.2 显示了这个过程。
发送者首先将未编码的媒体数据 (音视频采样) 写入一个缓冲区,然后从中产生编码帧。帧数据可以用不同的编码算法进行编码,编码后的帧数据可能同时依赖之前和之后的数据。下一节,媒体的采集和编码,描述了这个过程。
被编码的帧会被分配一个时间戳和一个序列号,生成到 RTP 包,等待发送。如果一个帧信息太大,不能装到一个包中,它可能被分割成几个包进行传输。如果一个帧很小,可以将几个帧绑定到一个 RTP 包中。本章后面的《RTP 包的封装》一节,描述了这些功能,只有在有效负载(payload)支持的情况下,这两种功能才能实现。根据所使用的纠错方案,可以使用信道编码器来封装纠错数据包,或者在传输之前重新排序帧(第八章和第九章讨论了错误隐藏和错误恢复)。发送者将针对其封装的媒体流,以 RTCP 数据包的形式定期封装状态报告。发送者还将收到来自其他参与者的接收质量反馈,并可能使用这些信息来调整传输策略。RTCP 在第五章 RTP 控制协议中有详细描述。
媒体采集和编码
无论是传输音频还是视频,媒体采集过程在本质上是相同的:采集到未编码的数据,如果需要将其转换为合适的编码格式,然后调用编码器来封装编码帧。然后编码帧会传递到打包代码,并封装一个或多个 RTP 数据包。音视频采集相关的问题,将在接下来的两章中讨论,然后我么也会讨论对打包预先录制的内容所引发的问题。
音频的采集和编码
考虑到音频采集的特点,图 6.1 显示了在通用工作站上的采样过程:声音被采集、数字化并存储到音频输入缓冲区。输入缓冲区通常在收集到了固定数量的样本之后才能提供给上层逻辑。大多数音频采集 api 会以固定时长的帧,从输入缓冲区返回数据,直到采集足够的样本以形成完整的帧为止,在这个过程中 API 会被阻塞住。这会带来一些延迟,因为直到采样完最后一个样本(sample)之后,帧中的第一个样本才可用。如果我们可以选择,用于交互用途的应用程序,应选择最接近编码器一帧时长的缓冲大小(通常为 20ms 或者 30ms),来减少延迟。
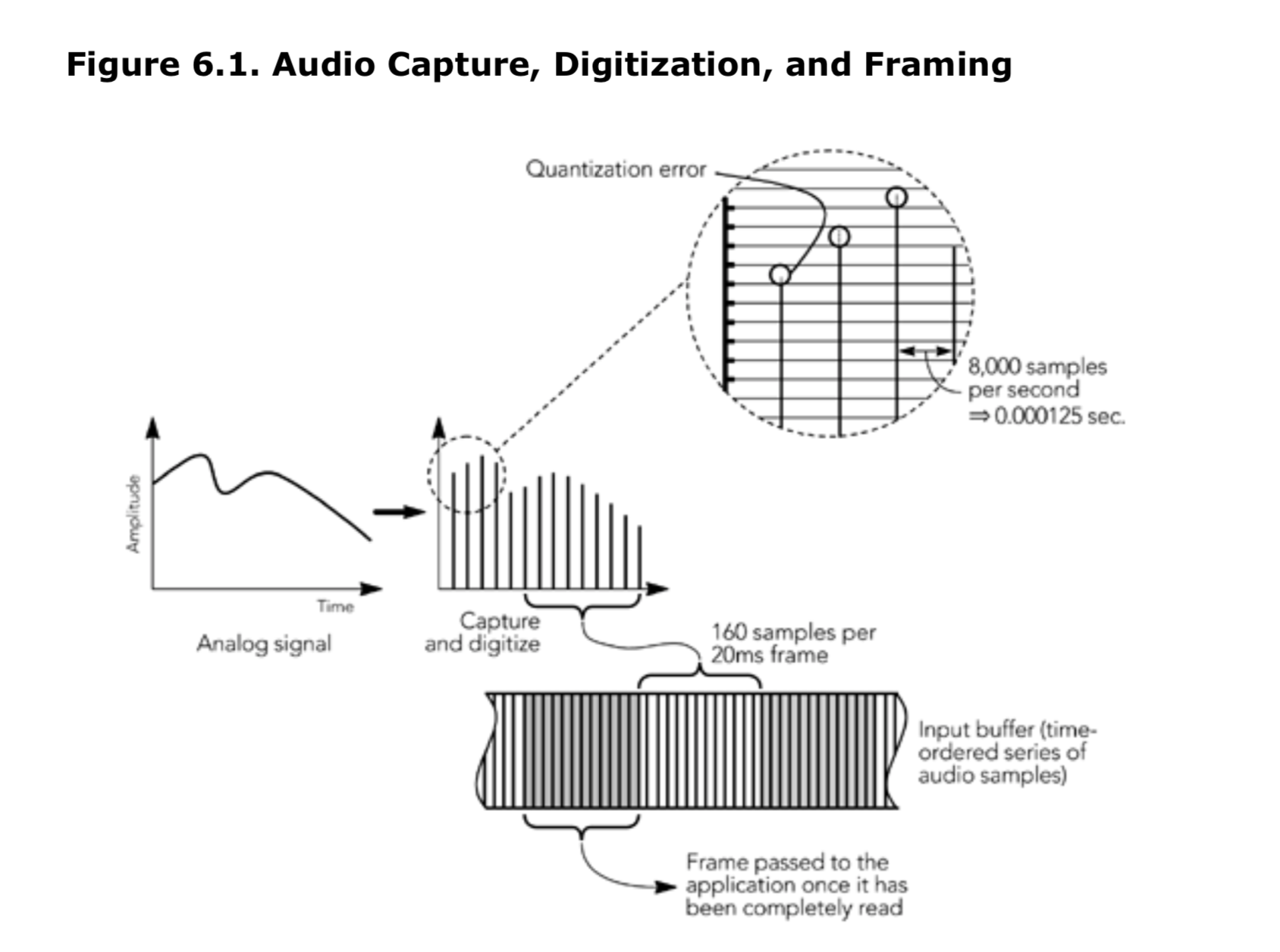
应用可以用不同的采样类型和采样率,从采集设备采集未编码的音频。常见的音频采集设备可以采样:
- 8bit、16bit或 24bit 的采样;
- 量化方式可以使用线性、μ-law 或 A-law,
- 采样率可以从 8000 到 96000 之间,
- 可以有单声道或多声道。根据采集设备的功能和编码器的不同, 在实际使用之前,还可以改变采样格式,例如更改采样率或更改量化方式从线性到 μ-law。转换音频格式算法,超出了本书的范围,标准的信号处理类书籍可以作为参考。
一种最常见的音频格式转换就是转换采样率,例如当采集设备是一个采样率,但是编码器设置的是另一种速率的时候(例如,该设备以 44.1KHz 固定速率运行,以支持高质量的 CD 播放,但是我们希望使用 8KHz 的语音编码进行传输)。虽说采样率可以直接以任意的数值进行转换,但是对于整数倍的采样率之间的转换,效率和准确度才是最高的。当选择音频硬件的采集模式时,应考虑采样率转换的计算要求。其他音频格式的转换,例如转换在线性量化和 μ-law 之间转换,开销会比较低,可以在软件中执行。
音频采样会传递到编码器进行编码。 根据编解码器的不同,状态可能会在帧(编码上下文)之间保持不变,必须与每个新的数据帧一起供编码器使用。 一些编解码器,尤其是音乐编解码器,其编码基于一系列未编码的帧,而不是孤立地基于未编码的帧。 在这些情况下,编码器可能需要传递几帧音频,或者可能在内部缓存帧并仅在接收到几帧后才产生输出。 一些编解码器会生成固定大小的帧作为其输出,产生可变大小的帧。 可变大小的帧通常根据所需的质量或信号内容从一组固定的输出速率中进行选择; 但是,实际上真正可变速率的很少。
许多语音编解码器通过静音抑制来执行语音活动检测,以检测和抑制仅包含静音或背景噪声的帧。 被抑制的帧不被发送,或者偶尔被低速率舒适噪声包所代替。 这样做可以大大节省网络流量,特别是如果使用统计多路复用的时候,则更能有效得利用有限容量的信道。
视频的采集和编码
通常,视频采集设备采集到是完整的视频帧,而不是返回逐行扫描线或隔行扫描的场。许多设备提供了以降低的分辨率对帧进行降采样或返回采集帧的子集的功能。帧可能具有一定分辨率的大小,并且采集设备可能会返回各种不同格式、颜色空间、深度和降采样的帧。
根据所使用的编解码器不同,可能需要先从采集格式转换编码器支持的格式,然后才能使用该帧的数据。 这种转换的算法不在本书的讨论范围之内,但是任何标准的视频信号处理书都将提供各种可能的方法,具体取决于所需的质量和可用资源。目前最常见的可能是在 RGB 和 YUV 颜色空间之间进行转换。 此外,色彩抖动和重采样也经常使用。 这些转换非常适合硬件加速,如许多处理器体系结构中存在的单指令多数据(SIMD)指令(例如,Intel MMX 指令,SPARC VIS 指令)。 图 6.2 说明了视频采集的过程,并以 YUV 格式采集的 NTSC 信号为例,在使用前将其转换为 RGB 格式。
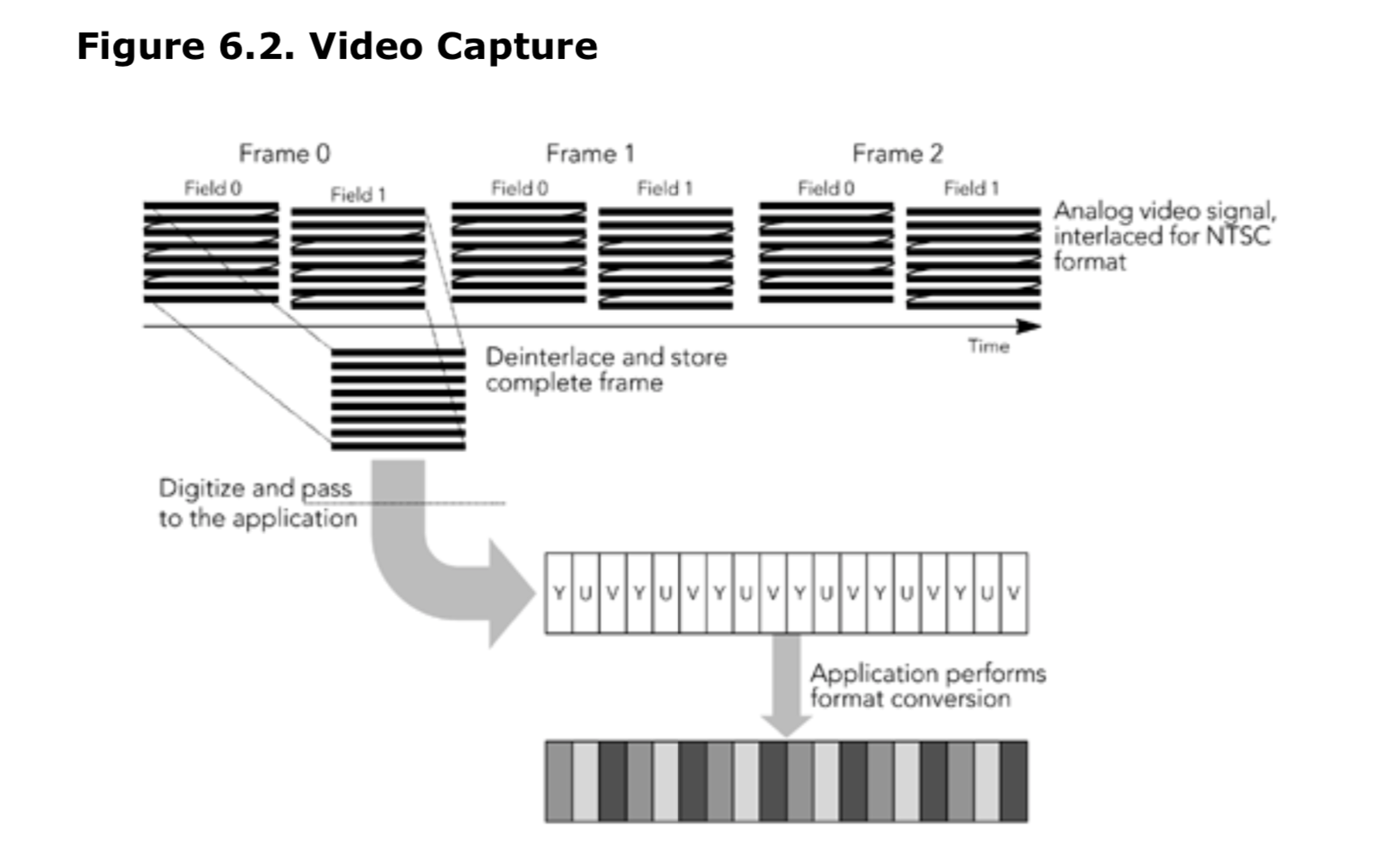
我们采集视频,加入缓冲区,然后再传递给编码器进行编码。缓冲区大小取决于编码方案;大多数视频编解码器使用帧间编码,每一帧都依赖于前后的帧。帧间编码可能需要编码器延迟特定的帧的编码,需要等待采集到它所依赖的帧为止。编码器将在帧之间维护状态信息,该信息必须与视频帧一起提供给编码器。
对于音视频,采集设备都可以直接产生编码媒体,而不是分为单独的采集和编码阶段。 这在专用硬件上很常见,但是某些视听工作站也具有内置编码功能。 以这种方式工作的采集设备可简化 RTP 实现,因为 RTP 实现的时候不需要包括单独的编解码器了,但是它们可能将适应范围限制为时钟偏移(clock skew)和/或网络抖动,如本章稍后所述。
无论媒体类型是什么以及如何编码,采集和编码阶段的产出都是一系列编码帧,每个编码帧都有关联的采集时间。 这些帧被传递到 RTP 模块,以进行打包和传输,如下一节《RTP 包的封装》所述。
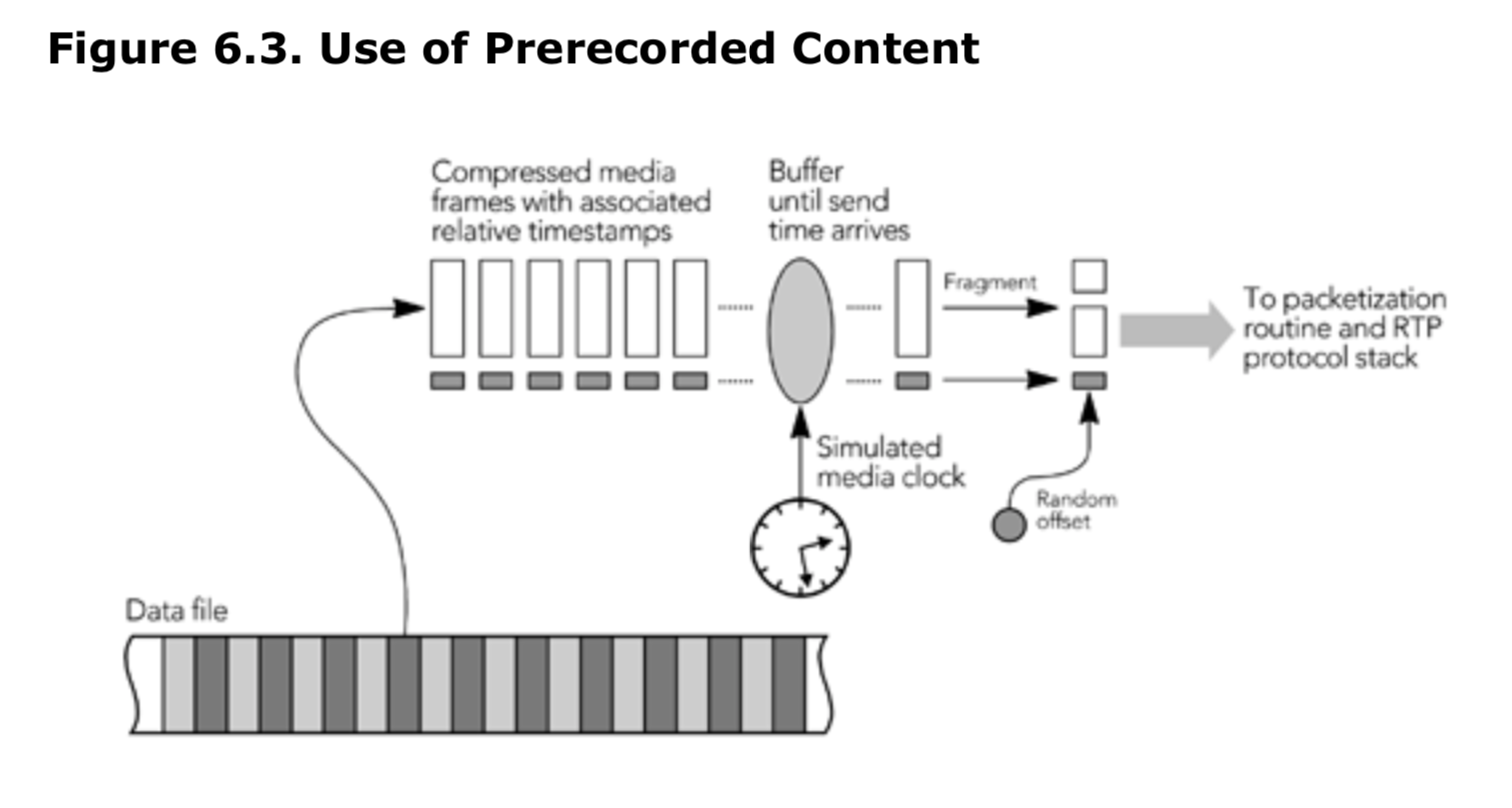
使用预先录制的内容
从预先录制和编码的内容文件流式传输时,媒体帧将以与直播内容几乎相同的方式传递到打包程序。 RTP 规范没有区分直播媒体和预录媒体,发送者无论如何封装帧,都以相同的方式从编码帧解封装为数据包。
特别是,当开始流式传输预先录制的内容时,发送者必须生成新的 SSRC,并为 RTP 时间戳和序列号选择随机初始值。 在流传输过程中,发送者必须准备处理 SSRC 冲突,并且应生成并响应该流的 RTCP 包。 另外,如果发送者实现了控制协议(例如 RTSP),允许接收者在媒体流中暂停或查找(seek),则发送者必须跟踪此类交互,以便可以将正确的编号和时间戳插入 RTP 数据包中(这些问题在第 4 章《RTP 数据传输协议》中讨论过了)。
需要实现 RTCP,并确保序列号和时间戳正确,这意味着发送者不能简单地将完整的 RTP 数据包存储在文件中,也不能直接从文件流式传输。 相反,如图 6.3 所示,必须实时存储和打包媒体数据帧。
封装 RTP 包
生成编码帧后,会将它们传递到 RTP 打包程序。 每个帧都有一个关联的时间戳,可从中导出 RTP 时间戳。 如果有效负载格式支持分段,则将过大的帧分段以适合网络的 MTU(通常仅视频需要)。最后,为每个帧生成一个或多个 RTP 数据包,每个数据包都包括媒体数据和任何所需的有效负载头。 媒体数据包和有效负载头的格式是根据所用编解码器的有效负载格式规范定义的。数据包生成过程的关键部分是为帧分配时间戳,分割过大的帧以及生成有效负载包头。在以下各节中将更详细地讨论这些问题。
除了直接表示媒体帧的 RTP 数据包之外,发送者还可以生成纠错包,并可以在传输之前对帧进行重新排序。 这些过程在第 8 章《错误隐藏》和第 9 章《错误恢复》中进行了描述。 在发送 RTP 数据包之后,与这些数据包相对应的缓冲媒体数据最终将被清空。 发送者不得丢弃纠错或编码过程中可能需要的数据。此要求可能意味着发送者必须在发送完相应的数据包后将数据缓冲一段时间,具体取决于所使用的编解码器和纠错方案。
时间戳与 RTP 的时序模型
RTP 时间戳表示帧数据第一个比特位的采样时刻(sampling instant)。它从一个随机初始值开始,速率递增和媒体类型相关。
在采集实时媒体流期间,采样时刻就是从视频帧采集器或音频采样设备采集媒体的时间。如果要同步音视频,必须确保考虑了不同采集设备中的处理延迟。对于大多数音频有效负载格式,每帧的 RTP 时间戳增量等于从采集设备读取的样本数量。MPEG 音频,包括 MP3,它使用 90kHz 媒体时钟,以与其他 MPEG 内容兼容。对于视频,根据时钟和帧速率,对于采集的每个帧,RTP 时间戳都会以标称的每帧值递增。 大多数视频格式使用 90kHz 时钟,因为这样可以为常见的视频格式和帧速率提供整数时间戳记增量。 例如,如果使用带有 90kHz 时钟的有效负载格式以每秒(大约)29.97 帧的 NTSC 标准速率发送,则 RTP 时间戳将每个数据包增加 TexactlyT 3003。
对于从文件流式传输的预录制内容,时间戳给出了播放序列中帧的时间,加上一个恒定的随机偏移量。 如第 4 章《RTP 数据传输协议》所述,从中导出 RTP 时间戳的时钟必须以连续和单调的方式增加,不需要考虑查找(seek)操作或播放中的暂停。 这意味着时间戳并不总是对应于帧从文件开始的时间偏移; 而是以自播放开始以来的时间轴为测量基准。
时间戳是按帧分配的。 如果将一个帧分成多个 RTP 数据包,那么组成该帧的每个数据包都将具有相同的时间戳。
RTP 规范不保证媒体时钟的分辨率、准确性或稳定性。发送者负责选择合适的时钟,并为所选应用提供足够的准确性和稳定性。接收者知道标称时钟速率,但通常不了解时钟精度。除非应用程序具有相反的特定知识,否则应用程序在发送者和接收者都应对媒体时钟的可变性具有鲁棒性。
RTP 数据包和 RTCP 发送者报告中的时间戳表示发送者媒体的时序:采样过程的时序以及采样过程与参考时钟之间的关系。 接收者期望根据该信息来重建媒体的时序。 请注意,RTP 时序模型没有说明何时播放媒体数据。 数据包中的时间戳给出了相对时序,RTCP 发送者报告提供了流间同步的参考,但 RTP 并未说明接收者可能需要的缓冲量或包的解码时间。
尽管很好地定义了时序模型,但 RTP 规范并未提及用于重建接收者时序的算法。这是有意为之的:播放算法的设计取决于应用程序的需求,按需实现。
分段 Fragmentation)
超出网络最大传输单位(MTU)的帧必须在传输之前分成几个 RTP 数据包,如图 6.4 所示。每个分段都有该帧的时间戳,并可能有一个额外的有效负载包头来描述分段。
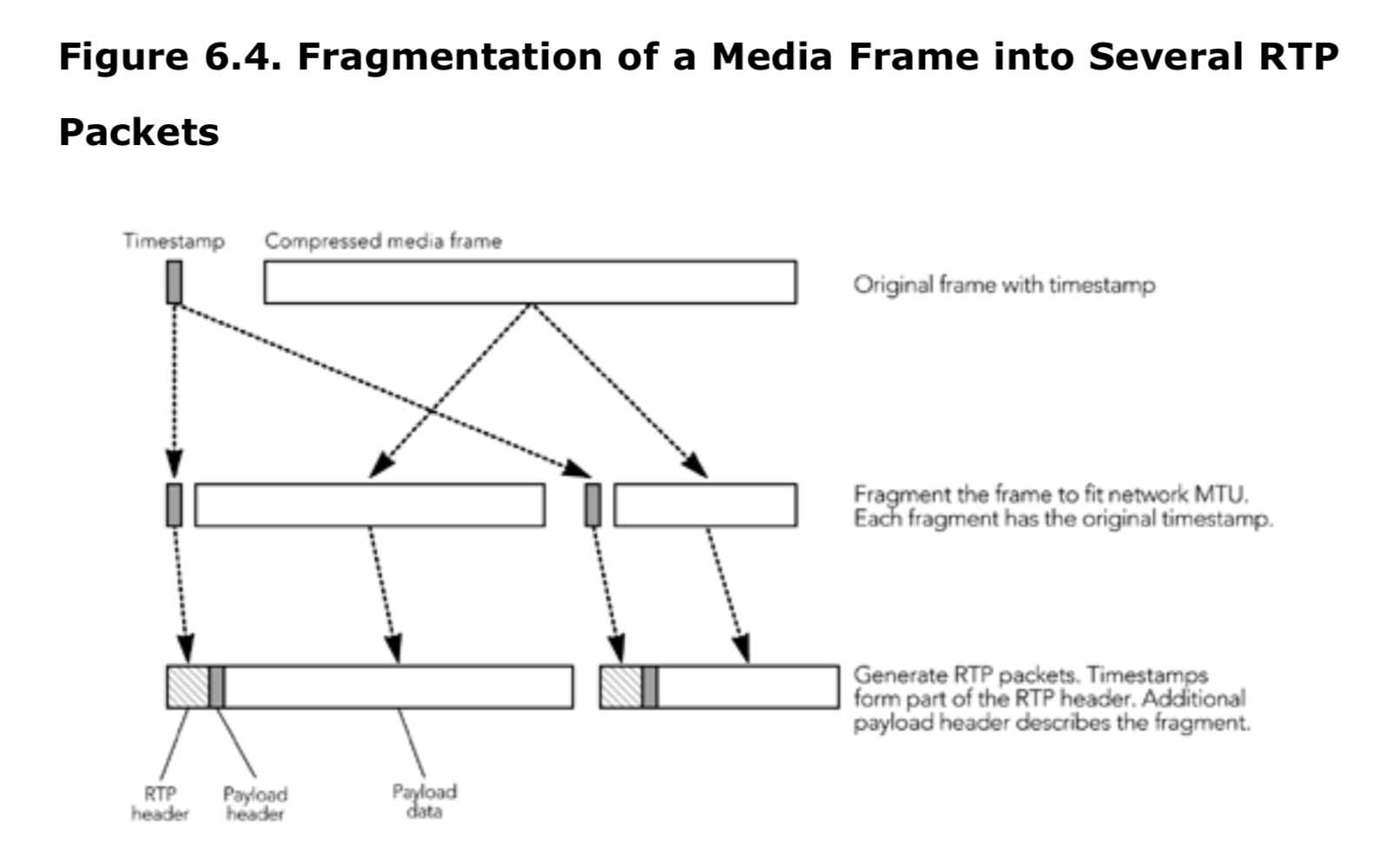
在丢包的情况下,分段的处理对媒体质量至关重要。最理想的情况是独立解码每一个分段。否则单个分段的丢失会将导致整个帧都被丢弃, 这是我们不希望看到的。可能需要在分段的时候制定一些规则,根据这些规则,负载数据可以在适当的位置做分割,并加上负载头,以帮助接收者在某些片段丢失的情况下还可以使用。这些规则需要编码器的支持,以生成既符合有效负载格式的打包规则又适合网络 MTU 的片段。
如果编码器不能生成适当大小的片段,发送者可能必须使用任意的片段。可以通过 RTP 层上的应用程序或使用 IP 分段的网络来实现分段。如果丢失了任意分段的帧的某些片段,则很可能必须丢弃整个帧,从而大大降低质量(Handley 和 Perkins 更详细地描述了这些问题)。
当为每帧封装多个 RTP 包时,发送者必须在以下方式中选择其一:一次性发送数据包(sending the packets in single burst)还是拆分后的多个数据包分散开传输在帧间隔中。一次性发包会减少端到端的延迟,但是可能会超出网络或接受主机的缓冲区大小。出于这个原因,一般都是选择发送者在帧间隔内及时分发包。无论是否存在其他的场景,这对于发送者,特别是高速发送者,这都是非常重要的办法。
负载的格式-特殊的头信息
除了 RTP 报头和媒体数据之外,包通常还包含一个额外的特定于负载的包头。此包头由使用中的 RTP 有效负载格式规范定义,并在 RTP 和编解码器之间,提供了一个适配层。
有效负载包头的典型用法是使编解码器(该编解码器不适合在有损数据包网络上使用)在 IP 上工作,以提供错误恢复能力或支持分段。精心设计的有效负载包头可以大大提高有效负载格式的性能,实现者应注意以正确生成这些包头,并使用提供的数据来修复接收者丢包的影响。
在第四章《RTP 数据传输协议》中,“负载头信息”这一节详细讨论了有效负载头的使用。
接收者的处理
正如第一章《RTP 介绍》中所强调的,接收者负责从网络中读取 RTP 数据包,修复丢失的数据包,恢复时序,解码媒体,并将结果呈现给用户。此外,接收者需要发送接收质量报告,以便发送者能够根据网络特性调整传输策略。接收者通常还将维护会话中的参与者数据库,以便能够向用户提供其他参与者的信息。第一章的图 1.3 显示了接收者的框图。
接收过程的第一步是读取来自网络的数据包,验证数据包的正确性,并将它们插入到发送者对应的缓存队列中。这流程并不复杂,媒体格式无关。下一节 包接收将描述这个过程。
接收方的后续操作针对每个发送方,并且与传输的媒体类型有关。数据包从缓冲队列中取出,如果实现了信道编码,则会将数据包放入信道编码队列以纠正丢包。当接收到完整的帧后,数据包会被插入到与数据源相关的播放缓冲区中,以平滑处由于网络引起的数据包间到达时序的变化。计算出适当的缓冲延迟是一个关键的技术问题,该部分在本章后面的“播放缓冲区”一节中进行了详细解释。本章的“调整播放点”一节描述了如何在不中断媒体播放的情况下调整时序。
在达到播放时间之前,数据包被组合成完整的帧。使用在第8章中描述的算法修复损坏或丢失的帧,然后进行解码。最终,媒体数据将被呈现给用户。根据媒体格式和输出设备的不同,单独播放每个流,例如在各自的窗口中显示多个视频流。或者说,可能需要将所有来源的媒体混合成一个单一的流进行播放,例如将多个音频来源混合后通过一套扬声器播放。本章的最后一节“解码、混音和播放”描述了这些操作。
RTP 接收者的实现相比于发送者的实现更为复杂。这种复杂性的增加,很大程度上是因为 IP 网络的固有变化造成的(丢包补偿和时序恢复)。
数据包接收
RTP 会话由数据流和控制流组成,在不同的端口上运行(通常数据包在偶数端口上运行,控制数据包在下一个奇数端口上运行)。这意味着接收应用程序为每个会话打开两个套接字:一个用于数据,一个用于控制。因为 RTP 运行在 UDP/IP 之上,所以使用的套接字是标准的 SOCK_DGRAM 套接字,就像类似于 unix 上的 Berkeley sockets API 或者 Microsoft 平台上的 Winsock 所提供的那样。
一旦创建了套接字,应用程序就应该准备接收来自网络的数据包,并将它们存储起来以便进一步处理。许多应用程序将其实现成一个循环,反复调用 select()来接收包 -- 例如:
fd_data = create_socket(...);
fd_ctrl = create_socket(...);
while (not_done)
{
if (FD_ISSET(fd_data, &rfd))
{
...validate data packet
...process data packet
}
if (FD_ISSET(fd_ctrl, &rfd))
{
...validate control packet
...process control packet
}
}
如第四章《RTP 数据传输协议》和第五章《RTP 控制协议》所述,对数据和控制包进行校验,之后按照后面两节所述进行处理。select()操作的超时,通常是根据媒体的帧间隔配置。例如,接收 20 毫秒音频数据包需要设置 20 毫秒的超时时间,从而允许其他处理(例如解码接收到的数据包), 并实现播放同步进行,所以应用程序每 20 毫秒循环一次。
接收者其他模块的实现是根据事件驱动或者轮训,但基本概念保持不变:数据包在从网络接收时持续进行验证和处理,其他模块的处理需要与之并行(可以是显式的时间片轮询,,或作为独立的线程运行),根据媒体处理的需求来编排媒体时序。对于RTP接收方来说,实时操作非常关键;数据包必须按照到达的速度进行处理,否则接收质量将受到影响。
数据包的接收
媒体播放过程的第一阶段是从网络获取 RTP 数据包,加入缓冲,进行处理。由于网络运用,到达时序很难保证,如图 6.5 所示会出现多个数据包同时到达或没有数据包到达的时间片,甚至可能出现数据包乱序的情况。接收方并不知道数据包何时到达,因此需要准备好在任何时间以任何顺序接收数据包。
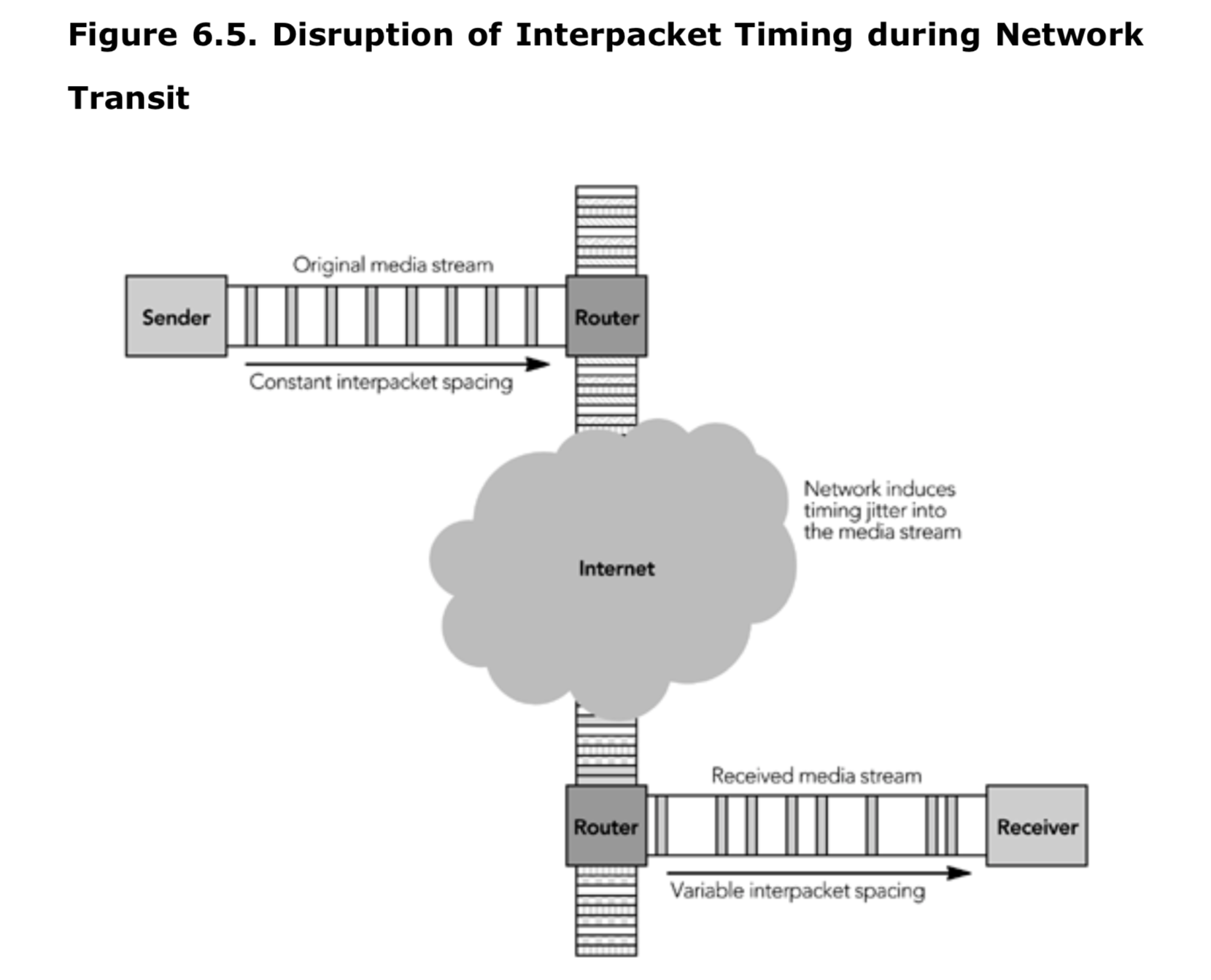
接收到数据包后,进行正确性校验,记录到达时间,并按照 RTP 时间戳排序,然后将数据包添加到每个发送者的输入队列中,以供以后处理。这些步骤可以将数据包的到达速率与处理和播放分离,应对到达速率的变化。图 6.6 显示了数据包接收和播放程序之间的分离,二者仅由输入队列串联。
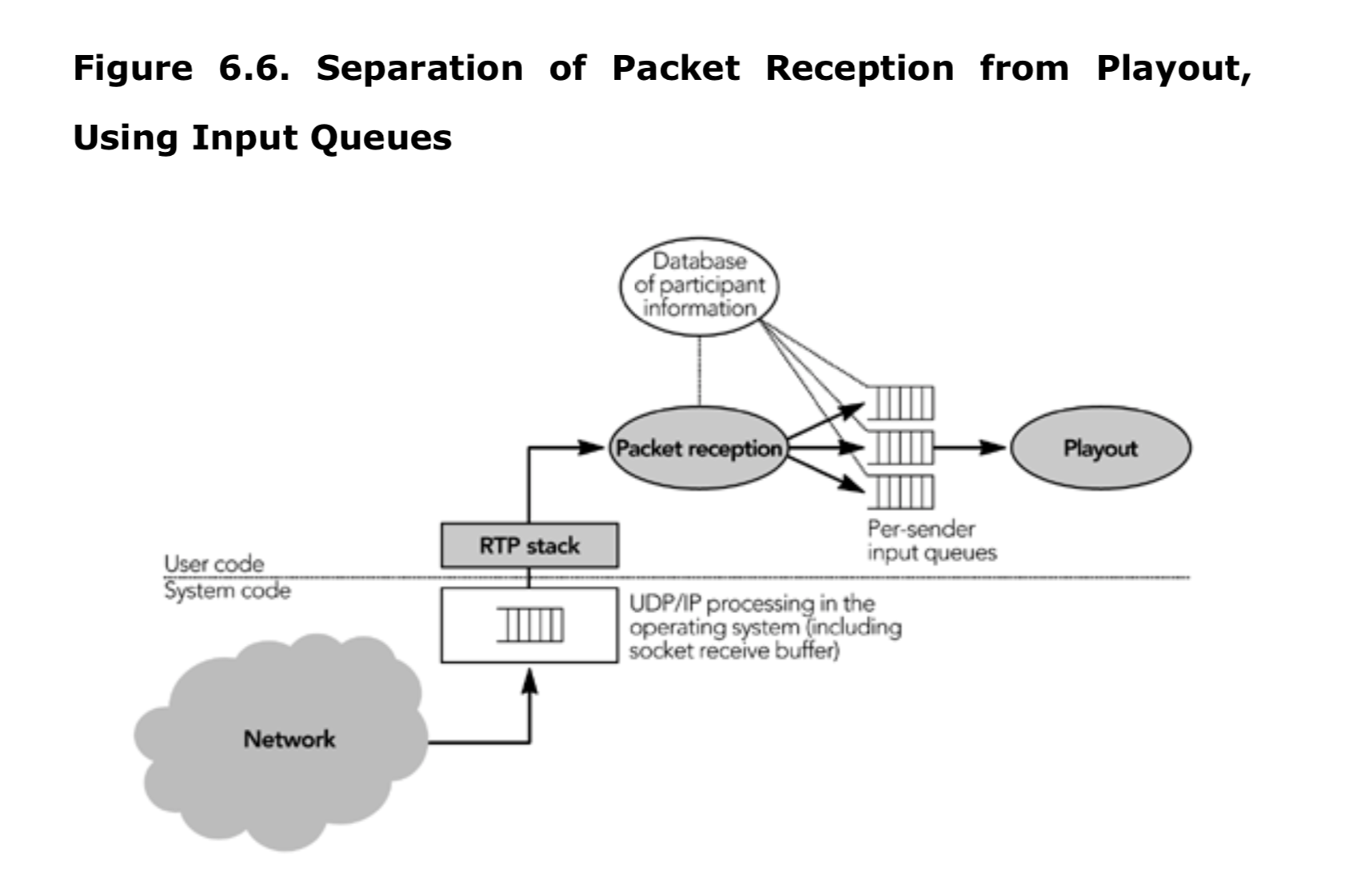
准确到记录RTP数据包的到达时间对于计算抖动非常重要。如果达时间测量不准确 ,会让网络抖动看起来更严重,并导致播放延迟增加。到达时间应该基于本地参考时钟T进行测量,并转换为媒体时钟速率R。由于接收方通常没有这样的时钟,所以通常我们通过采样参考时钟(通常是系统墙钟时间)并将其转换为本地时间轴来计算到达时间:
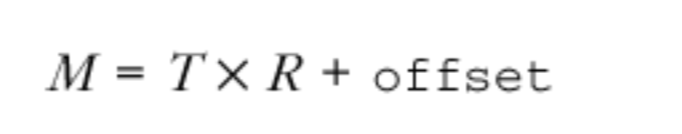
在校正媒体时钟和参考时钟之间的偏差的过程中,使用 offset 从参考时钟映射到媒体的时间线。
如前所述,数据包的处理可以在单线程的应用程序中与数据包接收一同处理,按时间片隔离,或者可以在单独线程中运行。在时间片设计中,单个线程同时处理数据包接收和播放操作。在每个循环中,所有未完成的数据包都会从套接字中读取并插入到输入队列中。根据需要,数据包会从队列中移除并进行播放。如果数据包以突发形式到达,一些数据可能会保留在输入队列中,需要多次循环才能处理完全,具体取决于所需的播放速率和处理效率。
通常,多线程接收者有一个线程在套接字上等待数据到达,将到达的数据包放入输入队列进行排序。其他线程从输入队列中提取数据,并进行解码和播放媒体。线程的异步操作,以及输入队列中的缓冲,有效地将播放过程与输入速率的短期波动解耦,使得播放过程不受输入速率短期变化的影响。
无论选择那种设计,应用程序通常无法持续接收和处理数据包。输入队列可以处理放过程中的波动,但是对于数据包接收过程的延迟呢?幸运的是,大多数通用操作系统以中断驱动的方式处理UDP/IP数据包的接收,并且即使应用程序处于busy状态,也可以在套接字层面缓冲数据包。这种能力在数据包到达应用程序之前提供了有限的缓冲。默认套接字缓冲区能适配大多数场景,但是接收高速流或长时间无法处理接收可能需要增加套接字缓冲区的大小,增加默认值(在许多系统上,setsockopt(fd, SOL_SOCKET, SO_RCVBUF, ...)函数)。较大的套接字缓冲区可以容纳数据包接收处理中的变化延迟,但是数据包在套接字缓冲区中停留的时间在应用程序中表现为网络抖动。应用程序可能会增加其播放延迟以弥补这种感知上的变化。
接收控制包
在数据包到来的同时,应用程序必须准备接收、校验、处理和发送 RTCP 控制包。RTCP 包中的信息用于维护会话内发送者和接收者的数据库,如第五章《RTP 控制协议》中所讨论的,主要用于参与者校验和识别、适应网络条件和音视频同步。参与者数据库也是挂起参与者特定的输入队列、播放缓冲区和接收者需要的其他状态的好地方。
单线程应用程序通常在 select()循环中同时包含数据和控制套接字,从而将控制数据包的接收和其他处理交织在一起。多线程的应用程序可以将一个线程用于 RTCP 接收和处理。由于与数据包相比,RTCP 包很少出现,因此它们的处理开销通常比较低,而且对时间要求不是特别严格。但是,记录发送报告(SR)数据包的确切到达时间非常重要,因为这个值在接收者报告(RR)数据包中返回,用于计算往返时间。
当 RTCP 发送者/接收者报告包到达时(描述在特定接收者处看到的接收质量),将存储它们包含的信息。解析 SR/RR 包中的报告块很简单,只要你记住数据是按照网络字节顺序进行排列的,在使用之前必须将其转换为主机的顺序。RTCP 包头中的 count 字段表示有多少报告块;请记住,0 是一个有效值,表示 RTCP 包的发送者没有接收到任何 RTP 数据包。
RTCP的发送者/接收者报告主要用于应用程序监视其发送的流的接收情况。如果报告显示接收情况不佳,应用程序可以采取一些措施,如添加错误保护或降低发送速率来进行补偿。在多发送者会话中,还可以监视其他发送者的质量。例如,网络操作中心可以通过监视SR/RR数据包来检查网络是否正常运行。应用程序通常会在接收时存储接收质量数据,并定期使用这些存储的数据来适应其传输。
发送者报告还包含 RTP 媒体时钟和参考时钟之间的映射(用于音视频同步),以及发送数据量的计数。同样,这些信息是按照网络字节顺序排列的,在使用前需要进行转换。如果用于音视频同步的目的,那么需要存储下来。
当 RTCP 源描述包到达时,它们包含的信息被存储并可能显示给用户。RTP 规范包含用于解析 SDES 数据包的示例代码(参见规范的附录 A.5)。SDES CNAME(规范名)提供音视频流之间的关系,表明那些流需要同步。RTCP 源描述包还用于对来自单个源的多个流进行分组(例如,如果一个参与者有多个摄像头向一个 RTP 会话发送视频),这可能会影响向用户显示媒体的方式。
在验证RTCP数据包后,其中包含的信息将被添加到参与者数据库中。由于对RTCP数据包进行了强大的有效性检查,因此数据库中存在的参与者可以可靠地表明其有效性。这对于验证RTP数据包非常有用:如果之前在RTCP数据包中看到过RTP数据包中的SSRC(同步源标识符),那么该SSRC很可能是一个有效的数据源。
当接收到RTCP Bye包时,参与者数据库中的条目将被标记为稍后删除。根据《RTP控制协议》第五章的描述,当收到Bye包时,RTP控制协议不会立即删除条目,而是保留一段时间,以允许延迟的数据包到达。在我的实现中,我使用了一个固定的两秒超时,具体的值并不重要,只要它大于典型的网络抖动即可,接收者还会定期执行清理工作,以便将不活跃的参与者标记为超时。这个操作不需要针对每个,每个RTCP报告间隔执行一次就足够了。
播放缓冲区
数据包从其输入队列中提取出来,插入播放缓冲区中 ,缓冲区里面的 RTP 包根据时间戳排序。帧会被保存在播放缓冲区一段时间,来平滑网络引起的时间变化。将数据保存在播出缓冲区中还可以接收分段帧的分段并进行分组,并且可以允许任何纠错数据到达。然后解码帧,隐藏任何剩余的错误,并且为用户做展现。图 6.7 说明了该过程。
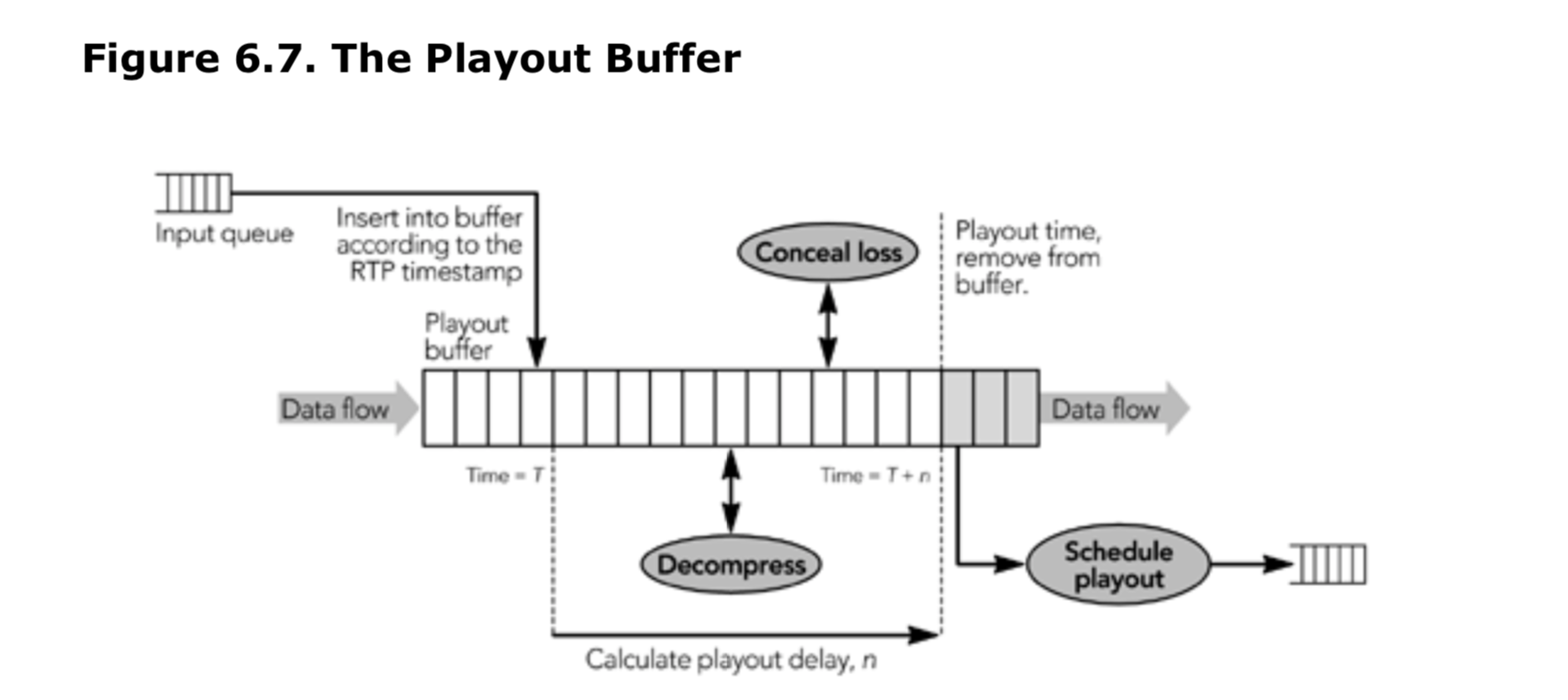
单个的缓冲区可以用来补偿网络到达时间的变化,并作为解码缓冲区的媒体解码器。也可以分离这些功能:使用单独的缓冲区进行抖动消除和解码。在 RTP 中从来没有严格的分层要求:高效的实现常常应该跨越层的边界混合相关功能,这就是“集成层处理”(integrated layer processing)的概念。
基础操作
播放缓冲区包含一个按时间序列排列的链表。每个节点代表一帧及时序信息。每个节点的数据结构包含指向相邻节点的指针、到达时间、RTP 时间戳和播放时间,以及指向帧的编码片段(RTP 包接收的数据)和未编码的媒体数据的指针。图 6.8 说明了所涉及的数据结构。
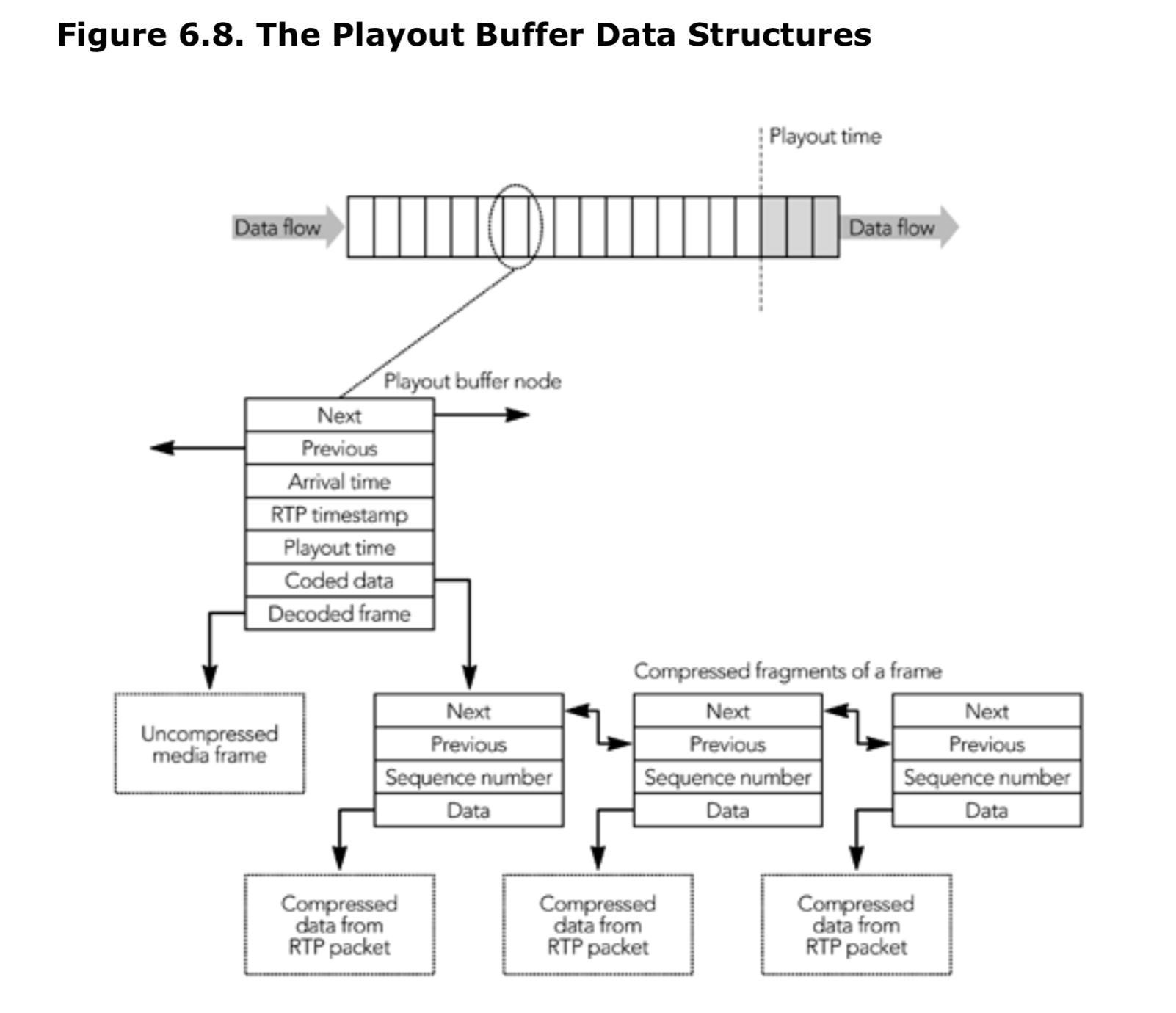
当一帧中的第一个RTP包到达后,把这帧的数据包从输入队列中移除,并按照RTP时间戳的顺序,保存在播放缓冲区中。这需要创建一个新的播放缓冲区节点,并将其插入到播放缓冲区的链表中。最近到达的数据包中的压缩数据与播放缓冲区节点进行链接,以便稍后进行解码。最后,根据本章后面解释的方法计算出该帧的播放时间。
新创建的节点驻留在播放缓冲区中,直到达到播放时间为止。在此期间,包含帧的其他片段的包,可能到达并从此节点链接。一旦确定已接收到帧的全部片段,就会调用解码器,并从播放缓冲区节点链接封装未编码的帧。如何确定是否收到一个完整的帧取决于编码器:
- 音频编码器通常不分段帧,每帧只有一个包(mp3 是常见的例外)
- 视频编解码器通常为每个视频帧封装多个包,并设置 RTP 标记位来指示包含最后一个分段的 RTP 包。
接收到设置了标记位的视频数据包并不意味着已经接收到完整的帧,因为数据包可能会在传输过程中丢失或重新排序。相反,它提供了帧的最高RTP序列号。要确定帧是否完整,需要接收到所有具有相同时间戳但序列号较低的RTP数据包。如果接收到带有前一帧标记位的数据包,则可以轻松确定该帧是否完整。如果该数据包丢失(例如没有收到标记位但时间戳发生了改变),并且根据序列号只丢失了一个数据包,则丢失的包后面的第一个数据包将是帧的第一个数据包。如果丢失了多个数据包,则通常无法确定这些数据包是属于新帧还是前一帧(在某些情况下,媒体格式可以确定帧的边界,但这取决于编解码器和有效负载格式)。
何时调用解码器的决定取决于接收方,而不是协议规定。数据帧可以在完整到达后立即解码,也可以保持压缩状态直到最后一刻再解码。在需要在处理效率以及缓存的空间之间权衡。例如,如果接收方知道关键帧即将到来,接下来会有大量计算,可能会提前解码数据。
最终,如果帧的到了播放时间,帧将排队等待播放,如本章后面的《解码,混流和播放》部分所述。 即使在等待播放的帧尚未解码时,即使某些分片丢失,接收者也必须尽最大努力解码该帧,因为这是解码该帧的最后机会。同时,这也是调用错误隐藏(请参阅第8章)来纠正的数据包丢失的时间。
一旦帧播放完,相应的播放缓冲区节点,及其关联的数据应该被销毁或回收。但是,如果使用了错误隐藏,则最好将此过程延迟到周围的帧也完成之后,因为相关的媒体数据可能对隐藏操作有用。
应该丢弃那些延迟到达的数据包,延迟到达的数据包指错过播放时间的数据包。数据包是否即使到达,可以通过比较当前数据包的时间戳和播放缓冲中,最旧的数据包的时间戳来完成(注意,比较应该使用模运算,兼容时间戳的翻转场景)。显然,应该选择适当的播放延迟,以使延迟数据包的出现的概率,应用程序应该监控延迟数据包的数量,并准备根据情况调整播放延迟。延迟数据包表明播放延迟需要调整,数据包到达延迟通常是由于网络延迟或发送者和接收主机之间时钟偏差的变化所致。
播放缓冲区需要在保真度和延迟之间做权衡:应用程序必须确定可以接受的最大播放延迟。为交互式系统 -- 例如,视频会议或电话 -- 必须尽量减少播放延迟,因为它无法承受缓冲带来的延迟。对人类感知能力的研究表明,互动的最大可容忍的往返时间限制在 300ms 左右。如果系统是对称的,则该限制意味着只有 150 毫秒的端到端延迟,包括网络传输时间和缓冲延迟。然而,非交互式的系统,如流视频、电视或广播,可能允许播放的缓冲区增长到几秒,从而使非交互式系统能更好的处理包到达的时间。
计算播放时序
设计 RTP 播放缓冲区的最大难点是确定播放延迟,在播放之前,数据包应该在缓冲区中停留多长时间?答案取决于多种因素:
- 接收帧的第一个和最后一个数据包之间的延迟
- 接收任何纠错数据包之前的延迟(见第九章《错误恢复》)
- 由于网络抖动和路由更改导致的数据包间的时序变化
- 发送者和接收者之间的相对时钟偏移(skew)
- 应用程序的端到端之间延迟预测,以及接收质量和延迟的相对重要性。
发送端可以控制帧内数据包之间的延迟,以及数据包和纠错包之间的延迟。这些因素对播放延迟计算的影响在本章后面的“发送方行为的HTU补偿”一节中有详细讨论。
应用程序无法控制的因素包括网络的行为以及发送方和接收方时钟的准确性和稳定性。以图6.9为例,该图显示了一组RTP音频数据包的传输时间和接收时间之间的关系。如果发送方和接收方的时钟以相同的速率运行,就如期望的那样,这个图的斜率应该恰好为45度。但实际上,发送方和接收方的时钟通常无法同步,运行速率也会略有差异。在图6.9中,发送方的时钟比接收方的时钟运行得更快,因此图的斜率小于45度(这个图是为了更容易看到效果而极端化的例子;通常情况下,斜率会更接近45度)。本章后面的“时钟偏差的补偿”一节将详细解释如何纠正不同步的时钟。
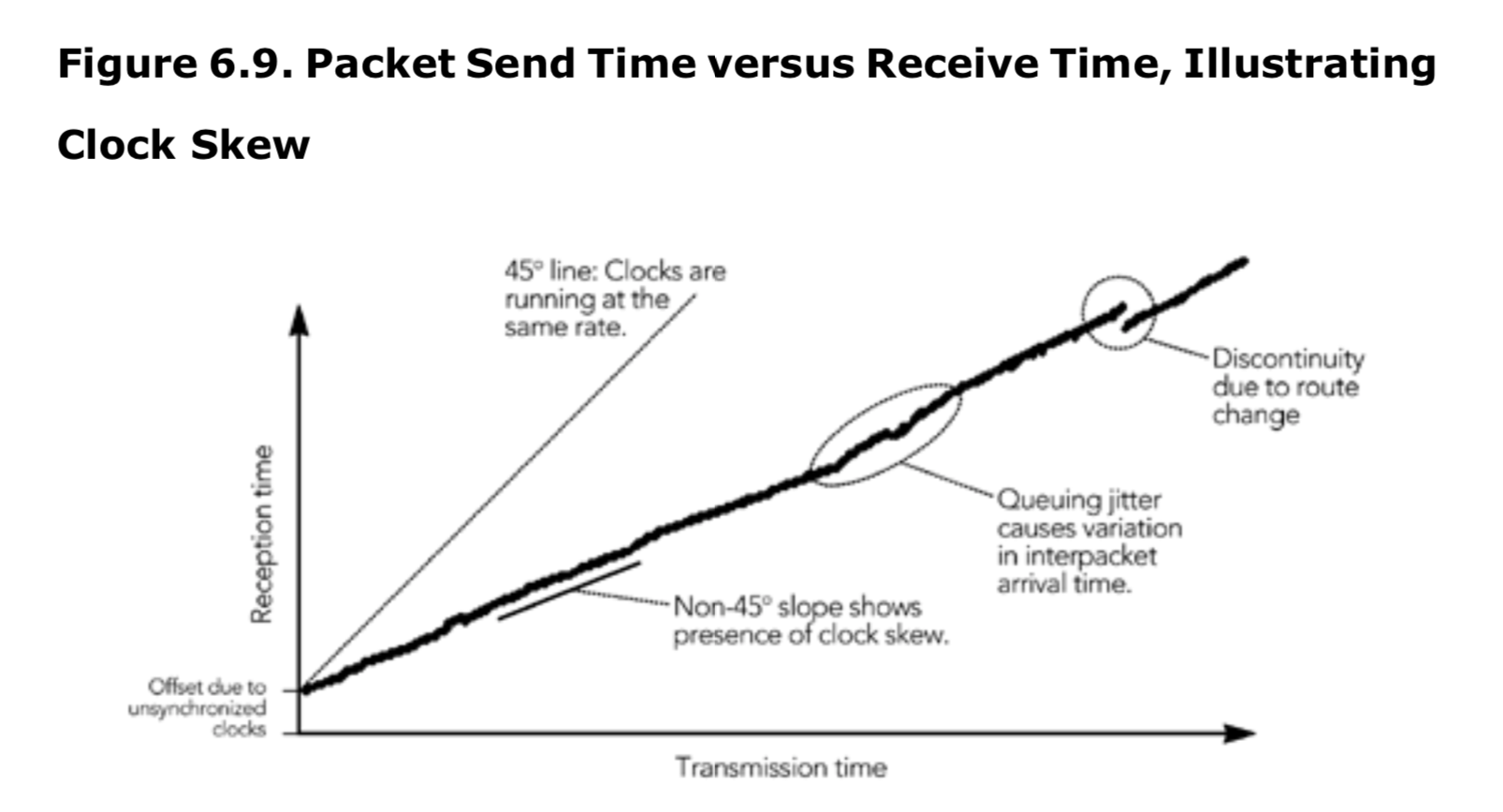
如果数据包具有恒定的网络传输时间,图6.9中将呈现出完全直线。然而,通常由于排队延迟的变化,网络会引入一些抖动,导致数据包之间的间隔波动,这在图中可以看到,呈现出与直线图的偏离。图中还显示了一个不连续点,这是由于网络传输时间发生了突变,很可能是由于网络中的路由变化引起的。HTU第2章《数据包网络上的语音和视频通信》详细讨论了这些影响,本章后面的“抖动的HTU补偿”一节解释了如何纠正这些问题。如何纠正更极端的变化在“路由变化的HTU补偿”和“数据包重排序的HTU补偿”这两节中进行了讨论。
最后需要考虑的是端到端延迟的容忍阈值。这主要取决于个人因素:对于用户来说,他们能够接受的最大端到端延迟是多少?在网络传输时间被排除后,用于平滑播放缓冲的剩余时间是多少?显然,可用于缓冲的时间会影响播放缓冲的设计。本章后面的"抖动的补偿"一节进一步讨论了这个问题。
在决定每一帧的播放时间的时候,接收者应该上面的因素。所以对播放的计算步骤如下:
- 发送者的时间轴映射到本地播放时间轴,以补偿发送者和接收者时钟之间的相对偏移,以导出播放时间计算的基准时间(请参考本章后面的映射到本地时间轴)。
- 如果有必要,接受者可以通过添加一个偏移补偿偏移来补偿相对发送者的时钟,该偏移会定期校准基准时间(参见时钟偏移补偿)。
- 本地时间轴上的播放延迟是根据播放延迟中与发送者相关的部分(参考“发送者行为的补偿”)和与抖动相关的部分(请参见“抖动补偿”)计算的。
- 如果路由发生了变化(参见路由变化的补偿),如果包被重新排序(参见排序的补偿),如果选择的播放延迟导致帧重叠,或者相应媒体中其他的变化(参见调整播放点),则会调整播放延迟。
- 最后,将播放延迟添加到基准时间中,以获得帧的实际播放时间。
图 6.10 说明了计算的过程,并记录了此过程。下面给出了每个阶段的详细信息。
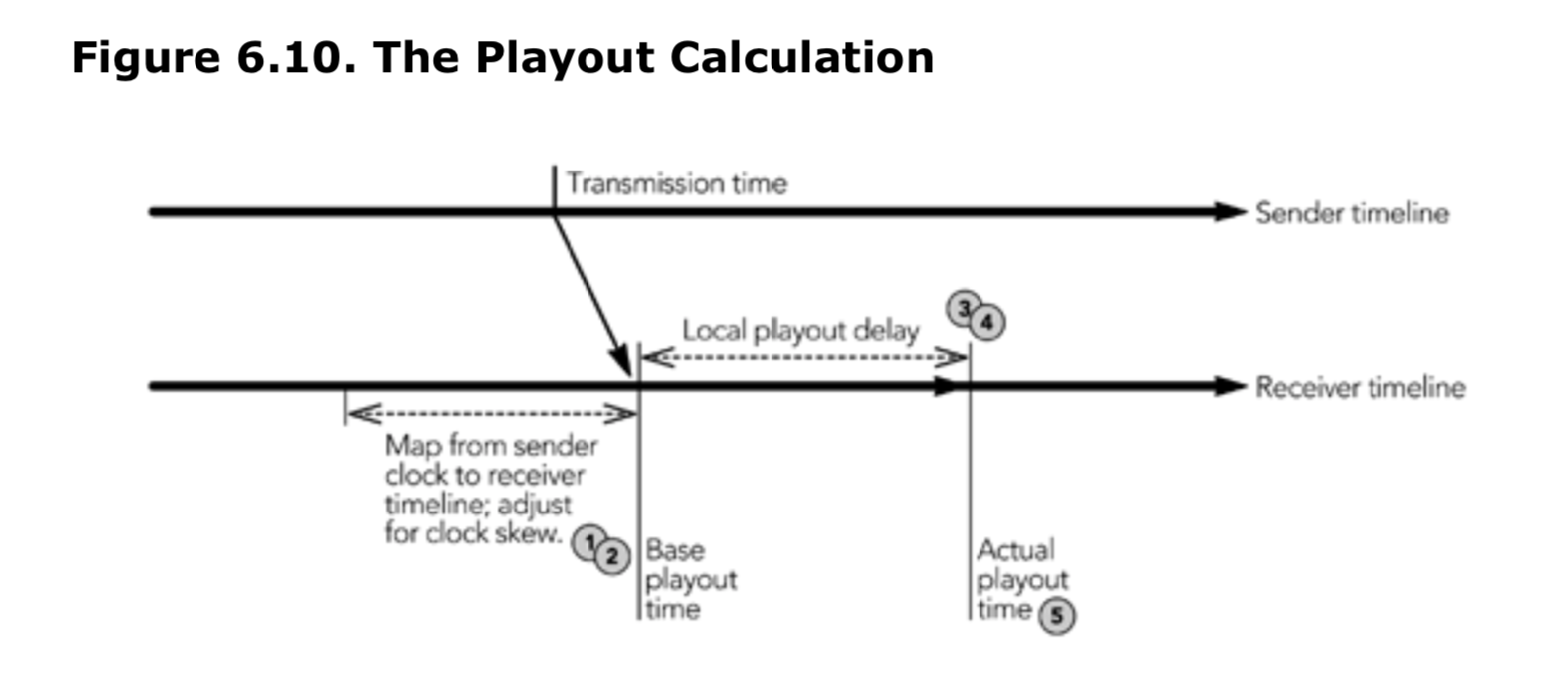
本地时间轴映射
播放时间计算的第一阶段是通过将发送者和接收者时钟之间的相对偏移添加到 RTP 时间戳,将发送者的时间轴(以 RTP 时间戳表示)映射到接收者的时间轴。
为了计算相对偏移量,接收者需要以相同的单位计算第 n 个包的 RTP 时间戳 与该包的到达时间
与该包的到达时间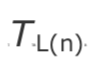 之间的差值 d(n):
之间的差值 d(n):
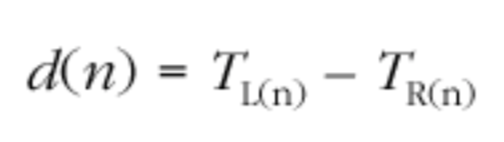
这个差值包含一个常数因子,设置这个常数因子是因为发送者和接受者的时钟是在不同的时间用不同的随机值初始化的,也是因为在发送者处的数据准备时间而引起的延迟可变,也是因为网络传输时间最短而导致的常数因子,更是因为网络时序抖动引起的可变延迟以及由于时钟偏斜引起的速率差。
这个差值 d(n)包括一个常数因数,因为发送者和接收者时钟在不同的时间使用不同的随机值进行初始化;由于在发送者处的数据准备时间而导致的可变延迟;由于最小网络传输时间而导致的常数;由于网络时序抖动以及由于时钟偏移引起的速率差异。差值是一个 32bit 无符号整数,就像计算它的时间戳一样。 并且由于发送者和接收者时钟未同步,因此它可以具有任何 32bit 值。
在每个数据包到达时计算差值,并且接收者跟踪其最小观测值以获得相对偏移:
由于时钟偏移导致 和
和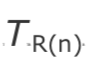 之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
根据接收者的时间轴,偏移量用于计算基本的播放点:
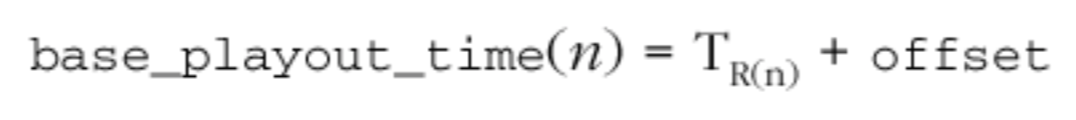
这是对播出时间的初始预估,并应用了其他因素来补偿时钟偏斜(skew)以及抖动等。
时钟偏移(skew)补偿
RTP 有效负载格式定义了媒体流的标准时钟速率,但是对时钟的稳定性和准确性没有任何要求。发送者和接收者的运行速率通常稍微不同,迫使接收者对需要变化进行补偿。数据包的传输时间与接收时间的关系图,如图 6.9 所示。如果曲线的斜率正好是 45 度,那么时钟的频率是一样的,偏移是由发送者和接收者之间的时钟倾斜造成的。
接收方需要检测时钟偏差是否存在,并估计其大小,然后通过调整播放点进行补偿。有两种可能的补偿策略:一种是调整接收方时钟以与发送方时钟匹配,另一种是定期调整播放缓冲区的重新对齐。
后一种方法不调整受时钟偏差,而是通过插入或删除数据来周期性地重新对齐播放缓冲区。如果发送方的速度更快,接收方最终需要丢弃保持对齐时钟,否则播放缓冲区将溢出。如果发送方的速度较慢,接收方将用完可播放的媒体内容,必须合成一些数据来填补剩余的空白。时钟偏差的大小决定了播放点调整的频率,从而决定了体验下降程度。
如果接收方的时钟频率可以进行精确调节,可以调整速率以完全匹配发送方的速率,从而避免了对播放缓冲区进行重新对齐。这种方法可以提供更高的质量,因为数据不会因为时钟偏差而被丢弃,但可能需要硬件支持,这种硬件并不常见(音频系统可以用软件的方法重新采样来匹配所需的速率)。
估计初始时钟偏差看起来似乎很简单:观察发送方时钟的速率,即RTP时间戳,然后与本地时钟进行比较。如果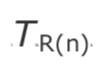 是接收到的第 n 个数据包的 RTP 时间戳,
是接收到的第 n 个数据包的 RTP 时间戳,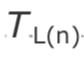 是当时的本地时钟的值,那么时钟偏移的预估如下:
是当时的本地时钟的值,那么时钟偏移的预估如下:
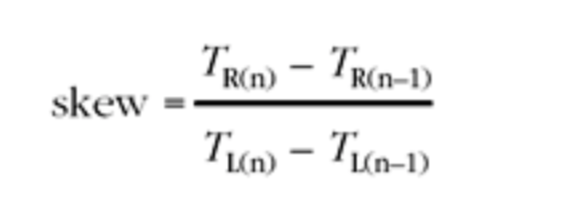
偏移小于 1 表示发送者比接收者慢,而偏移大于 1 表示发送者时钟比接收者快。然而不幸的是,因为网络时序抖动的存在, 这种估算是存在不足的;网络时序抖动回影响到达时间。为了估算更准确时钟偏差,接收方必须观察数据包到达时间长期变化,剔除时序抖动的影响。
准确性和对抖动的敏感性是时钟偏移管理中的重要考虑因素,有多种算法可用于处理这些问题。在下面的讨论中,我将介绍一种简单的方法来估计和补偿时钟偏移,这种方法已被证明适用于VOIP,并提供了适用于对准确性要求更高的应用的算法的指南。
对时钟偏移的管理方法是,持续监控平均网络传输延迟,并将其与主动延迟预估进行比较。有效延迟预估和测得的平均延迟之间的差距越大,越表示了时钟倾斜存在,这最终将导致接收者调整播放。当每个包到达时,接受方根据包的接收时间以及其 RTP 时间戳计算 n 个数据包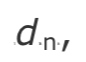 的瞬时单向延迟:
的瞬时单向延迟:
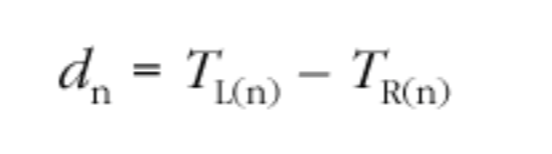
在接收到第一个数据包时,接收者设置延迟为 E = d0,预估平均延迟为 D0 = d0。对于每个后续的数据包,平均延迟预估的值 Dn 将通过指数加权移动平均值(exponentially weighted moving average)进行更新:
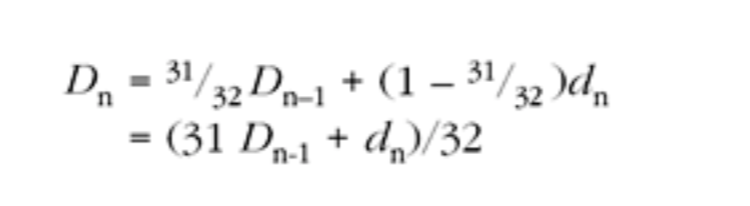
31/32 这个因子控制了平均过程,数值越接近单位 1,平均值对传输时间的短期波动越不敏感。需要注意的是,这个计算类似于估计抖动的计算;但是它保留了变化的符号,并且使用了一个经过选择的时间常数来捕捉长期变化并减小对短期抖动的反应。
将平均单向延迟 Dn 与主动延迟预估 E 进行比较,用来预估自上次预估以来的差异:
如果发送者时钟和接收者时钟保持同步,那么它们之间的差异(divergence)将接近于零,只会因为网络抖动而产生微小的变化。如果时钟存在偏移,那么差异将会增加或减少,直到超过预定的阈值,从而促使接收者采取补偿措施。该阈值的选择取决于抖动的程度,以及编码器。阈值必须足够大,以避免由于抖动引起的错误调整,并且选择调整的时机需要慎重选择,避免播放不连续。通常情况下,合适的时间点是在帧间隔,这意味着可以插入或删除整个帧。
补偿包括增加或减少播放缓冲区,如本章后面的“自适应播放点”一节所述。播放点可以根据 RTP 时间戳单元的差异做变化(对于音频,差异通常给出要添加或删除的样本数量)。在补偿偏移之后,接收者将活动预估值 E,重置为当前延迟预估的值 Dn,在此过程中差异(divergence)重置为 0(此时还将重置 base_play-out_time(n) 的预估值).
在类 C 的伪代码中,当接收到每个包时,执行的算法是这样的:
adjustment_due_to_skew(rtp_packet p, uint32_t curr_time)
{
static int first_time = 1;
static uint32_t delay_estimate;
static uint32_t active_delay;
uint32_t adjustment = 0; uint32_t d_n = p->ts – curr_time;
if (first_time)
{
first_time = 0;
delay_estimate = d_n;
active_delay = d_n;
}
else
{
delay_estimate = (31 * delay_estimate + d_n)/32;
}
if (active_delay – delay_estimate > SKEW_THRESHOLD)
{
// Sender is slow compared to receiver adjustment =SKEW_THRESHOLD; active_delay = delay_estimate;
}
if (active_delay – delay_estimate < -SKEW_THRESHOLD)
{
// Sender is fast compared to receiver adjustment =-SKEW_THRESHOLD; active_delay = delay_estimate;
}
// Adjustment will be 0, SKEW_THRESHOLD, or –SKEW_THRESHOLD. It is // appropriate that SKEW_THRESHOLD equals the framing interval. return adjustment;
}
该算法的假设是抖动分布是对称的,并且任何系统性偏差都是由于时钟偏差引起的。如果偏差值的分布非对称,原因并非时钟偏差,那么该算法会得出错误的偏差。此外,网络传输时间的显著短期波动也可能导致算法失灵,接收方会将网络抖动误认为时钟偏差,调整播放点。然而,这些问题都不能带来实际的问题:偏差补偿算法最终会自我纠正,而任何调整步骤都可能需要来适应这些波动。
另一个偏移补偿的假设是对播放点进行逐步调整,例如逐次添加或删除一个完整的帧,同时隐藏不连续性,就好像丢失了一个包一样。这对许多编解码器(尤其是基于帧的语音编解码器)是适当的行为,因为它们经过优化以隐藏丢失的帧。偏移补偿可以利用这种能力,只需小心地添加或删除不重要的、通常是低能量的帧。然而,在某些情况下,更平滑地自适应是可取的,可能一次插入一个样本。
如果需要更平滑的自适应,Moon等人提出的算法可能更合适,尽管它更加复杂,对状态维护的要求也更高。他们的方法基于观测到的单向延迟与时间之间的关系图,使用线性规划来拟合一条最接近所有数据点的线。一种等效的方法是在图6.9所示的数据点上获得最佳拟合直线,并使用它来估计时钟的倾斜。如果偏移是恒定的,那么这个算法将更准确,但显然会有更高的成本,因为它需要接收者记录点的历史数据,并执行昂贵的线性拟合算法。然而,如果延迟测量采样间隔足够长,该算法可以获得高精度的偏移估计。
对于长期运行的应用程序来说,应考虑时钟偏移的不稳定性,它会受外界影响而随时间变化。例如,温度变化会影响振荡器的频率,从而导致时钟频率和发送方与接收方之间偏移的变化。非稳定的时钟偏差可能会影响依赖于长期观测的数据的一些算法(如Moon等人提出的算法)的效果。其他一些算法,例如前文提到的Hodson等人的算法,由于它们在较短时间内工作并定期重新计算偏差,因此对时钟变化具有较强的鲁棒性。
在选择时钟偏差估算算法时,关键是考虑播出时间点可能的变化规律,并选择一个具有适当精度的估算器。例如,基于帧的音频编解码应用可以通过添加或删除单个帧实现自适应,因此直接基于最近样本测量得到的偏差估算可能会过大。本章后续部分"适应播放点"将更深入地探讨此问题。
虽然它们超出了本书的范围,但是 NTP 的算法可能也会引起读者的兴趣。对于那些对时钟同步和偏移补偿感兴趣的人,推荐阅读 PFC 1305(PDF 版本,可以从 RFC 编辑器的网站http://www.rfc-editor.org获得,比纯文本的版本可读性要强很多)。
发送者补偿
发送者数据包生成方式,可能影响接收者的计算播放时间,从而导致播放缓冲延迟增加。
如果发送者将组成一帧视频发送时间扩展到整个帧间隔,则帧的第一个和最后一个数据包之间将存在延迟,接收者必须缓冲数据包,直到接收到整个帧为止 。 图 6.11 显示了附加的播放延迟 Td 的插入,以确保接收者在所有片段到达之前都不会尝试播放该帧。
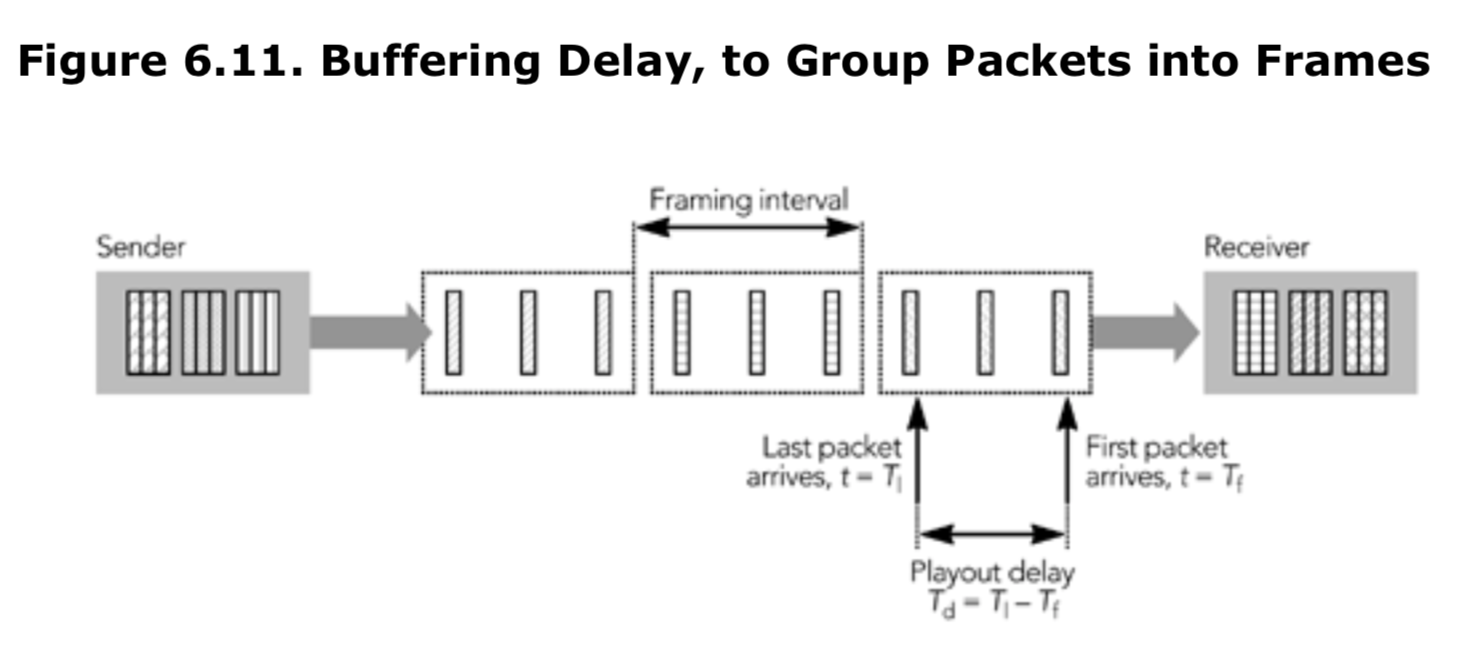
如果我们知道帧之间的时间间隔和每帧的数据包数量,那么插入额外的延迟就会变得很简单。假设发送者发送数据包的间隔是均匀的,那么我们可以进行以下调整:
adjustment_due_to_fragmentation = (packets_per_frame – 1) x (interframe_time / packets_per_frame)
不幸的是,接收者并不能总是提前知道这些变量。例如,在会话设置期间可能没有信令告知帧率,会话期间帧速率可能会变化,或者会话期间每帧的数据包数量可能会变化。这种变化可能会使得调度播放变得困难,因为不清楚需要添加多少延迟才能让所有片段到达。接收方必须估计所需的播放延迟,并在估计不准确时做出适应。
一个专门的模块复杂计算播放延时补偿,根据分片的到达时间来计算平均片片延迟。幸运的是,这不是唯一的计算方式,抖动计算可以起到同样的作用。一个帧的所有数据包具有相同的时间戳,表示帧的采集时间,而不是数据包发送的时间,因此分割的帧会导致接收抖动的出现(接收方无法区分在网络中延迟的数据包还是因为发送方延迟的数据包)。因此,下一节将讨论的抖动补偿策略可以用来估算必需的缓冲延迟来弥补分片带来的影响,而不需要在播放延迟机制中考虑分片问题。
如果发送方使用第9章中描述的纠错技术,就会出现类似的问题。为了让纠错包发挥作用,需要延迟播放,以便纠错包能够及时到达并被使用。纠错包的存在会在会话设置期间进行信令,并且信令可能包含足够的信息,使接收方能够正确调整播放缓冲区的大小。或者,正确的播放延迟必须从媒体流中推断出来。所需的补偿延迟取决于所采用的纠错类型。常见的三种纠错类型是奇偶FEC(前向纠错)、音频冗余和重传。
在第9章中讨论的错误纠正中,音频冗余方案包括在冗余数据包中使用时间偏移量,该偏移量可以用于确定播放缓冲区的大小。在对话开始时,冗余音频可以有两种方式:初始数据包可以不带冗余标头发送,或者可以带有零长度的冗余块。如图6.12所示,如果对话的初始数据包包含零长度的冗余块,可以更方便确定播放缓冲区的大小。然而,标准没有强制要求包含这些块,如果没有,可能需要估算出适当的播放延迟。在信息不足的情况下,常用方法是利用单个数据包的偏移值进行一个合理的估算。一旦确定了媒体流是否使用冗余,就应将偏移量应用于该流中的所有数据包,包括在对话开始时没有冗余的数据包。如果收到了完整的对话段而没有冗余,可以假设发送方已停止发送冗余数据包,未来的对话段可以无延迟播放。
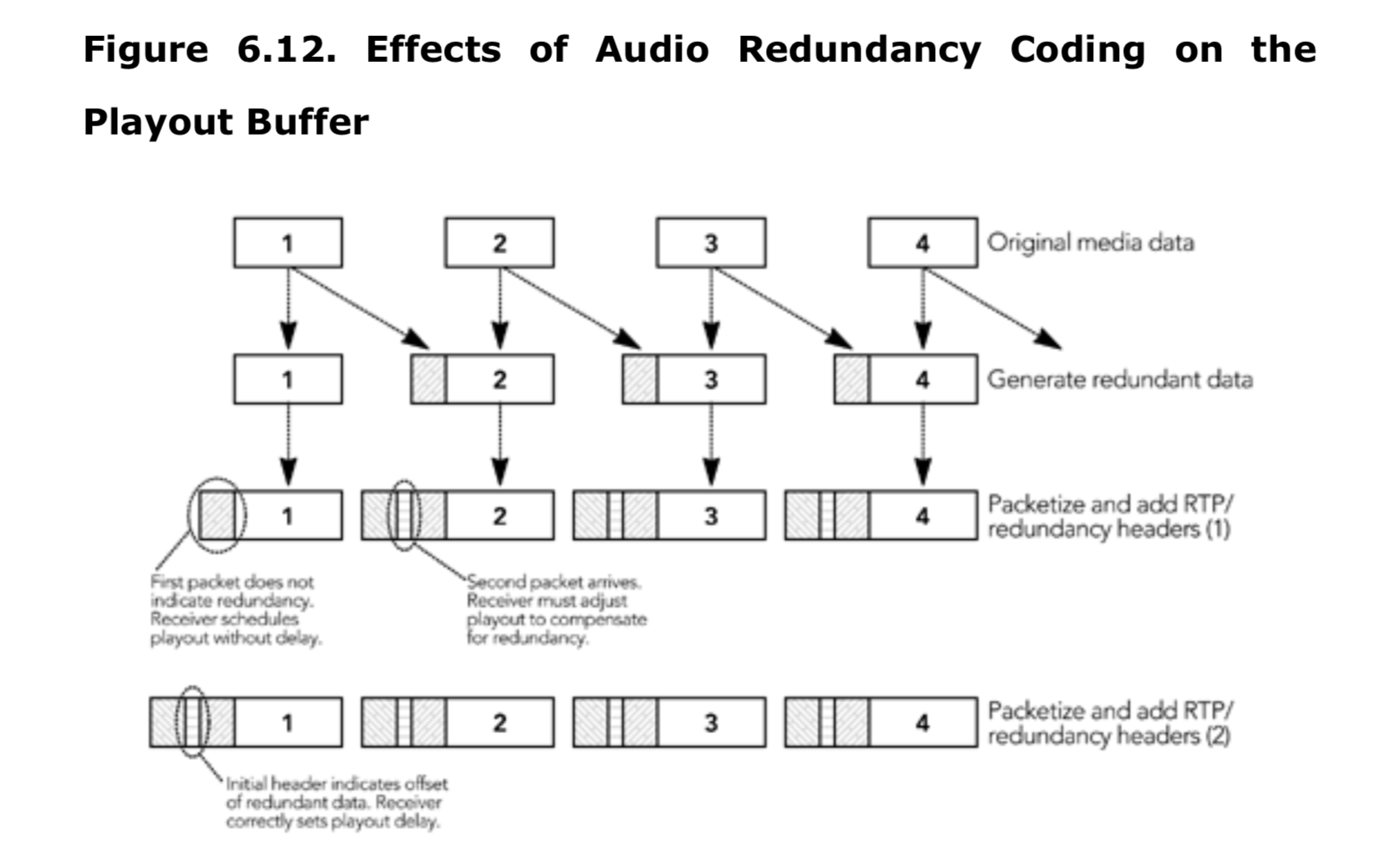
如果使用了奇偶校验 FEC 或冗余,接收者最初应该选择一个大的播放延迟,以确保到达的任何数据包都进入缓冲区。当第一个错误恢复包到达时,它将导致接受方减少它的播放延迟,重新安排时间,并播放当前缓冲的包。这个过程避免了由于缓冲延迟的增加而导致的播放间隙,代价是初始包会稍微延迟。
当使用包重传机制时,播放缓冲区的大小必须大于发送方和接收方之间的往返时延,以支持重传请求的往返和服务。接收方无法获知往返时延,只能通过发送重传请求来估测它。这对大多数实施没有影响,因为重传通常用于非交互应用,在这类应用中,播放缓冲延迟一般大于往返时延。但如果往返时延过大,可能会引起问题。
无论采用何种纠错方案,发送者都可能产生超量的纠错数据。例如,在向多播组发送数据时,发送端可能根据最差条件下的接收端选择错误纠错码,这对其他接收端来说可能过于保守。如Roseno-Berg等研究人员指出,仅利用部分错误纠错数据就可能修复部分数据丢失。在这种情况下,接收端可以选择比完全利用所有纠错数据需要的延迟更小的播放延迟,而不是等待足够长时间来修复其选择修复的损失部分。忽略某些纠错数据的决定,完全是由接收者根据其对传输质量的看法做出的。
最后,如果发送者使用了交织媒体流 -- 如第八章所述,错误隐藏 -- 接收者必须在播放计算中考虑这一点,这样才能将交织的数据包按照播放顺序排序。交织参数通常在会话设置期间发出信令,允许接收者选择适当的缓冲延迟。例如,AMR 有效负载格式定义了一个交织参数,该参数可以在 SDP a = fmtp:行中发出信令,表示每个交织组数据包的数量(因此应该插入到播放缓冲区中进行补偿的数据包数量方面的延迟量)。其他支持交织的编解码器应该提供类似的参数。
总而言之,发送者可以通过三种方式影响播放缓冲区:通过对帧进行分段和延迟发送分段,通过使用纠错包或通过交织。 其中的第一个将根据常规的抖动补偿算法进行补偿。 其他要求接收机调整播放缓冲区以进行补偿。这种补偿主要对于使用小的播放缓冲区来减少延迟的交互式应用程序而言是一个问题;而流媒体系统可以简单地设置较大的播放缓冲区。
抖动补偿
当 RTP 数据包流经真实 IP 网络时,数据包间时序的变化是不可避免的。 这种网络抖动可能很大,接收者必须通过在播出缓冲区中插入延迟补偿,以便可以处理网络延迟的数据包。延迟过大的数据包在其播放时间过去之后到达,会被丢弃; 选择适当的播出算法后,这种情况很少发生。图 6.13 显示了抖动补偿过程。
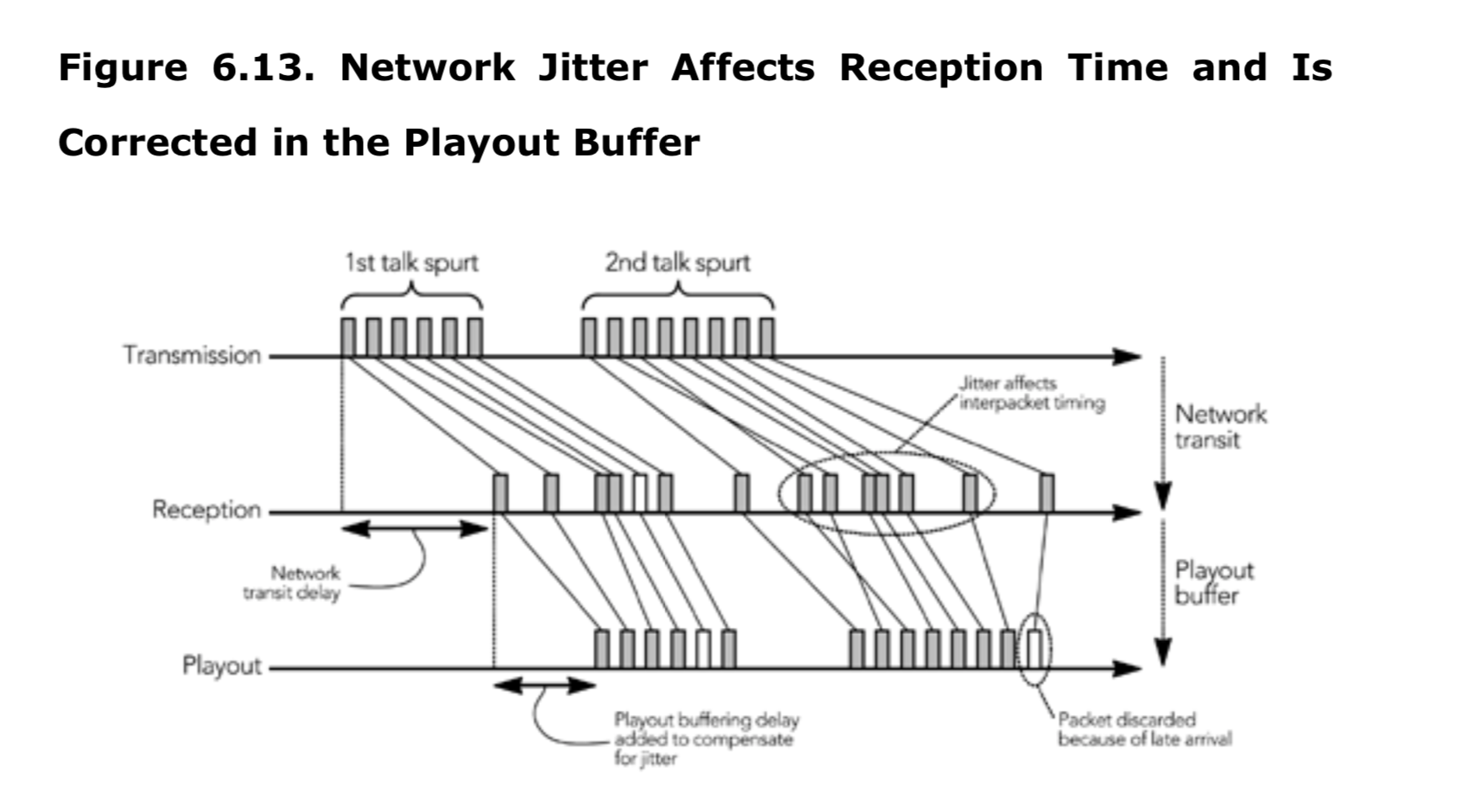
抖动补偿延迟的计算,没有标准算法;大多数应用程序都希望自适应的计算播放延迟,可以根据应用程序类型和网络条件使用不同的算法。为非交互式场景设计的应用程序可以选择一个远远大于预期抖动的补偿延迟,甚至几秒都是合适的。更复杂的是交互情况下,应用程序希望保持输出延迟尽可能小(考虑到特定的网络和分组延迟,数十毫秒的值也是可能的)。为了使播放延迟最小化,有必要研究抖动的特性,并利用这些特性获得最小的适当播放延迟。
大多数情况,网络引起的抖动基本上是随机的。包间到达时间(interpacket arrival time)与出现频率(frequency of occurrence)的关系图如图 6.14 的高斯分布有点儿类似。大多数数据包仅受到网络抖动的轻微影响,但是某些异常值则明显延迟或与相邻的数据包粘包(neighboring packet);
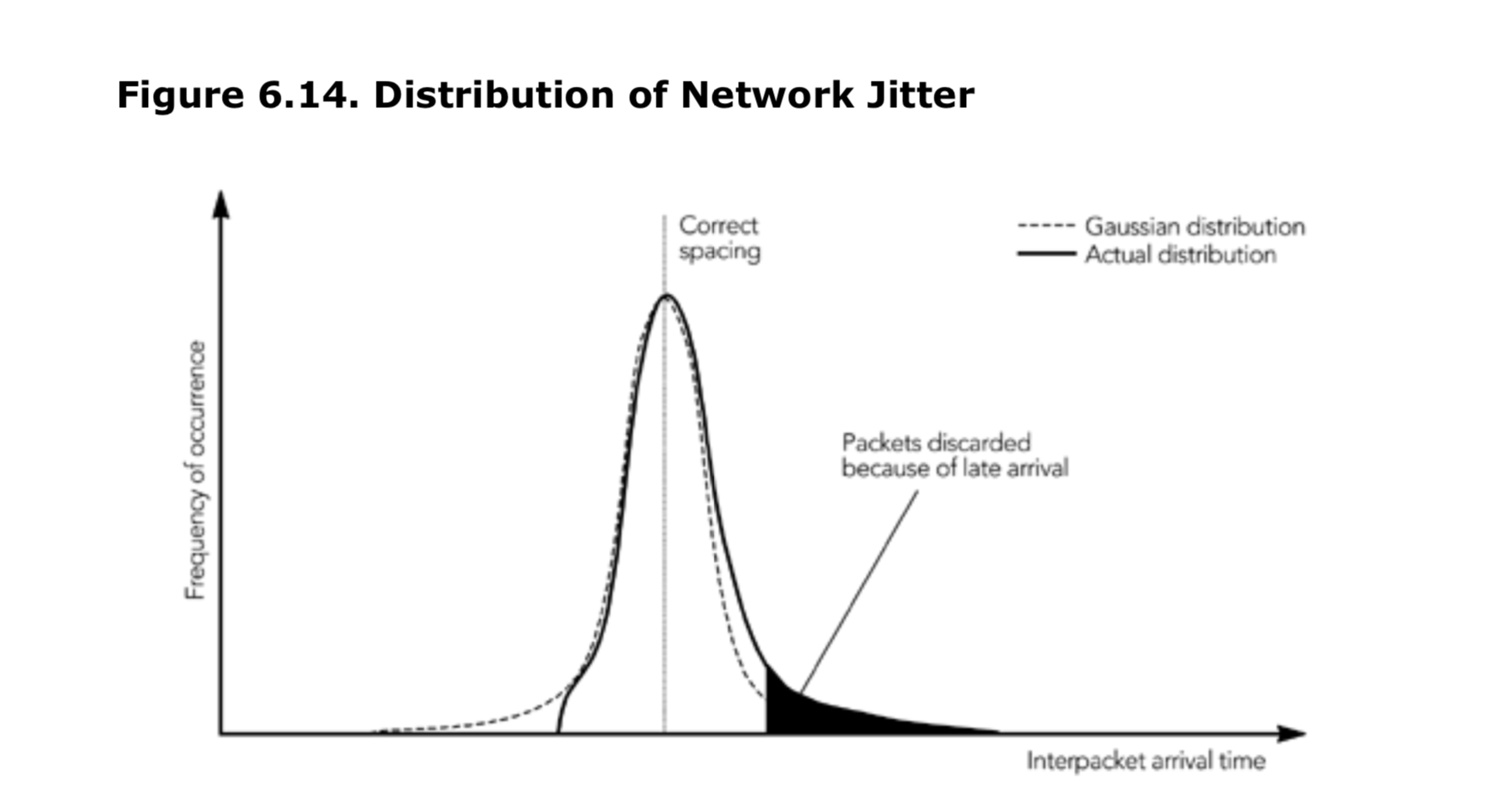
这个近似值有多精确取决于网络的路径,但是我和 Moon 等人进行的测量表明,在许多情况下,这种方案是近似合理的,尽管现实世界中的数据通常会偏向较大的到达时间,并且具有急剧的最小截止值(如图 6.14 的“实际分布”所示)。这种差异通常不是关键的,因为丢弃区域中的数据包数据量很少。
如果可以假设抖动分布近似于高斯正态分布,那么就很容易推导出合适的播放延迟。抖动的标准差是计算出来的。根据概率论,我们知道 99%以上的正态分布在均值(平均值)标准差的三倍以内。一个实现可能会选择一个等于到达间隔时间标准偏差的三倍的播放延迟,并希望由于延迟到达而丢弃少于 0.5%的数据包。如果此延迟过长,则使用延迟时间为标准差的两倍时,由于延迟到达产生的预期的丢弃率将会少于 2.5%,这也是基于概率论。
我们如何测量标准差?计算用于插入 RTCP 接收者报告的抖动值,跟踪网络传输时间的平均变化,该变化可以当作近似标准偏差。根据这些近似值,可以将补偿网络抖动所需的播放延迟预估为源 RTCP 抖动的三倍。新一帧的播放延迟可以设置为:
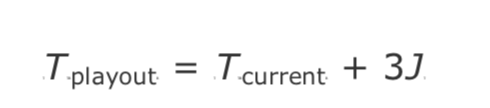
其中 J 为对当前抖动的预估,如第五章 RTP 控制协议所述。playout的值可以按照媒体类型进行相应的修改,如后面所讨论的。真实世界里,使用该值作为播放计算的基础表现出了良好的性能。
抖动分布既取决于流量在网络中的传输路径,也取决于与其共享该路径的其他流量。抖动的主要原因是与其他流量的竞争,导致中间路由器的排队延迟不断变化;显然,其他流量的变化也会影响接收方所感知到的抖动。因此,接收方应定期重新计算所使用的播放缓冲延迟,以适应网络行为的变化,并在必要时进行调整。接收方应该在何时进行适应?这并不是一个简单的问题,因为在媒体播放时改变播放延迟会打断播放,导致要么出现中断,要么迫使接收方丢弃一些数据来弥补时间损失。因此,接收方尽量限制调整播放点的次数。有几个因素可以触发适应:
- 由于延迟而丢弃的数据包的比例显著变化
- 接收几个连续的必须而被丢弃的包,原因是延迟到达(三个连续的数据包是一个合适的阀值)
- 接收到来自长时间不活跃发送者的信息包(10 秒是合适的阀值)
- 网络传输延迟出现尖峰
除了网络传输延迟的峰值外,这些因素应该是不言自明的。如第二章第 2 节的图 2.12 所示,当几个数据包被延迟并突发时,网络有时会导致传输延迟中出现“尖峰”信号。这样的峰值很容易使抖动预估值产生偏差,导致应用程序选择比要求的更大的播放延迟。在许多应用程序中,这种播放延迟的增加是可以接受的,应用程序应该将尖峰视为其他形式的抖动,并增加播放延迟来进行补偿。然后,一些应用程序更喜欢增加丢包而不是增加延迟。这些应用程序应该检测延迟尖峰的开始,并在计算播放延迟时,忽略尖峰中的包。
检测延迟尖峰的开始很简单:如果连续数据包之间的延迟突然增加,就可能发送了延迟尖峰。“突然增加”的规模可以有一些解释:Ramjee 等人认为,到达间隔时间统计方差的两倍加上 100 毫秒是一个合适的阈值;我熟悉的另一个实现,用了 375 毫秒的固定阈值(都是使用 8KHz 语音的 ip 语音系统)。
某些媒体事件还会导致连续包之间的延迟增加,不应将其与延迟峰值开始混淆在一起。例如,音频静音抑制将导致在一个通话突发中的最后一个数据包,与下一个通话突发中的第一个数据包之间出现间隙。同样,视频帧速率的变化也会导致包的时序发生变化。在假定数据包间延迟的变化,就意味着出现了一个尖峰之前,应该先检查此类事件。
一旦检测到延迟脉冲,应该暂停正常的抖动调整,直到脉冲结束。这个操作的结果就是几个包可能会因为延迟到达而被丢弃,但是假设应用程序有严格的延迟边界,那么相比于增加播放延迟,这个结果是可接受的。
定位一个尖峰的末端比探测它的开始要困难。延迟尖峰的一个关键特征是,在尖峰之后,在发送者均匀间隔的数据包将以突发的形式到达,这意味着每个数据包的传输延迟将逐渐减小,如图 6.15 所示:
考虑到所有的这些因素,补偿抖动和延迟尖峰影响的播放延迟的伪代码如下:
int
adjustment_due_to_jitter(...)
{
delta_transit = abs(transit – last_transit);
if (delta_transit > SPIKE_THRESHOLD)
{
// A new "delay spike" has started
playout_mode = SPIKE;
spike_var = 0;
adapt = FALSE;
}
else
{
if (playout_mode == SPIKE)
{
// We're within a delay spike; maintain slope estimate
spike_var = spike_var / 2;
delta_var = (abs(transit – last_transit) + abs(transit
last_last_transit))/8;
spike_var = spike_var + delta_var;
if (spike_var < spike_end)
{
// Slope is flat; return to normal operation
playout_mode = NORMAL;
}
adapt = FALSE;
}
else
{
// Normal operation; significant events can cause us to
//adapt the playout
if (consecutive_dropped > DROP_THRESHOLD)
{
// Dropped too many consecutive packets
adapt = TRUE;
}
if ((current_time – last_header_time) > INACTIVE_THRESHOLD)
{
// Silent source restarted; network conditions have
//probably changed
adapt = TRUE;
}
}
}
desired_playout_offset = 3 * jitter
if (adapt)
{
playout_offset = desired_playout_offset;
}
else
{
playout_offset = last_playout_offset;
}
return playout_offset;
}
关键点是在延迟峰值期间,抖动补偿被暂停,而实际的播放时间只在发生重要事件时才会改变。在其他时间,desired_playout_offset被存储,以在特定时间(参见标题为"调整播放点"的部分)恢复。
路由变更补偿
虽然很少发生,但是,由于链路故障或者拓扑结构发生改变,路由更改就会出现在网络中。如果 RTP 包所传输的的路由发生了变化,将表现为网络传输时间的突然变化。这个变化将会打乱播放缓冲区,因为要么数据包到达得太晚而无法播放,要么它们将提前到达并与之前的数据包重叠。
抖动和延迟峰值补偟算法应检测延迟变化,调整播放进行补偿,但这可能不是最优方法。如果接收端直接观测网络传输时延并根据较大变化调整播放延迟,就可以实现更快的自适应。例如,如果传输延迟变化超过当前抖动估计值的5倍,则调整播放延迟。因为网络传输时延用于部分抖动计算,所以这种观测很简单。
对包重新排序的补偿
在极端的情况下,抖动或者路由的更改,可能导致网络中的包被重排序。正如第二章“分组网络上的音视频通信”中所讨论的,这种情况通常很少发生,但是这种情况发生的频度足够引起重视,实现时需要能够补偿它的影响,并平稳的处理包含乱序包的媒体流。
对于设计正确的接收者来说,重新排序应该不是问题,数据包根据它们的 RTP 时间戳插入到播放缓冲区,而不考虑它们到达的顺序。如果播放延迟足够大,则按正确的顺序播放。否则,它们将像其他延迟的包一样被丢弃。如果许多包由于重新排序和延迟到达而被丢弃,抖动补偿算法将负责调整播放延迟。
播放点自适应
调整播放点的方法有两种基本方式:接收方可以对每帧的播放时间进行微调,持续进行小幅度的调整;或者可以在媒体流中插入或删除完整的帧,根据需要进行较少次数的大幅度调整。无论采用哪种方式进行调整,媒体流都会在某种程度上受到干扰。适应的目标是最大程度地减少这种干扰,这需要对媒体流有深入的了解;因此,音频和视频的播放适应策略需要单独进行讨论。
用静音抑制调整音频播放
音频是一种连续的媒体格式,每个音频帧都占用一定的时间,下一个音频帧会在前一个帧完成后立即开始。除非使用了静音抑制技术,否则帧之间不会有间隔,因此没有合适的时机来调整播放延迟。正因为如此,静音抑制对音频播放缓冲算法的设计具有重要影响。
在对话性语音信号中,发言人的说话会间隔几百毫秒,间隙期间为静默期。图6.16展示了语音信号中说话间隔及其间隙的存在。发送方会检测到表示静默期的帧,并抑制为这些帧产生的RTP数据包。结果,数据包序列号连续,但RTP时间戳会根据静默期长度发生跳跃。
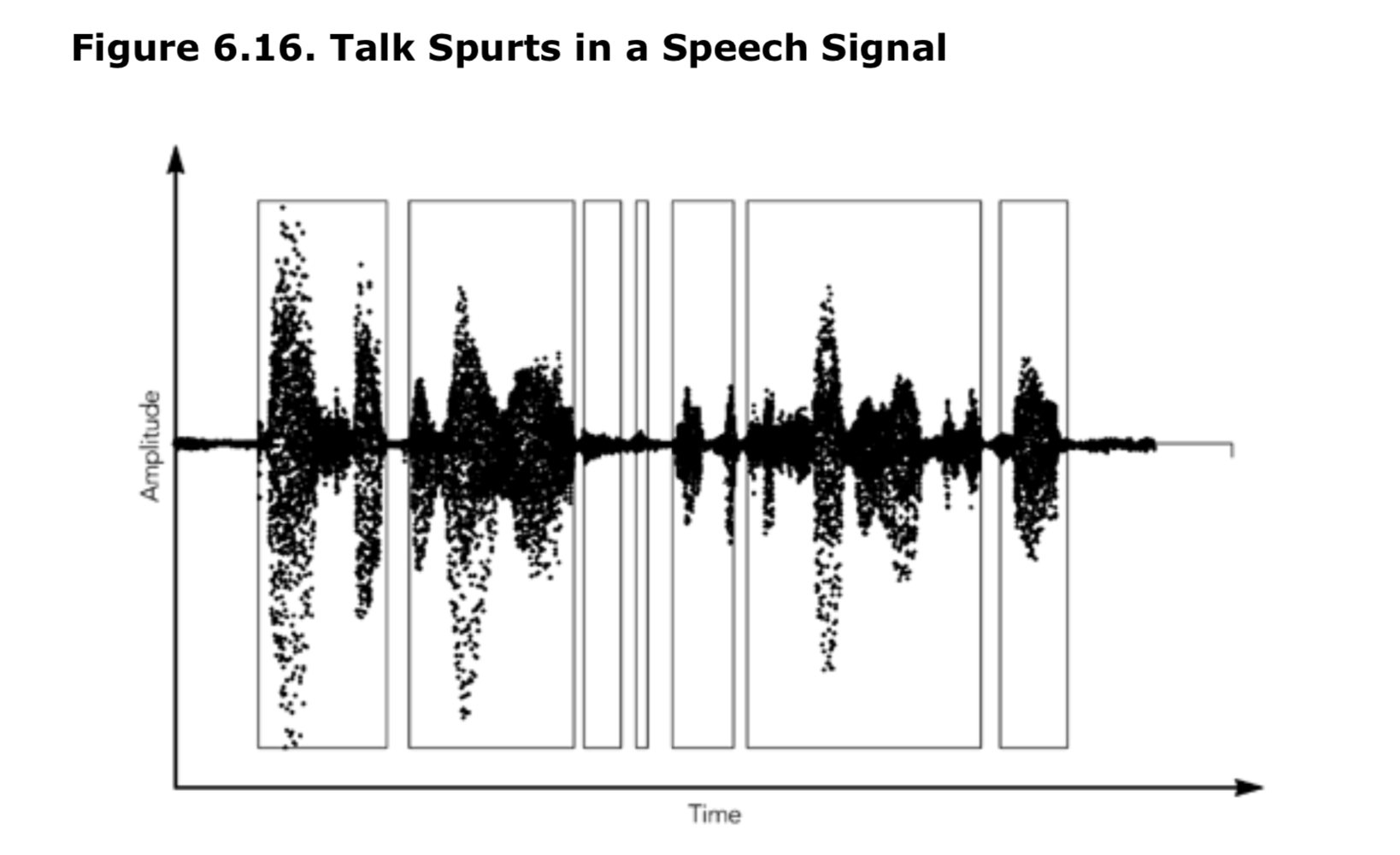
在说话间隔期间调整播放点会在输出中产生明显的故障声,但是在说话间隔之间的静默期长度发生微小变化是不会被注意到的。这是在设计音频工具的播放算法时需要牢记的关键要点:如果可以的话,只在静默期间调整播放点。
通常情况下,接收方能够很容易地检测到说话间隔的开始,因为发送方在静默期后的第一个数据包上会设置标记位,明确表示说话间隔的开始。有时在说话间隔起始时,第一个数据包可能会丢失。通过序列号和时间戳的变化通常还是可以判断新的说话间隔开始,如图6.17所示,这提供了判断标准。
一旦确定了说话间隔的开始,你可以通过微调静默期的长度来调整播放点。然后,在整个说话间隔中,播放延迟保持不变。在每个说话间隔期间计算出适当的播放延迟,并用于调整接下来的说话间隔的播放点,这是基于一个假设:在说话间隔之间,网络情况不太可能发生显著变化。
一些语音编解码器在静音期间发送低速率的舒适噪声帧,以便接收者可以播放适当的背景噪声,以获得更愉快的收听体验。接收到一个舒适的噪声包表明一个谈话的结束,和一个适当的时间来调整播放延迟时机的开始。舒适噪声周期的长度可以改变,但对音频质量没有显著影响。RTP 有效负载类型通常不会标识出舒适噪声帧,因此,有必要通过检查媒体数据判断是否是舒适噪音。对于不支持本地舒适噪声的旧编解码器,可能会使用RTP有效负载格式来传输舒适噪声,其RTP有效负载类型为13。
在特殊情况下,可能有必要在通话尖峰期进行调整 -- 例如,如果多个数据包由于延迟到达而被丢弃。这些情况预计会很罕见,因为通话尖峰相对较短,网络条件通常变化缓慢。
将这些特性结合起来产生如下伪代码,以确定适当的时间来调整播放点,假设使用了静音抑制,如下所示:
int
should_adjust_playout(rtp_packet curr, rtp_packet prev, int contdrop)
{
if (curr->marker)
{
return TRUE; // Explicit indication of new talk spurt
}
delta_seq = curr->seq – prev->seq;
delta_ts = curr->ts - prev->ts;
if (delta_seq * inter_packet_gap != delta_ts)
{
return TRUE; // Implicit indication of new talk spurt
}
if (curr->pt == COMFORT_NOISE_PT) || is_comfort_noise(curr))
{
return TRUE; // Between talk spurts
}
if (contdrop > CONSECUTIVE_DROP_THRESHOLD)
{
contdrop = 0;
return TRUE; // Something has gone badly wrong, so adjust
}
return FALSE;
}
变量 contdrop 是由于不在适当的播放时间而丢弃的连续数据包的数量。例如,如果路由更改导致数据包到达时间太晚而无法播放。连续丢包阈值CONSECUTIVE_DROP_THRESHOLD 的一个合适值是三个数据包。如果should_playout()返回TRUE,接收端要么处于静音期,要么错误计算了播放点。如果计算的播放点偏离当前值,应通过调整计划播放时间来调整未来包的播放点。无需生成填充数据,直接播放静音或舒适噪音,直到下个数据包调度播放。
当播放延迟正在减少时,需要注意,因为条件的重大变化,可能会使下一个讲话的突然开始时间提前到,与一个讲话突然结束的时间重叠。由于不希望限制通话期的开始,因此可执行的调整量会受到限制
音频无静音抑制的播放调整
当接收到没有静默抑制的音频时,接收方必须在音频播放过程中调整播放点。最理想的适应方式是调整本地媒体时钟以与发送方保持一致,这样数据就可以直接播放出来。如果由于缺乏必要的硬件支持而无法实现这一目标,接收方将不得不通过生成填充数据插入到媒体流中,或者从播放缓冲区中删除一些媒体数据来变化播放点。无论采用哪种方法,都不可避免地会对播放造成一些干扰,因此重要的是要隐藏适应的效果,以确保不会干扰听众。
根据输出设备的性质和接收者的资源,有几种可能的自适应算法:
- 音频可以在软件重采样,以匹配输出设备的速率。标准信号处理教程提供了各种算法,这取决于所需的质量和资源之间的权衡。这是一个很好的通用解决方案。
- 根据对媒体的了解,可以对播放延迟进行逐个样本的调整。例如,Hodson 等人使用模式匹配算法来检测语音中的音调周期,这些音调周期会被删除或复制以适应播放效果(音调周期比完整帧要短得多,因此这种方法可以实现细粒度的适应)。与重采样相比,此方法可以执行得更好,但是它是特定于内容的。
- 完整的帧可以插入或者删除,就像数据包丢失或重复一样。这种算法质量通常不高,但是,如果使用了专为同步网络而设计的硬件解码器,则可能需要这种算法。
在没有静音抑制的情况下,调整播放点的时机并不明显。然而,接收方仍然可以根据情况做出明智的选择,根据编解码器和错误隐藏算法,在相对安静或信号高度重复的时期进行自适应播放。关于错误隐藏的策略,可以在第8章的错误隐藏一章中找到详细的描述。
视频播放自适应
视频是一种离散的媒体格式,在这种格式中,每一帧都在特定的时间点采样,帧与帧之间的间隔不会被记录。视频的离散特性,为播放算法提供了灵活性,可以允许接收者通过稍微改变帧间计时来自适应播放。不幸的是,显示设备通常以固定的速率运行,视频不能在任意时间显示。因此,视频播放成为了一个问题,即如何尽量减小期望的帧呈现瞬间与可能的帧呈现瞬间之间的偏差。
举个例子,考虑一下在刷新率为 85Hz 的监视器上显示每秒 50 帧的视频的问题。在这种情况下,监视器刷新时间将与视频播放时间不匹配,这将不可避免的导致帧呈现给用户的时间发生变化,如图 6.18 所示。只有改变采集设备的帧速率或者显示的刷新率才能解决这个问题。在实践中,这个问题目前是无解的,因为视频采集和回放设备通常对可能的速率有硬件限制。即使采集和回放设备,在名义上具备相同的速率,也可能需要根据抖动或者时钟偏移的影响播放。
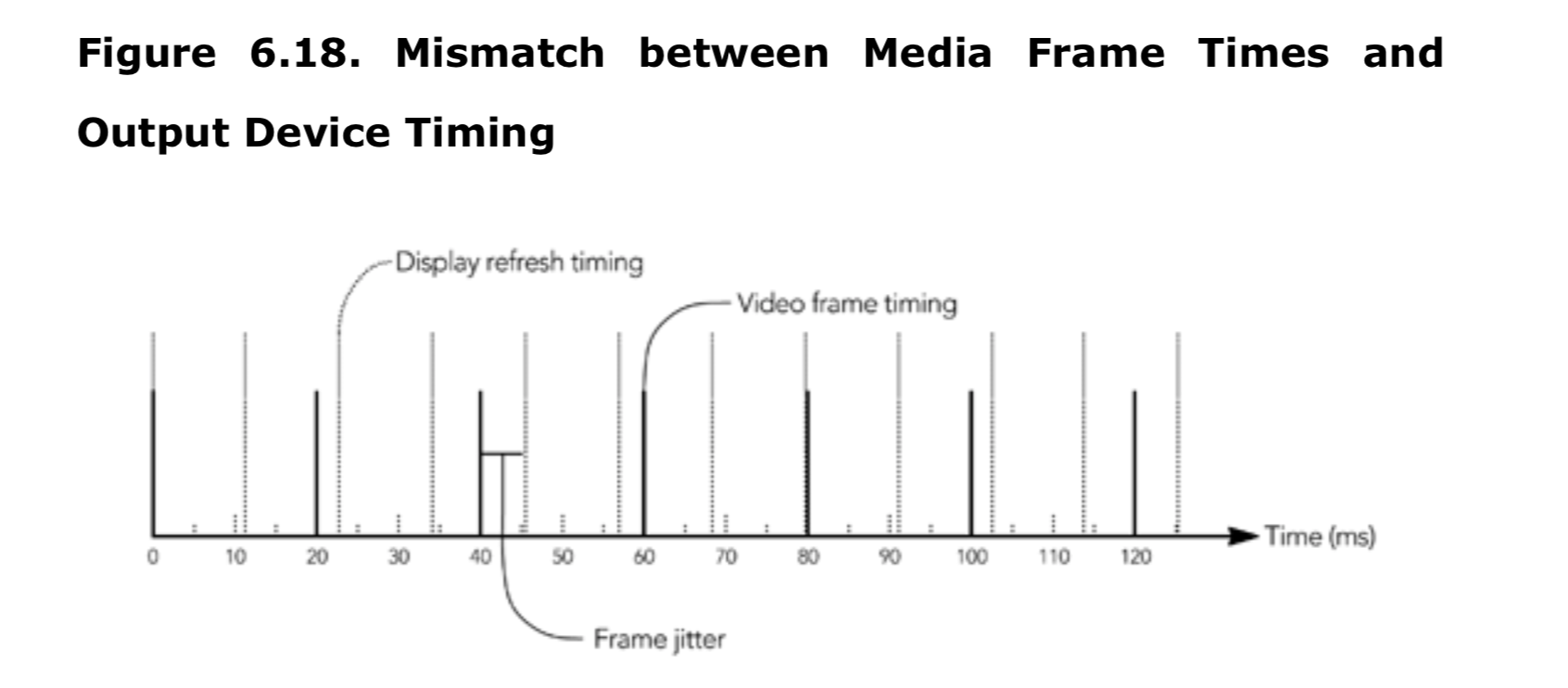
存在三种可能的调整情况:(1)当显示设备的帧率高于采集设备时;(2)当显示设备的帧率低于采集设备时;(3)当显示和采集设备以相同帧率运行时。
如果显示设备的帧率高于采集设备的帧速率,则可能的显示时间将围绕所需时间,并且每个帧都可以映射到唯一的显示刷新间隔。 最简单的方法是以最接近其播放时间的刷新间隔显示帧。可以通过朝任何所需的播放调整方向移动帧来获得更好的结果:如果接收者时钟相对较快,则在其播放时间之后的刷新间隔显示帧,如果接收者时钟较慢则以较早的间隔显示帧。当没有从发送者收到新帧时,可以通过重复前一帧来填充中间刷新间隔。
如果显示设备的帧率低于采集设备,则不可能显示所有帧,并且接收者必须丢弃一些数据。例如,接收者可以计算帧播放时间和显示时间之间的差异,并选择显示最接近可能显示时间的帧子集。
如果显示设备和采集设备以相同的速度运行,则可以滑动播放缓冲区,使得帧的显示时间与显示刷新时间一致,且滑动会提供一定程度的抖动缓冲延迟。这是一种不常见的情况:时钟偏移是常见的,周期性的抖动调整可能会打乱时间轴。根据需要调整方向,接收者必须插入或移除一个帧来进行补偿。
可以通过在播放序列中重复一帧来插入。请注意,人眼对不均匀播放很敏感。接收者应尽量保持帧间播放时间一致,避免干扰。在较小的播放调整被证明不够时,插入或删除帧才最后被选择。
解码、混合和播放
播放过程的最后阶段包括解码压缩媒体、将多个媒体流混合在一起(如果输出通道少于活动源),最后将媒体播放给用户。本节将逐个介绍每个阶段。
解码
对于每个活跃的源,应用程序必须维护媒体解码器的实例,包括解码缩实例以及编码上文的状态。根据系统的不同,解码器可以是实际的硬件设备,也可以是软件实现。它根据帧中的数据和编码上下文,将每个编码帧转换为未编码的媒体数据。当帧被解码时,源的编码上下文将被更新,如图 6.19 所示。
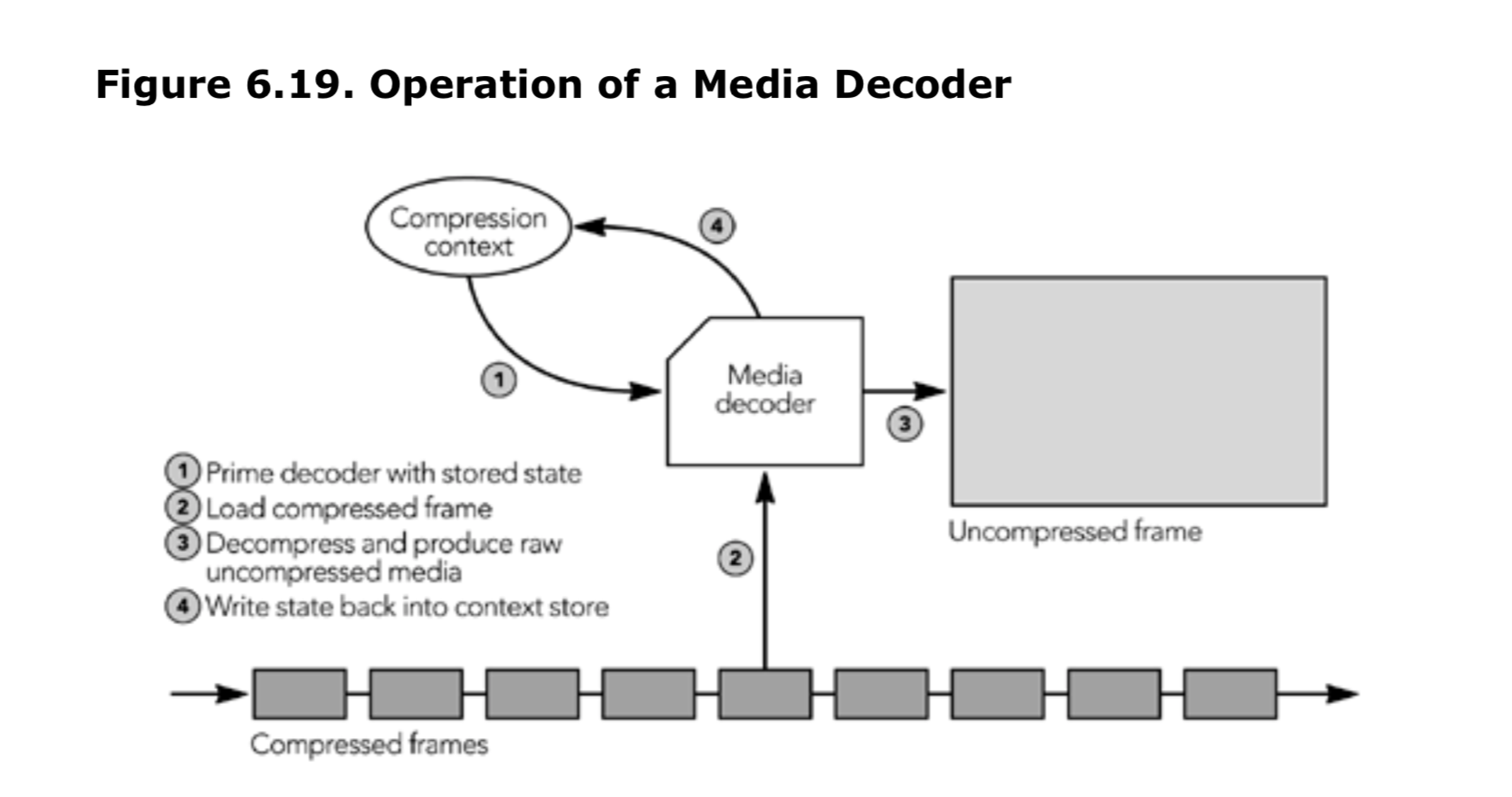
解码器的正确操作依赖于准确的解码上下文状态。如果上下文丢失或损坏,编解码器将产生错误的结果。这是最常见的问题之一,当某些数据包丢失时,会导致无法解码的帧。结果就是在原本应该播放帧的位置会出现空隙,并且解码上下文也会失效,从而影响后续帧的解码
根据编解码器的不同,可以编解码器提供帧丢失的指示,以便解码器更好地修复上下文并减少对媒体流的损坏(例如,许多语音编解码器使用擦除帧来表示丢失)。否则,接收方应尝试修复上下文并掩盖数据丢失的影响,如《第8章,错误掩盖》中所讨论的那样。许多丢失掩盖算法在解码后、混合和播放操作之前对未压缩的媒体数据进行处理。
混音
混音是将多个媒体流合并为一个输出的过程,主要在音频应用中存在问题,因为大多数系统只有一套扬声器,但可能有多个活动源,例如多方电话会议。一旦音频流被解码,它们必须在写入音频设备之前进行混合。音频最后阶段通常的结构类似于 6.20 所示。解码器按照源的方式生成未压缩的音频数据,写入每个源的播放缓冲区,然后混音器将这些结果合并到一个用于播放的单一缓冲区中(如果解码器能够理解混音过程,这些步骤当然可以合并为一个)。混音可以在播放之前任意时间进行。
混音缓冲区最初是空的,即充满了静音,每个参与者的音频依次混合到缓冲区中。最简单的混音方法是使用饱和加法,其中每个参与者的音频依次加入到缓冲区中,溢出条件是在极值处饱和。在伪代码中,假设有 16bit 样本,并将一个新的参与(src)混合到缓冲区(mix_buffer)中,这将变成:
audio_mix(sample *mix_buffer, sample *src, int len)
{
int i, tmp;
for(i = 0; i < len; i++)
{
tmp = mix_buffer[i] + src[i];
if (tmp > 32767)
{
tmp = 32767;
}
else if (tmp < -32768)
{
tmp = -32768;
}
mix_buffer[i] = tmp;
}
}
如果需要更高保真度的混音,可以使用其他算法。SIMD 处理器通常有混合采集样本的指令。 例如,英特尔 MMX(多媒体扩展)指令包括饱和加法指令,该指令一次添加四个 16bit 样本,并且由于混合循环不再有分支检查,因此性能最高可提高十倍。
实际的混合缓冲区可以使用循环缓冲区的方式来实现。该缓冲区被实现为一个数组,包含起始和结束指针,通过循环回到起始位置,给人以缓冲区是连续的错觉。
简单的循环缓冲区不能始终提供一个连续的可读取缓冲区,这是它的一个缺陷。当读取接近循环点时,需要返回两个混合数据块:一个来自循环缓冲区的末尾,一个来自开头。如果分配两倍所需大小的数组,则可以避免返回两个缓冲区。如果读取请求的块包含了循环缓冲区的循环点,混音器可以将数据复制到额外的空间,并返回一个指向连续内存块的指针,如6.22所示。这需要额外复制音频数据,最多占循环缓冲区大小的一半,但允许读取返回一个连续的缓冲区,简化了使用混音器的代码。循环缓冲区的正常操作不变,除了在读取数据时会进行一次复制。
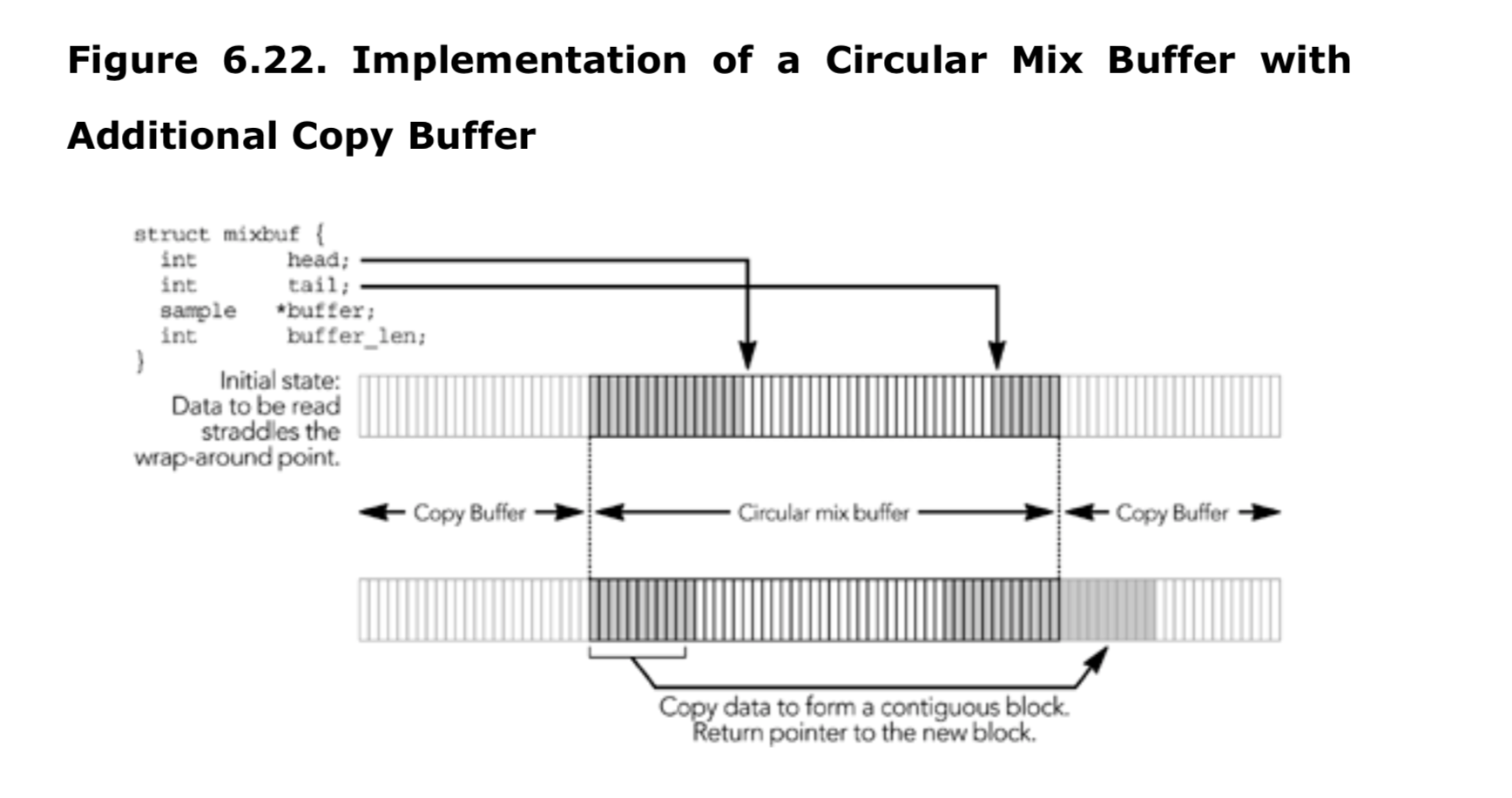
音频的播放
音频向用户播放的过程通常是异步的,即系统在处理下一个音频帧时可以播放当前的音频帧。这种能力对于系统正常运行至关重要,因为它可以实现连续播放,即使应用程序忙于RTP和媒体处理。同时,还可以保护应用程序免受系统行为变化的影响,例如由于其他在该系统上运行的应用程序的存在。
在支持有限的通用操作系统上,异步播放对于多媒体应用程序尤其重要。这些系统通常被设计为具有良好的平均响应,但往往在最坏情况下表现不理想,并且无法保证对实时应用程序进行适当的调度。应用程序可以利用异步播放的优势,通过使用音频DMA(直接内存访问)硬件来实现连续播放。如图6.23所示,应用程序可以监测输出缓冲区的占用情况,并根据自上次调度以来的时间调整向音频设备写入的数据量,以确保每次迭代后缓冲区的占用保持恒定。
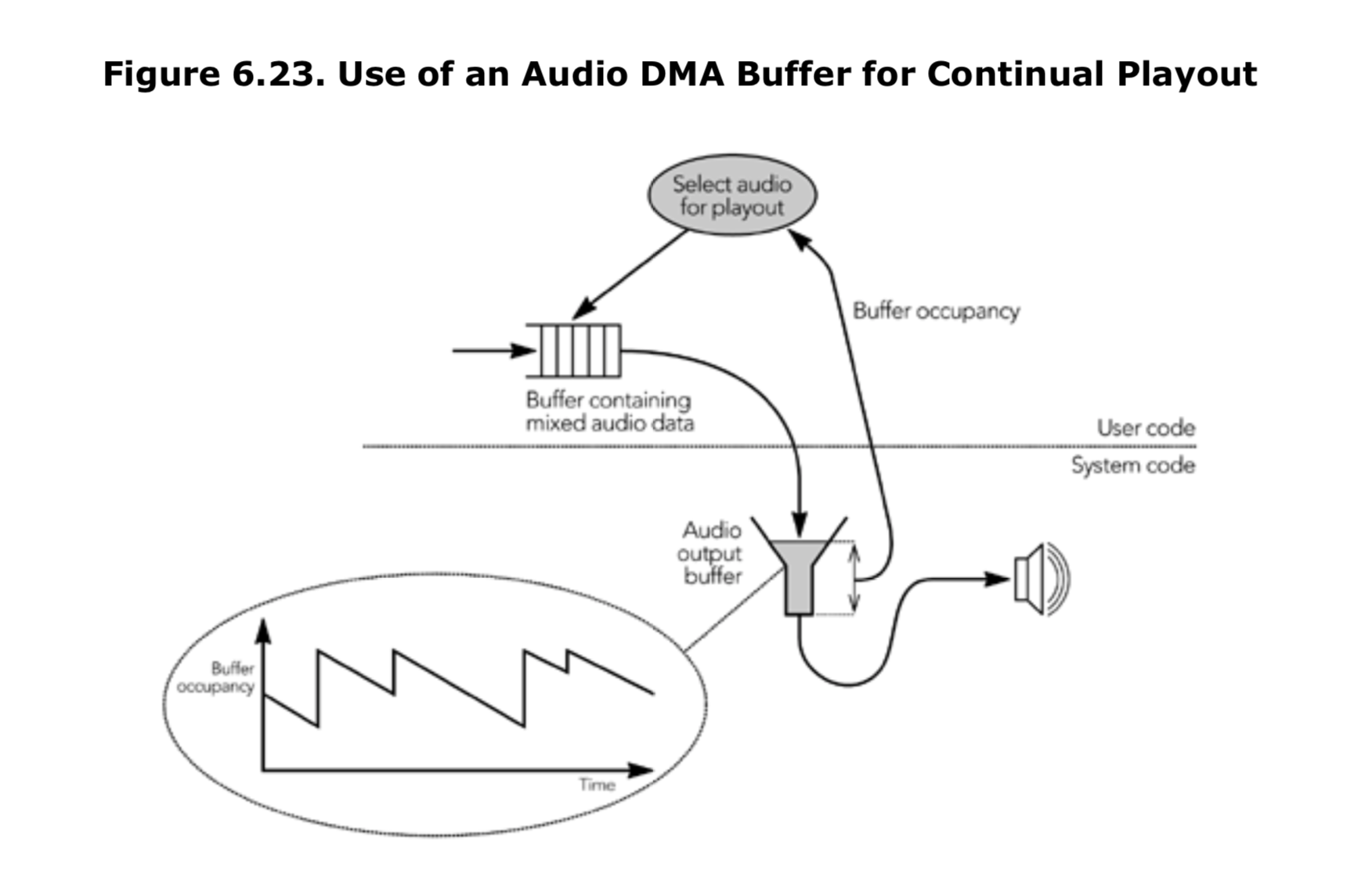
如果应用程序检测到异常的调度延迟期(可能是由于系统上的磁盘活动过大),可以预先增加音频DMA缓冲区的大小。如果操作系统不允许直接监视音频缓冲区的数量和等待播放的情况,可能可以通过应用程序编码端等待读取的音频数量来估算。大多数情况下,音频播放和录制都是由同一个硬件时钟驱动的,因此应用程序可以计算它记录的音频样本数量,并利用这些信息推导出播放缓冲区的占用情况。通过仔细监测音频DMA缓冲区,可以确保在除了极端环境之外实现持续的播放。
视频播放
视频播放很大程度上是由显示器的刷新率决定的,它决定了应用程序写入到输出缓冲区,到将图像呈现给用户之间的最大时间间隔。平滑视频播放的关键是两个方面:(1)帧应该以均匀的速率呈现,(2)在视频呈现时,应该避免帧的变化。第一点是关于播放缓冲区的问题,选择适当的显示时间,如本章前面的视频播放调整部分所述。
第二点与显示有关:帧不是即时呈现的;相反,它们被画成一系列的扫描线,从左到右,从上到下。这种串行表示允许应用程序在显示帧时,可以更改帧,从而会导致输出出现故障。双缓冲可以解决这个问题,一个缓冲区用来组成帧,而第二个缓冲区用来显示。两个缓冲器在帧之间进行切换,并与帧间间隔同步。实现双缓冲的方法依赖于系统,但是,通常是视频显示 API 的一部分。
总结
本章描述了 RTP 发送者和接收者的基本行为,重点介绍了接收者的播放缓冲区的设计。对于,可以接受几百毫秒(甚至几秒)延迟的流式应用程序,播放缓冲区的设计会相对简单。然而,对于为交互使用而设计的应用程序,播放缓冲区对于获得良好的性能至关重要。这些应用程序需要较低的延迟,因此,缓冲区的延迟只有几十毫秒,这就增加了算法设计的工作量,因为算法必须平衡低延迟的需要和避免丢弃延迟的包(如果可能的话)。
RTP 系统在终端系统中设置了很多的技巧(intelligence)使得它们能够弥补在最佳的分组网络中具备固有的可变性。认识到这一点,是获得良好性能的关键:一个设计良好、健壮的实现,可以比一个简单的设计执行的要好得多。
第七章 音视频同步(Lip Synchronization)
- 发送端行为
- 接收端行为
- 同步精度
通常多媒体会话中包含多路RTP流,每路媒体流都通过独立的 RTP 会话传输。不同编码格式之间的延迟差别非常大,而且不同的流在网络中是分开来传输的,所以不同媒体类型往往会有不同的到达时间。为了让多路媒体流同步渲染,接收端必须如图 7.1 中展示的那样对齐媒体流。本章讨论 RTP 实现多路媒体流的同步所需要的信息是如何生成的。虽然这个技术的主要应用就是对齐音频和视频来达到音视频同步(Lip Synchronization),但是本章描述的技术可以来同步任意组合的媒体流。
一个常见的问题是为什么媒体流要分开传输,导致接收方需要重新进行同步,而不是将它们捆绑在一起并进行预先同步。这个问题的答案包括:
- 分别处理音频和视频是真实存在的需求
- 异构型网络(
the heterogeneity of networks) - 编码和应用的需求
根据发送端或接收端的选择,对音频和视频进行合理范围内的传输优先级选择。例如,在视频会议中,与会者通常更青睐音频而不是视频,在尽力而为网络中通常表现为对不同流进行纠错处理。在集成服务网络中,使用 RSVP(资源保留协议),这可能意味着音频和视频具有不同的服务质量(QoS)预留保证;在差异化服务网络中,可以将音频和视频分配不同的优先级。如果将不同的媒体类型捆绑在一起,这些选项将不复存在或变得难以实现。同样,如果使用捆绑传输,所有接收端都必须接收所有媒体。有些参与者将无法只接收音频,而其他参与者同时接收音频和视频。对于多方会话,尤其是使用多播分发的会话,这个问题变得更加复杂。
然而,即使所有媒体都采用相同的 QoS,且所有接收端都希望接收所有媒体,**由于编解码器和播放算法的特性,**通常也需要特定类型的同步处理。例如,音/视频解码器花在解码,纠错,渲染的时间都不相同并且差距很大。正如我们在第六章中所述,适应播放缓冲延迟的方式也随媒体格式而变化。这些过程中的每一步都会影响播放时间,并可能导致音频和视频之间的同步丢失。
结论就是,就算把媒体捆绑在一起进行传输,也需要特定类型的同步功能。所以,我们最好还是单独分发媒体,允许在网络中使用不同的方式处理它们,这样做也不会给接收端增加复杂度(至少纸面上的)。
带着这些问题,我们转向讨论同步流程。流程分为两步:发送端需要为这些流分配一个公共参考时钟,而接收端需要重新同步媒体,消除网络引起的时间干扰。我们先依次讨论发送端和接收端,然后是一些常见应用所需的同步精度的讨论。
发送端处理
发送端通过 RTCP 定时发布NTP时刻和媒体流时刻之间的映射关系以及要同步的流的标识,来使接收端处的媒体流同步。参考时钟以固定速率增长;参考时钟和媒体流之间的映射帮接收端计算出媒体流之间的相对时间关系。 图 7-2 中展示了此过程。
参考时钟和媒体时钟之间的映射关系,生成每个 RTCP 数据包时记录下来:参考时钟的采样 Treference 与计算出的 RTP 时间戳 TRTP = Treference x Raudio + Oaudio一起包含在数据包中。必须对乘积取模,将结果限制在 32bitRTP 时间戳的范围内。偏移量的计算方式为 Taudio = Taudio –(Tavailable – Taudio_capture)x Taudio,即媒体和参考时间轴之间的转换因子。操作系统延迟可能会拖后 Tavailable并导致偏移量发生变化,应由应用进行过滤来选择最小值。
发送端每个 RTP 流的都需要访问公共参考时钟 Treference,并且必须参考规范的源标识符(canonical source identifier )来标识其媒体。发送应用应注意媒体采集延迟(例如 T~audio_capture~),因为它可能很重要,并且在计算和发布参考时钟时间与媒体时钟时间之间的关系时,应该把他考虑进去。
NTP时刻是 RTCP 使用的“挂钟”时间。它用 NTP 格式的时间戳的形式,计算自 1900 年 1 月 1 日午夜 UTC(Coordinated Universal Time )以来的秒数以及小数部分(不知道"挂钟"时间的发送端可能用系统指定的时间时钟,例如“系统正常运行时间”来计算 NTP 格式的时间戳;参考时钟的选择不会影响同步,只要对所有媒体都保持一致即可。)发送端会定期在每个流的媒体时钟以及公共参考时钟之间建立对应关系;它通过 RTCP 发送端报告包(第五章《RTCP 控制协议》中标题为 RTCP SR:Sender Reports 的部分)传递给接收端。
典型场景下,不需要将发送端或接收端的时间同步到外部时钟。有些有时候,即使 RTCP SR包中的挂钟时间使用 NTP 时间戳的格式,也没有同步到 NTP 时间源的必要。发送器和接收端时钟不必相互同步。接收端不关心 RTCP 发送端报告数据包中 NTP 格式时间戳的绝对值,只需要媒体之间的时钟是公共的,且其准确性和稳定性足以保证同步。
同步时钟只有在同步不同主机生成的流时使用。一个例子,多个摄像机在一个屏幕上提供了多个视角,独立连接到独立的主机。在这种情况下,发送主机需要使用时间协议或其他特定方式来将其参考时钟与通用时基对齐。 RTP 并没有强制指定定义该时间的任何方法,但是根据所需的同步程度,网络时间协议(Network Time Protocol) 可能是合适的。 图 7.3 展示了在播放时要同步来自不同主机的媒体流时时钟同步的要求。
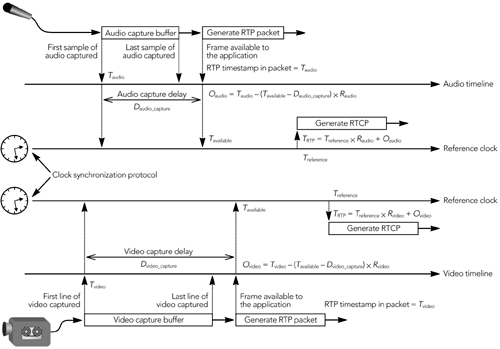
同步的另一个要求是标识要同步的源。 RTP 通过为相关源指定一个共享名称来做到这一点,因此接收端知道它应该尝试同步的流,哪些流是独立的。每个 RTP 数据包都包含一个同步源(SSRC)标识符,以将该源与媒体时基相关联。 SSRC 标识符是随机选择的,并且对于要同步的所有媒体流而言,SSRC 标识符都不相同(如果标识符冲突,会话也会在会话期间更改,如第四章,RTP 数据传输协议中所述)。 RTCP 源描述(SDES)数据包提供了从 SSRC 标识符到永久规范名称(CNAME)的映射。发送端应确保要在播放时同步的 RTP 会话具有通用的 CNAME,以便接收端知道对齐媒体。
规范名称是根据源主机的用户名和网络地址通过算法得出的(请参见第五章中的 RTCP SDES:源描述,RTP 控制协议)。如果单个主机生成多路媒体流,确保它们具有公共 CNAME,那么同步的任务就很简单。如果目的是同步多个主机生成的媒体流(例如,一个主机正在采集和传输音频,而另一台主机正在传输视频), CNAME 的算法就有多种选择了,因为 RTP 标准中的默认方法要求每个主机都使用 IP 地址作为其 CNAME 的一部分。解决方案是让主机私下协商为所有要同步的流选择一个公共 CNAME,即使这意味着某些主机使用的 CNAME 与它们的网络地址不匹配。 RTP 并未指定协商的机制:
- 一种解决方案可能是在构造 CNAME 时使用主机的最低编号的 IP 地址。
- 另一个可能是音频使用视频主机的 CNAME(反之亦然)。
协商通常将由 RTP 之外的会话控制协议(例如 SIP 或 H.323)提供。会话控制协议也可以指示哪些流应通过不依赖 CNAME 的方法进行同步。
接收端行为
我们期望接收端根据 RTCP 数据包中传递给它的信息,确定哪些媒体流应该同步,并对齐渲染。
这个过程的第一部分(确定要同步的流)很简单。接收端同步发送端的 RTCP source description packets 中 CNAME 相同的那些流,如上一节所述。由于 RTCP 数据包每隔几秒钟发送一次,因此在接收到第一个数据包和接收到 RTCP 数据包之间可能会有一个延迟,RTCP 包表明指定的流将被同步。接收端可以在这段时间内播放媒体数据,但是由于没有必要的同步信息,因此无法同步它们。
实际的同步操作更为复杂,接收端将音频和视频对齐来展示。这个操作由接收 RTCP 发送端报告数据包触发,数据包包含媒体时钟和两个媒体共有的参考时钟之间的映射。一旦为音频和视频流都确定了这个映射关系,接收端就拥有了同步播放所需的信息。
音视频同步(Lip Synchronization)的第一步是为每个要同步的流确定:什么时候把特定参考时间相对应的媒体数据呈现给用户。由于网络影响或其他原因带来的差异,要是按第六章所讲的方法来独立地确定播放时间,则可能无法将在同一时刻采集的两路流同时播放**。因此,必须调整一个流的播出时间来匹配另一个流。**这个调整会带来一个偏移量,该偏移量将添加到一个流的播放缓冲延迟中,以便按时间对齐播放媒体。 图 7.4 和 7.5 解释了这个过程。
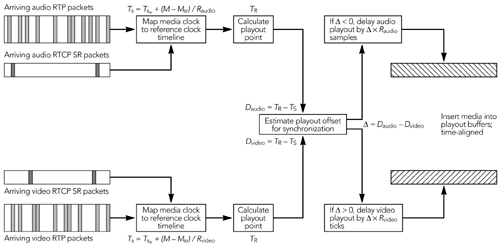

接收端首先检测每一路需要同步的流的媒体时钟和参考时钟之前的映射关系。这个映射关系在发送端报告包(SR)中定时的传递给接收端,因为可以从负载类型知道媒体时钟的标称速率(nominal rate),所以一旦接收到源的 RTCP 发送端报告(SR),接收端就能计算出任何包的参考时钟采集时间。收到带有媒体时间戳 M 的 RTP 数据包后,可以用下面公式计算相应的参考时钟采集时间(映射到参考时间轴的 RTP 时间戳):
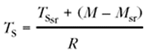
其中 Msr是最后一个 RTCP 发送端报告数据包中的媒体(RTP)时间戳,Tsr是距发送端报告数据包的相应参考时钟(NTP)时间戳以秒为单位(和秒的小数部分),R 是标称媒体时间戳时钟频率单位是 Hz(需要注意的是,如果在 Msr 和 M 之间经过了超过 32 个单位的媒体时钟,那么公式无效,但是通常情况下,不会发生这种情况。)
接收端还根据其本地参考时钟计算任意数据包的渲染时间 TR。 这等于数据包的 RTP 时间戳,如前所述,映射到接收端的参考时钟时间轴,加上播放缓冲延迟(以秒为单位)以及由于解码、混流和渲染过程引起的任何延迟。 重要的是,要综合考虑各个的方面延迟,直到要在显示器或扬声器上实际渲染为止,如果要实现精确的同步。 特别是,如果解码和渲染所花费的时间通常很长,应该按照第 6 章《媒体捕获,播放和定时》中所述考虑。
一旦根据NTP时间线线知道采集时间和播放时间,接收端可以估算出每路流的采集时间和播放时间之间的延迟关系。如果根据发送端参考时钟样本采集时间是 TS,根据接收端参考时钟展示时间是 TS,则它们之间的差值 D = TR – TS,就是采集到播放的延迟(以秒为单位)。由于发送端和接收端的参考时钟不同步,因此这个延迟包括一个未知的偏移量,但是可以忽略不计,因为它在所有流中都是通用的,我们也仅对流之间的相对延迟感兴趣。
一旦估算出了音频和视频的采集到播放的相对延迟,就可以得出同步延迟 D = Daudio – Dvideo。如果同步延迟 D 为零,则流同步完成。非零值表示一路流比另一路流先播放,同步延迟表示相对偏移量(以秒为单位)。
对于前面的媒体流,将同步延迟(以秒为单位)乘以标称媒体时钟速率 R,以将其转换为媒体时间戳单位,然后将其作为常数偏移量应用于该媒体流的播出计算,延迟播放以匹配其他流。 结果是,一个流的数据包在接收端的播放缓冲区中驻留的时间更长,以补偿系统其他部分的更快处理或减少的网络延迟,并与另一流的数据包同时呈现。
接收端可以选择调整音频或视频的播放时间,具体的这取决于媒体流的优先级和相对延迟以及由于对每路流进行调整而导致的相对播放错乱。对于许多常见的编解码器,视频编码和解码时间是主要考量因素,但是音频对播出调整更加敏感。在这种情况下,可能需要进行适当的初始调整,方法是延迟音频以匹配附近的视频展示时间,然后对视频播放点进行细微调整。在其他情况下,相对优先级和延迟可能会有所不同,具体取决于编解码器,采集和播出设备,并且每个应用都应根据其特定的环境和延迟预算做出选择。
任何一路流的播出延迟调整了,都需要重新计算同步延迟,因为播出延迟的任何变化都会影响两路流的相对延迟。每当接收到媒体时间和参考时间之间的新映射(以 RTCP 发送端报告包(SR)的形式)时,也需要重新计算偏移量。健壮的接收端可能不会信任发送端,来将抖动排除在 RTCP 发送器报告数据包(SR)中提供的映射之外,并且它将过滤映射序列来消除任何抖动。适度的过滤器可能会跟踪媒体时间和参考时间之间的最小偏移,避免普遍的一个实现问题:发送端使用映射中前一个数据包的媒体时间,而不是生成发送端报告包的实际时间。
映射偏移量的变化会导致播放点的变化,并且可能需要从流中插入或删除媒体数据。与对播放点进行任何更改一样,应谨慎选择这类更改的时间,以降低对媒体质量的影响。在第 6 章《调整播放点、媒体捕获、播放和时序》一节中讨论的问题与此处相关。
同步精度
在实现同步时,会出现精度问题:应该同步的流之间可接受的偏移量是多少?遗憾的是,这个问题不是一句话能解答的,因为人类对同步的感知,取决于同步的内容和具体的操作。例如,音频和视频之间的音视频同步(Lip Synchronization)的要求相对宽松,并且随视频质量和帧率而变化,多个关联的音频流的同步的要求严格。
如果目标是将单个音频轨道同步到单个视频轨道,则通常精确到几十毫秒的同步就足够了。通过视频会议进行的实验表明,大约 80 毫秒到 100 毫秒的同步误差低于人类的感知极限(例如,参见 Kouvelas 等,1996,84),尽管这个结论显然明显的基于具体的操作、图像质量和帧率。更高质量的画面以及更高帧率的视频,使得同步缺失更加明显,因为它更容易看到唇部活动。同样,如果帧速率很低(每秒大约少于五帧),则几乎不需要嘴唇同步,因为虽然其他视觉提示可能会暴露出缺乏同步,但是无法将嘴唇运动感知为语音。
如果应用同步多个音轨(例如,环绕声演示中的声道),则同步的要求会更加严格。在这种情况下,播放必须对单个样本准确;由于信号之间的相位差,最小的同步误差将很明显,这会破坏信号源的视在位置。
如果有必要,RTP 提供的信息足以进行精确的同步,前提是发送端已经正确计算出 RTCP 发送端报告(SR)数据包中包含的媒体时间和参考时间之间的映射,并且接收端具有适合的同步算法。在实践中这是否可以达到是实现质量的问题。
总结
像 RTP 的许多其他功能一样,同步是最由应用执行,必须尽力校正来应对分组网络中固有的可变性。本章描述了发送端如何用信号通知媒体的时间对齐,以及接收端可以重新同步媒体流的过程。本章还讨论了音频和视频之间的音视频同步(Lip Synchronization)以及多个音频流之间的同步所需的同步精度。
第八章 错误隐藏
- 音频丢包隐藏技术
- 视频丢包隐藏技术
- 交织
前几章描述了运行在 UDP/IP 上的 RTP 如何提供不可靠的数据包传输服务,以及这意味着应用可能必须要处理不完整的媒体流。当发生丢包时应用有两件事可以做:尝试恢复错误或尝试隐藏错误。错误恢复将在第 9 章讨论。本章我们将讨论接收端隐藏丢包影响的技术。
音频丢包隐藏技术
当包含音频数据(无论是音乐还是语音)的 RTP 数据包丢失时,接收端必须生成替换内容以保留媒体流的时序。这可以通过多种方式完成,在丢包的情况下,隐藏算法的选择会极大的影响对系统质量的感知。
测量音频质量
人类对声音的感知是一个复杂的过程,失真感知是否明显不仅取决于信号发生变化,还取决于损伤的类型,以及损伤在信号中的位置。有些类型的失真对听者比其他类型的失真更容易被察觉,即使通过某种客观的衡量,人们也没法发现这种区别。对于不同的听者,特定的音频损失的感知也是不一样的,并且对不同的音频材料的感知也不一样。
这使得很难为不同的修复方案设计客观的质量评测。由于感知到的质量与波形差异没有直接关系,因此测量原始波形与接收端恢复的波形之间的差异是不够的。简单的方法如信噪比实际上也是无用的 。更复杂的方案(例如,国际电联建议 P.861 和 P.862 63,64) 提供的结果大致上是正确的,但即使是这样也不是 100%可靠的
当客观测量失败时,我们需要借助于主观测试。通过对各种各样的主题、材料和错误情况做听力测试,我们可以从对听众对音频损失的感知度 ,衡量不同修复方案的有效性。这些测试里播放不同类型的音乐,或收听不同错误条件和隐藏技术的下,一系列单词、短语和句子,并且听众根据特定的等级对它们的质量和或清晰度进行评估。
材料和评定尺度的选择取决于所测量的内容。如果你尝试测量语音的感知质量(“听起来不错吗?”),则基于平均意见得分(MOS)对样本进行评级是合适的。 MOS 是五分制的评分标准,其结果转换成数字形式(优异= 5,良好= 4,一般= 3,不良= 2,差= 1),并且取所有参与者的平均,给出一个介于 1 和 5 之间的数字作为结果。为使结果在统计上有效,需要进行大量的测试,比较不同的样本。
对于 G.711 编解码器(即标准电话质量),无障碍语音的典型 MOS 得分为 4.2,而对于移动电话(例如 GSM,QCELP),得分为 3.5 至 4。丢包会降低MOS得分,丢包程度和隐藏类型决定实际结果 。
MOS 评分提供了一种合理的感知质量测量,允许在不同的编解码器和修复技术之间进行比较,但它们并不测量可理解性(即音频是否可以理解)。听起来好和传达信息是有区别的;可以定义一种隐藏方案,它能获得很好的音质分数,但这个方案可能无法产生可理解的语音。在可理解性测试中,收听者抄下不同缺陷的句子或单词,或在一段课文上回答问题,结果是测量出现了多少错误。同样,必须进行大量的测试才能使统计的结果有意义。
或许从听力测试中学到的最重要的一点是,测试结果因听者、材料、失真类型以及测试内容而异。具体情况下,保证测试材料,丢包类型以及恢复方式相匹配,对知质量和可懂度两方面的测试很重要。
静音替换
最简单的修复技术是静音替换,在这种技术中,数据包丢失所造成的空白被适当时间范围内持续的的静音填充,如图 8.1 所示。这是成本最低,最容易实现的方法,也是最常用的技术之一。
图 8.1 使用静音替换进行修复(改编自 C. Perkins,O.Hodson 和 V. Hardman,“流媒体的丢包恢复技术概述”,IEEE 网络杂志,1998 年 9 月/十月。1998IEEE。)
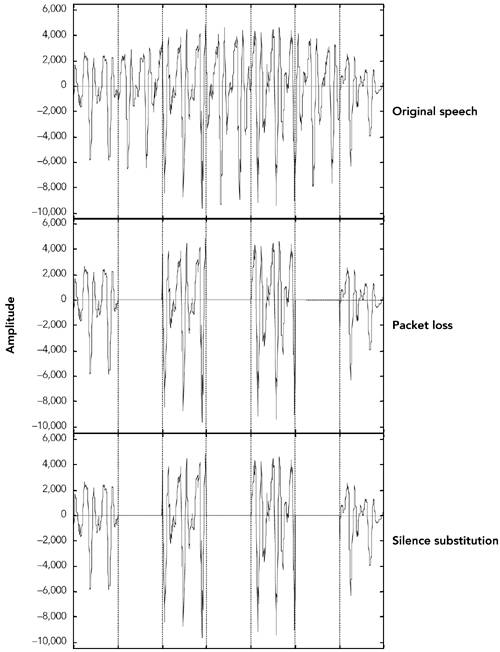
不幸的是,静音替换也是最糟糕的修复方案,在用于评估修复质量的听力测试中一直被评为最后一个。H听力实验表明,只有短时间的数据包( < 16毫秒)和较低的丢包率( < 2 % ),静音替换才有效。随着分组大小和丢包率的增加,性能迅速下降。语音IP应用, 随着分组变大和网络丢包率的变化,性能迅速变得不可用
接下来介绍的任何一种技术都可以提供质量更高的声音,只要稍微增加一点点复杂性。
噪声替换
由于已证明静音替代的性能较差,因此下一个选择是用某种类型的背景噪声填充丢失的数据包所留下的间隙,这一过程被称为噪声替换。如图 8.2 所示。
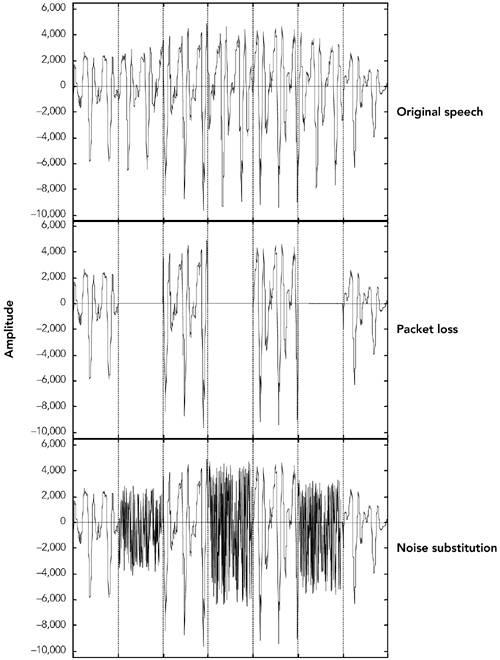
简单地说,噪声替换就是用与前一个包波形匹配的白噪声(在所有频率上波形一致的噪声)代替丢失的信号。下面是它的伪代码实现。
void substitute_noise(sample previous_frame[samples_per_frame],
sample missing_frame[samples_per_frame)
{
double energy;
// Calculate energy (amplitude) of the previous frame
energy = 0.0;
for(j = 0; j < samples_per_frame; j++) {
energy += previous_frame[j] * previous_frame[j];
}
energy = sqrt(energy);
// Fill in the noise
for(j = 0; j < samples_per_frame; j++) {
missing_frame[j] = energy * random(-1,1);
}
请注意,真正的实现将很可能用接收到的最后几帧的旋转缓冲区来替换,在播放后丢弃旧的帧 。
语音听力测试表明,与静音替代相比,使用与信号幅度大致相同的白噪声替代,在主观上提供了更好的质量,和更好的清晰度。这在质量上的改善有一个基础:研究表明,语音的恢复,即人类大脑潜意识地有用正确的声音修复缺失的语音片段的能力,噪音修复语音时,但是静音来修复不会存在这种情形。由于白噪声几乎和静音一样容易产生,所以建议用它代替静音替换。
如果信号的频谱特性已知,就可以对产生的噪声进行调整,使其比白噪声更接近原始噪声。许多有效负载格式通过提供舒适的噪声包来简化这项工作,这些数据包将在静默期间发送。对舒适噪音的支持允许接收端在没有其他声音的情况下播放适当形式的背景噪声,这样看起来更自然。
对于不支持舒适噪声有效负载格式的,有一种标准的舒适噪声有效负载格式可用于传输此信息(默认音频/视频 profile 中的静态有效负载类型为 13)。这种舒适的噪声格式传达了两个信息:噪声的幅度和频谱参数。波形允许接收端产生幅度匹配的噪声;频谱参数使噪声的波形能够与周围的信号相匹配。
重复
根据音频信号的内容,可以提供一个类似于丢失包的替换包。这尤其适用于语音信号,这些语音信号遍布着重复的模式,称为音调周期,通常持续 20 毫秒到 100 毫秒。
图 8.3 展示出了典型的语音信号,虽然可以识别出许多特征,但主要是有声和无声的区别。声音由声带的周期性打开和闭合产生的,声带产生规则的、高振幅的音调周期,频率在 50Hz 到 400Hz 的近似范围内。有声部分通常持续几十甚至几百毫秒,所以允许用前面的数据包代替一个丢失的语音包,从而高效地修复语音丢包的问题。图 8.4 将反映这种现象。图中展示了通过重复包修复丢失包后除了修复区域的边缘是尖锐不连续以外,其余部分和最开始的状态几乎一样。

图 8.4 通过重复包修复语音
由 s、f、sh 等音组成的无声语音是由空气通过声带的压缩而产生的,它与低振幅噪声非常相似。同样,用前一个数据包的内容替换一段丢失的无声语音,可以产生相当好的修复效果。
当间隙很小时,重复效果最好,因为在间隙小时信号的特征很可能是相似的。通过逐渐减弱重复信号,可以提高具有较长时间间隙的表现。例如,GSM 移动电话系统建议对第一个丢失的数据包执行相同的重复,然后在接下来的 16 个分组 (320 毫秒总持续时间)内逐渐衰减到零振幅,或者直到接收到下一个包为止。
重复算法可以用伪代码来描述,如下所示:
void repeat_and_fade_frame(sample previous_frame[samples_per_frame], sample missing_frame[samples_per_frame],
int consecutive_lost)
{
// Repeat previous frame
for (j = 0; j < samples_per_frame; j++) {
missing_frame[j] = previous_frame[j];
}
// Fade, if we've lost multiple consecutive frames
if (consecutive_frames_lost > 0) {
fade_per_sample = 1 / (samples_per_frame * fade_duration_in_frames);
scale_factor = 1.0 – (consecutive_frames_lost * samples_per_frame * fade_per_sample);
if (scale_factor <= 0.0) {
// In case consecutive_frames_lost >
// fade_duration_in_frames
scale_factor = fade_per_sample = 0.0;
}
for (j = 0; j < samples_per_frame; j++) {
missing_frame[j] *= scale_factor
scale_factor -= fade_per_sample
}
}
}
请注意 previous_frame[] 数组表示前面收到的帧,而不是先前修复的帧。播放缓冲区应该基于 RTP 的序列号维护 consecutive_lost 变量,并且应该跟踪原始帧和修复帧(万一其中一个原始帧只是延迟了)。
听力测试表明,对语音来说重复比噪声替换效果更好,而且实现简单。重复对语音的作用比对音乐的效果好,是因为音乐的特点更加多样。与信号频谱相匹配的噪声可能是音乐信号更好的选择。
修复语音信号的其他技术
三种简单的修复技术—静音替换、噪声替换和重复—构成了众多错误隐藏系统的基础,并且当正确应用时,它们可以以较低的实现复杂度获得良好的性能。研究人员还研究了一系列更专业的语音错误隐藏技术。这些技术通常用增加实现复杂性来换取性能的适度改进,而且它们常常针对特定类型的输入进行调整。
基于波形替换的各种技术已经用于语音。这些技术根据丢失包附近语音信号的特征生成合适的替换包,它们可以看作是重复的扩展。与基础的重复不同,波形替换算法对修复进行了调整,以避免间隙边缘的不连续,并更好地匹配信号的特性。
以波形替换为例, Wasem 在 Goodman 早期工作的基础上提出的算法,该算法首先将语音分为有声和无声(例如,通过检测由有声周期引起的周期尖峰)。如果附近丢失包的语音是无声的,包重复被用来填补空白。如果周围语音是有声的,则使用模式匹配修复算法寻找要重复的区域。
模式匹配修复算法使用间隙之前的最后几毫秒作为模板。然后使用滑动窗口算法将模板与包的其余部分进行比较,指出最佳匹配的位置。模板和它的最佳匹配之间的区域形成一个完整的音调循环,重复以填补空白。由于模板与原始信号非常匹配,因此在修复开始时,没有明显的不连续。算法伪代码可以这样写
void pattern_match_repair(sample previous_frame[samples_per_frame],
sample missing_frame[samples_per_frame],
int consecutive_frames_lost)
{
// Find best match for the window of the last few samples
// in the packet
window_start = samples_per_frame - window_length;
target = infinity;
for(i = 0; i < window_start; i ++) {
score = 0;
for(j = i, k = 0; k < window_length; j++, k++) {
score += previous_frame[j] -
previous_frame[window_start + k];
}
if (score < target) {
target = score;
best_match = i; // The start of the best match for the
// window
}
}
pattern = best_match + window_length;
pattern_length = samples_per_frame – pattern;
// "pattern" now points to the start of the region to repeat.
// Copy the region into the missing packet
dest = 0;
for (remain = samples_per_frame; remain > 0;
remain -= pattern_length) {
for (j = 0; j < min(remain, pattern_length); j++) {
missing_frame[dest++] = previous_frame[pattern + j];
}
}
// Fade, if we've lost multiple consecutive frames
if (consecutive_frames_lost > 0) {
fade_buffer(missing_frame, consecutive_frames_lost);
}
}
修复结束时仍有边界不连续。我们可以通过合并修复数据和原始数据来修复这个问题,前提是这两个数据是重叠的。如图 8.5 所示,两个波形的加权平均值用于重叠区域,这可以提供平滑的过渡。加权意味着在重叠区域的开始取更多的第一个波形,在重叠区域的结束取更多的第二个波形。
图 8.5 包在修复边界处合并
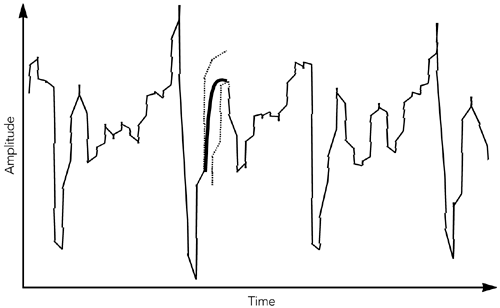
测试结果表明,该算法是一种非常有效的语音修复算法,其性能明显优于重复。通过波形替换修复的语音波形如图 8.6 所示。
图 8.6 使用波形替换进行修复

研究人员提出了一系列看似无穷无尽的错误隐藏技术,与这里讨论的技术相比,这些技术提供了渐进式的改进。这些技术包括以下内容:
-
时间尺度修正 : 将丢失包两侧的音频延伸到整个间隙。例如,Sanneck 等人已经提出了一种方案,其中延长音调周期以覆盖任一侧的损失,并在它们相遇的地方平均。
-
再生修复 :利用音频压缩算法的知识,推导出适当的解码器参数,以恢复丢失的包。
-
编码器状态的插值: 它允许基于线性预测(例如,G.723.1)的编解码器通过在丢失包的任一侧插值帧来导出预测器参数。
-
基于模型的修复: 尝试将丢失包两侧的信号拟合到声道/编解码器模型,并使用该模型预测正确的填充。
单独处理语音的应用可能需要考虑这些更复杂的修复方案。但是要注意,收益是随着复杂性的增加递增的。(见图 8.7 关于质量和复杂性的粗略图表)
图 8.7 语音信号的错误隐藏粗略质量/复杂性权衡 (来自 C. Perkins, O. Hodson 和 V. Hardman,“流媒体中包丢失恢复技术的调查”,IEEE 网络杂志,9 月/ 1998 年 10 月。IEEE©1998。)

视频丢包隐藏技术
大多数视频编解码器使用帧间压缩,间歇性发送完整帧和大量中间帧(作为对已更改或移动的帧部分的更新),如图 8.8 所示这种技术称为预测编码,因为每个帧都是在前一帧的基础上进行预测的,这种技术对于良好的压缩至关重要。
图 8.8 视频编解码器的基本操作
预测编码对于丢包隐藏具有多个后果。首先是中间帧的丢失可能只影响帧的一部分,而不是整个帧(当将帧拆分为多个数据包(其中一些丢失)时,会发生类似的影响)。因此,隐藏算法必须能够修复图像的受损区域,并替换整个丢失的图像。这样做的常见方法是通过复制运动补偿。
预测编码的另一个结果是帧不再独立。这意味着一帧中的数据丢失可能会影响将来的帧,从而使丢包隐藏更加困难。该问题将在本章后面的“减少依赖项”一节中讨论,并给出可能的解决方案。
复制运动补偿
视频丢包隐藏中广泛使用的技术之一是时域上的重复。当丢包发生时,受丢包影响的部分被替换为前一帧的重复。由于大多数视频编解码器都是基于块的,而且丢失的数据通常只构成图像的一小部分,所以这种类型的修复通常是可以接受的。
当然,仅当图像相对恒定时,复制才有效。如果帧之间有明显的运动,则重复先前帧的一部分将产生明显的视觉伪像。如果可能的话,希望在隐藏丢包的影响时检测运动并尝试对其进行补偿。在许多情况下,这比想象的要容易,因为常见的视频编解码器允许发送端使用运动矢量来描述图像中的变化,而不是发送已移动块的新副本。
如果仅仅是图像中的单个块丢失了,接收端可以使用与周围块相关联的运动矢量来根据前面的包推断丢失块的正确位置。例如,图 8.9 显示了如何推断图像中单个缺失块的运动。如果高亮显示的块丢失,则可以导出原位置,因为运动可能与周围块相同。
图 8.9 丢失视频块的运动补偿复制
运动补偿的复制适合仅影响图像一部分的丢包。这使其非常适合图像中单个位破坏的网络传输,但不太适合通过 IP 网络传输的丢失了包含多个(很可能是相邻的)块的数据包。本章稍后讨论的交织是解决该问题的一种方法。另一种方法是使用前一帧中的运动矢量来推断当前帧中的运动,如图 8.10 所示。这里的假设是,运动在整个帧中是平滑且连续的,这种假设在许多环境中并非不合理。
图 8.10 跨帧运动推断

这两种方案可以协同工作,从当前帧中的其他块或前一帧中的块推断丢失的数据。
建议实现方式上至少在丢包的情况下重复上一帧的内容。另外,还值得研究编解码器操作以确定是否可以进行运动补偿,尽管这样做的好处较小,并且可能通过编解码器的设计预先确定。
修复视频丢包的其他技术
除了重复之外,还可以使用其他两种修复:空间域的修复和频域的修复。
空间域的修复依赖于在周围数据的基础上对缺失块进行插值。研究表明,人类对视频的感知对图像的高频分量-细节-相对不敏感。因此,接收端可以产生一个近似正确的填充,只要这是一个短暂的,它不会对视觉产生太大的干扰。例如,可以计算每个周围块的平均像素颜色,并且可以将缺少的块设置为这些颜色的平均值。
类似的技术可以应用于频域,特别是基于离散余弦变换 (DCT) 的编解码器,如 MPEG、H.261 和 H.263。在这种情况下,可以对周围块的低阶 DCT 系数求平均值,以生成缺失块的填充。
如果错误率很高,简单的空间和时间修复技术将导致较差的结果,并且通常在丢包方面效果不佳。它们在产生误码的网络上效果较好,因为这种情况只是破坏单个块而不是丢失包含多个块的整个数据包。有各种更先进的时空修复技术— Wang 等人的调查提供一个很好的概述,但是同样,这些通常不适合分组网络。
减少依赖
虽然预测编码是实现良好压缩的关键,但它使视频对丢包敏感,增加了错误隐藏的复杂性。另一方面,如果视频的每一帧都是独立编码的,丢失的包只会影响一帧。结果将是一个暂时的小故障,但是当下一帧到来时,它将很快得到纠正。独立编码帧的代价是更高的码率。
当使用预测编码时,如果帧不是独立的,单个数据包的丢失会传播到多个帧,导致视频流的性能显著下降。例如,一个帧的一部分丢失了,必须从前面的帧中推断出来,从而产生一种不精确的修复。当下一帧到达时,它包含一个运动矢量,该运动矢量指的是图像被修复的部分。结果是,不正确的数据仍然在图像中跨多个帧,根据运动矢量移动。
以这种方式的错误传播是一个重要的问题,因为它会使任何丢包的影响倍增,并产生视觉干扰。不幸的是,接收端几乎无法纠正这个问题,因为在完整的帧更新到来之前,它没有足够的数据来修复损失。如果丢包超过一个特定的阈值,那么接收端可能会发现,放弃从丢包的数据中预测的帧而显示静止的画面,比使用错误的状态作为基础并显示损坏的图片效果更好。
当出现丢包时,发送端可以通过使用较少的预测编码来缓解这一问题,尽管这样做可能会降低压缩效率并导致码率的增加(有关讨论,请参见第 10 章,拥塞控制)。如果可能的话,发送端应该监控 RTCP 接收端报告的反馈,并随着丢包率的增加而减少预测量。这虽然并不能解决问题,但意味着更频繁地发生完整的帧更新,从而允许接收端与媒体流重新同步。为了避免超过可用带宽,可能需要降低帧率。
压缩效率和丢包容忍度之间存在根本的权衡。发送端必须意识到,使用预测编码将数据压缩到非常低的码率并不能有效防止丢包。
交织
在本章的开头,指出错误隐藏是由接收端完成的,不需要发送端的帮助。通常情况下是这样的,但是有时候发送端可以减轻错误隐藏的任务,而不必发送额外的信息。视频就是一个这样的例子,发送端可以减少帧间的依赖来减轻接收端的工作。一种更通用的技术是交织,只要不需要低延迟,它可以与音频流和视频流一起使用。
交织过程在传输之前对数据进行重新排序,以便在传输期间将原来相邻的数据按保证的距离分开。交织是有用的,因为它使传输流中连续爆发丢包在恢复原始顺序时看起来是孤立的丢包。例如,在图 8.11 中,当重建原始顺序时,交织流中四个连续丢失的包被转换成四个单包的丢失。实际的丢包率是不变的,但是对于接收端来说,隐藏一系列的单包丢包要比隐藏长时间的丢包容易得多。
图 8.11 交织,将突发损失转化为孤立损失(来自 C. Perkins, O. Hodson 和 V. Hardman 的“调查 流媒体的包丢失恢复技术,"IEEE 网络杂志,1998 年 9 / 10 月。©1998 IEEE)
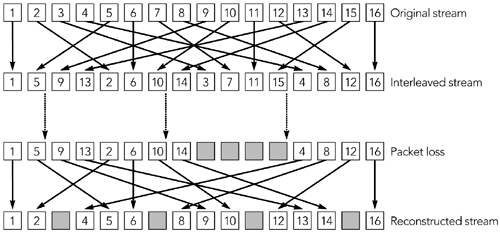
交织函数最简单的实现是使用一对矩阵,如图 8.12 所示。媒体数据的帧按行读入第一个矩阵,直到该矩阵满为止。此时,两个矩阵交换,第一个矩阵中的数据由列读出,第二个矩阵中的数据由行填充。这个过程持续运行,帧读取到一个矩阵的同时从另一个矩阵中读出。
图 8.12 交织矩阵
发送端和接收端都必须将缓冲区矩阵维护为适当大小的数组。发送端按列获取输出并将其插入到包中进行传输。接收端从传输流中获取数据包,并将它们按行传递到矩阵缓冲区中,当它们按列读取时,恢复原始顺序。
交织可以在 RTP 包级别进行,但更常见的情况是在每个包中交织多个帧。当在 RTP 包级别上进行交织时,编解码器数据通常被打包到 RTP 包中。对完整的包进行交织操作,导致一系列包具有非连续的 RTP 时间戳。RTP 序列号应该在交织之后生成,从而使发送的数据包具有连续序列号。
当对每个包中的多个帧进行插入时,RTP 时间戳和序列号与非交织格式保持不变。将多个编解码帧放入每个 RTP 包中,以便交织器的每一列形成一个 RTP 包,使这些值保持不变。
应该选择交织函数,以便原始流中的相邻包之间的间隔大于传输流中最大的连续丢包长度。具有 n 行 m 列的矩阵将产生由 n 个其他元素分隔的原始相邻符号的输出。换句话说,当每个矩阵的传输过程中丢失 m 个或更少的数据包时,在解交织后,每组 n 个数据包最多会有一个丢失。
传输过程必须传递交织分组的大小——矩阵的大小——以及分组中每个包的位置。交织组的大小可以是固定的并在带外通信,也可以包含在每个包中,从而允许交织功能发生变化。如果交织分组大小可以改变,那么分组中每个包的位置必须包含在分组中,或者如果交织组大小固定可以从 RTP 序列中推断出包的位置 。
交织使用的一个很好的例子是 MPEG Audio Layer-3 (MP3) 的容错有效负载格式,它是针对原始有效负载格式对丢包缺乏弹性而开发的。其他交织的例子可以在 AMR(自适应码率)和 AMR- wb(自适应多速率宽带)音频的有效负载格式中找到。交织没有单一的标准;每个有效负载格式必须单独实现它。
交错会给传输过程增加相当大的延迟。发送端和接收端的交织组中的相同数量的包将被缓冲。例如,如果使用 5 x 3 矩阵实现,除了网络延迟外,发送端将缓冲 15 个包,接收端将缓冲 15 个包。这使得交织不适合交互式应用;然而,交织对于流媒体非常有用。
总结
设计 RTP 应用时要记住的一个关键点是健壮性。错误隐藏是其中的一个主要部分,它允许应用在网络出现问题时也能正常运行。一个好的错误隐藏方案提供了在现实世界中可以使用的工具和遭受互联网广泛的固有丢包导致的持续失败的工具的区别。因此,所有应用都应该实现某种形式的错误隐藏。
第九章 错误恢复(Error Correction)
- 前向纠错
- 信道编码
- 重传
- 现实注意事项
尽管掩盖传输错误可以明显提高质量,但避免或纠正错误将是更好的选择。本章将介绍发送端采用的一些技术,以帮助接收端从包丢失和其他传输错误中恢复。
用于纠正传输错误的技术分为两类:前向纠错和重传。前向纠错依赖于发送端向媒体流中冗余的额外数据,然后接收端可以利用额外数据,以一定的概率纠正错误。另一方面,重传依赖于对特定包的显式请求。
如前所述,用于纠正传输错误的主要技术包括重传和前向纠错。这两种方案的适用标准需要考虑特定应用场景和网络环境等条件。本章将详细阐述这些方案的技术细节和优缺点。
前向纠错
前向纠错( FEC )算法通过变换原始码流,增加传输的健壮性。原始码流转换生成一个体积更大的码流,在有损介质或网络传输。变换后的码流附加信息,允许接收者在存在传输错误的情况下,准确地重构原始码流。前向纠错算法主要用于数字广播系统,如移动电话和空间通信系统,以及存储系统,如光盘、计算机硬盘和存储器。由于因特网是一个有损介质,同时由于媒体应用对损耗敏感,FEC方案被提出并标准化为RTP协议。FFec方案的重建效果取决于使用的FEC包数量和类型,以及误包的特点。
使用FEC的RTP发送端必须根据网络的丢包特性来决定FEC的冗余数据量。其中一个方案是根据返回的RR包,通过丢包率统计信息来调整媒体流中的FEC冗余数据量。
理论上,通过改变编码可以纠正一定比例包丢失。但实际中FEC修复概率多个因素。其中一个主要限制因素是: 增加FEC会占用更多带宽。这可能会加剧网络拥塞,从而降低FEC纠错能力,
请注意,可以根据RR反馈的丢包率调整FEC包的数量,但RR包本身没有提供关于单个数据包丢失事件的反馈。此外,FEC也不能保证所有丢失的数据包都能被纠正。FEC的目的是将丢包率降低到可接受的程度,并依靠错误隐藏来处理其他丢失的数据包。
为了确保 FEC 能够正常工作,丢包率必须在一定范围内,并且丢包必须以特定的模式发生。例如,一个设计用于纠正 5% 丢失的 FEC 方案,显然无法纠正 10% 的丢包情况。有个不易察觉的事实是,这种方案可能只有在丢失的数据包不连续的情况下,才能纠正 5% 的丢失。
FEC 的主要优点是在多播应用中,可以扩展到非常大范围,包括没有丢包的接收者。增加的冗余数据量取决于平均丢包率和丢包模式,两者都与接收者无关。FEC 的缺点是冗余量取决于平均丢包率。低于平均丢包的接收端将接收冗余数据,这会浪费容量,必须丢弃这些数据。丢包高于平均水平的将无法纠正所有的错误,只能依靠隐藏。如果不同接收端的丢包率非常不均匀,就不可能用单一的 FEC 流来满足所有的丢包率(分层编码可能有所帮助;参见第 10 章,拥塞控制)。
FEC的另一个缺点是,由于在FEC包到达前无法进行错误修复,它可能会增加端到端延迟。如果FEC的数据包比保护的数据要晚很长时间送达,接收端就需要在快速播放损坏数据和等待FEC修复之间进行选择,这可能会进一步增加延迟。交互式应用中,降低延迟至关重要。
存在许多 FEC 方案,其中有几个已被作为 RTP 框架的一部分采用。我们将首先回顾一些独立于媒体格式的技术:奇偶性 FEC 和里德-所罗门(Reed-Solomon)编码,然后再研究特定的音频和视频格式。
奇偶校验 FEC(parity FEC)
奇偶校验码是最简单的错误检测/校正码之一。奇偶运算可以数学地描述为位流异或(XOR)。XOR 操作是位逻辑操作,定义为两个输入:
0 XOR 0 = 0
1 XOR 0 = 1
0 XOR 1 = 1
1 XOR 1 = 0
因为 XOR 满足交换律的,这个操作可以很容易地扩展到超过两个的输入:
A XOR B XOR C = (A XOR B) XOR C = A XOR (B XOR C)将单个输入更改为 XOR 操作输出,从而允许奇偶校验位检测错误。
奇偶校验码在使用RTP over UDP的系统中非常有用(在这种系统中,主要的威胁是包丢失,而不是字节损坏)。因此,有必要将奇偶校验位放在一个独立的包中,以保护它们所代表的数据。如果有足够的奇偶校验位,它们可以用于完全恢复丢失的包的内容。依据的性质是,对于任意值的 A 和 B 满足条件:
A XOR B XOR B = A
如果我们分别发送三个包 A、B 和 A XOR B,我们只需要接收其中的两个来恢复 A 和 B 的值
图 9.1 中的示例中7bit丢失通过此过程恢复,但实际上这个过程适用于任意长度的比特流。我们可以直接将这个过程应用于 RTP 数据包,将整个包视为比特流,并计算原始数据包的异或校验包,以便从丢失中进行恢复。
图 9.1. 使用位流之间的奇偶校验恢复丢包数据
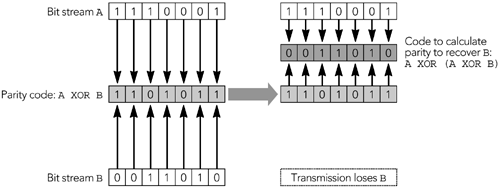
RFC 2733 定义了适用于 RTP 流的奇偶校验 FEC 标准,RFC 2733 为 RTP 包定义一个通用的 FEC 方案,可以操作任何负载类型,并且对不识别FEC的接收端保持向后兼容。该方案通过原始的RTP包来生成Fec包,然后,将这些FEC包作为一个独立的RTP流发送,该RTP流可以用于修复原始数据中的包,如图9.2所示
图 9.2. 奇偶校验 FEC 修复
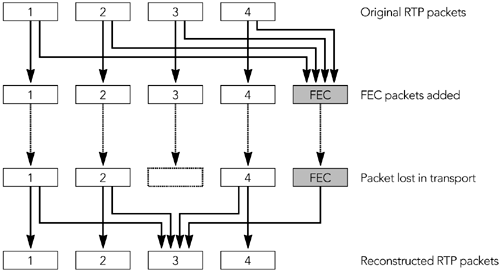
奇偶校验 FEC 包格式
如图9.3所示,FEC包包括三个部分:标准的RTP包头、FEC包头和负载数据本身。FEC包是由它所保护的数据包生成的,除了RTP包头的某些字段外。它是通过对数据包进行奇偶运算得到的结果。
图 9.3. 奇偶校验 FEC 包的格式
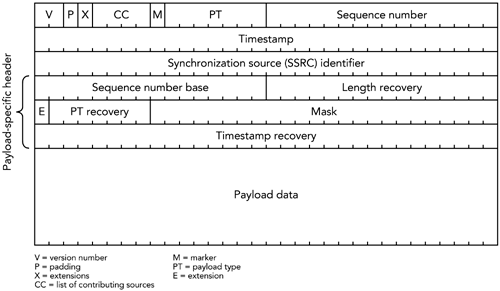
RTP 包头的字段如下:
- 版本号、有效负载类型、序列号和时间戳根据通用的方式进行分配。每发送一个FEC包,序列号就会增加1。时间戳设置为发送FEC包时的RTP媒体时钟值(时间戳不太可能与前后RTP包的时间戳相等),因此,与FEC方案无关的是,FEC包中的时间戳是单调递增的。
- SSRC 值与原始数据包的 SSRC 值相同。
- 填充、扩展、CC 和标记位通过原始包计算为原始数据包 XOR 继续。原始数据包丢失时对这些字段进行重恢复。
- CSRC 列表和头扩展不存在,他们和 CC 字段和 X 位的值无关。如果它们存在于原始数据中,则它们作为 FEC 分组的负载部分(在 FEC 有效负载包头之后)被包括。
注意,在奇偶校验 FEC 包中禁止使用 CSRC 列表和包头扩展,这意味着根据标准的、与有效负载格式无关的 RTP 处理规则来处理 FEC 流并不总是可能的。特别是,FEC 流不能通过 RTP 混流器(媒体数据可以,但是混流器必须为混合数据生成一个新的 FEC 流)
负载头部保护了原始RTP头部中在FEC包的RTP头部中没有被保护的字段。这些字段包括负载头部的六个字段:
- 序列号基数(Sequence number base)。组成此 FEC 包的原始包的最小序列号。
- 长度恢复(Length recovery)。原始数据包长度的异或。长度计算为有效负载数据、CSRC 列表、头扩展和原始数据包的填充的总长度。此计算允许即使在媒体包的长度不相同时也应用 FEC 过程。
- 扩展(Extension). FEC 有效负载包头中存在附加字段的指示符。它通常设置为 0,表示不存在扩展(本章后面描述的 ULP 格式使用扩展字段来指示是否存在额外的分层 FEC)
- 有效负载类型(PT)恢复(Payload type recovery)。原始数据包的有效负载类型字段的异或。
- 掩码(Mask)。一种位掩码,指示在奇偶校验 FEC 操作中包括序列号基之后的哪些包。如果掩码中的位 i 被设置为 1,则序列号为 N+i 的原始数据包与该 FEC 包相关联,其中 N 是序列号基数。最低有效位对应于 i = 0,最高有效位对应于 i = 23,允许在最多 24 个包上计算奇偶校验 FEC,这可能是非连续的。
- 时间戳恢复(Timestamp recovery)。原始数据包的时间戳的异或(XOR)。
有效负载数据通过对CSRC列表进行XOR运算而导出(如果存在),同时还导出包头扩展(如果存在)和要保护的包的有效负载数据。如果数据包的长度不同,计算异或时会将较短的数据包填充以匹配最大数据包的长度(填充位的具体内容不重要,只要在处理特定数据包时使用相同的值即可;最简单的方式是填充0)。
奇偶校验 FEC 的使用
FEC 包的数量及其生成方式取决于发送端采用的 FEC 方案。有效负载类型对映射过程的限制相对较少 :一组至多 24 个连续的原始数据包被输入到奇偶校码的生成中,每个数据包可用于生成多个 FEC 数据包。
负载包头中的序列号基数和掩码用于指示哪个包用于生成 FEC 包,不需要额外的字段。因此,可能因为 RTCP RR 包中的接收质量信息 , FEC 运算可以在 RTP 会话运行时更改。FEC 操作的变化能力赋予了发送端很大的灵活性,发送端可以根据网络条件调整 FEC 的使用量,并确保接收端仍然可以使用 FEC 进行恢复。
在发送原始数据包时,发送端需要实时生成适当数量的FEC数据包。选择要冗余的FEC的数量没有固定的方法,因为选择取决于网络的丢包特征,而标准并不要求特定的方案。以下是一些可能的选择:
-
最简单的方法是每 n - 1 个数据包发送一个 FEC 数据包,如图 9.4A 所示,允许在每 n 个包中最多有一个丢失的情况下进行恢复。这种 FEC 方案开销低,易于计算,易于适应:因为 FEC 包的比例与 RTCP-RR 包中报告的丢包比例直接对应。
如果数据包丢失的概率是稳定的,则这个方法可以很管用,但连续突发的丢包数据就无法恢复了。如果突发丢包是常态,如在公共互联网中,奇偶校验可以大间隔计算,而不是相邻数据包间计算,从而产生更强大的保护。如果是后面的方案,可以很好地进行流式传输,但有很大的延迟,使其不适合交互式应用。
-
一个更健壮的方案是在每对数据包之间发送一个 FEC 包,但是开销要高得多,如图 9.4B 所示。这种方法允许接收端纠正每一个数据包丢失和大量连续丢包。这种方法的带宽开销很高,但是增加的延迟相对较小,因此更适合于交互式应用。
-
高阶方案允许从更多的连续丢包中恢复。例如,图 9.4C 中的方案,该方案可以从多达三个连续数据包的丢失中恢复。由于需要计算多个包的 FEC,引入的时延相对较高,因此这些方案不太适合交互使用。不过,它们在流媒体应用中很有用。
图 9.4. 几种可能的 FEC 方案
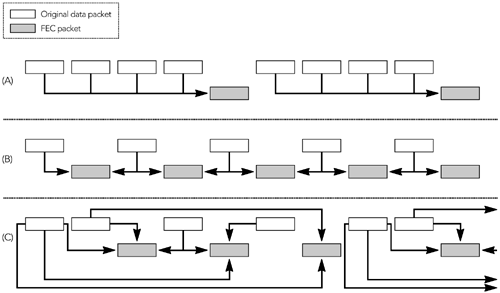
为了使奇偶校验FEC的向后兼容,一个重要的考虑是较旧的接收端不能看到FEC包。因此,通常将数据包作为单独的RTP流发送到相同的目标地址,但使用不同的UDP端口。例如,考虑一个会话,其中原始的RTP数据包使用静态有效负载类型0(G.711μ-law),通过端口49170进行发送,而RTCP则通过端口49171进行发送。FEC数据包可以通过端口49172进行发送,相应的RTCP可以通过端口49173进行发送。FEC包使用动态有效负载类型,例如122。这种情况可以在SDP中描述。
v=0
o=hamming 2890844526 2890842807 IN IP4 128.16.64.32
s=FEC Seminar
c=IN IP4 10.1.76.48/127
t=0 0
m=audio 49170 RTP/AVP 0 122
a=rtpmap:122 parityfec/8000
a=fmtp:122 49172 IN IP4 10.1.76.48/127
本章后面一节“音频冗余编码”中描述的另一种方法,将奇偶校验 FEC 包作为媒体的冗余编码来传输。
恢复丢包
接收端接收 FEC 包和原始数据包。如果没有数据包丢失,则可以忽略奇偶校验 FEC。在丢包的情况下,FEC 包可以与剩余的数据包组合,帮助接收端恢复丢失的包。
恢复过程分为两个阶段。首先,必须确定哪一个原始数据包和 FEC 数据包必须组合计算,以恢复丢失的数据包。完成之后,第二步是重构数据。
任何合适的算法都可以用来确定哪些包必须组合在一起。RFC 2733 给出了一个例子,如下图所示:
-
当接收到 FEC 包时,检查序列号基数和掩码字段,来确定它保护哪些包。如果已接收到所有数据包,则 FEC 数据包是冗余的并被丢弃。如果其中一些数据包丢失,并且它们的序列号小于最大接收序列号,则尝试恢复;如果恢复成功,则丢弃 FEC 数据包,并将恢复的数据包存储到播放缓冲区。否则,FEC 包被存储以备将来使用.
-
当接收到数据包时,检查所有存储的 FEC 包以查看新的数据包是否使恢复成为可能。如果是,在恢复之后,FEC 包被丢弃,恢复的包进入播放缓冲区。
-
已恢复的包被视为已接收到的包,可能会触发进一步的恢复尝试。
最终,所有的 FEC 包都将作为冗余使用或丢弃,所有可恢复的丢包都将被重建。
该算法依赖于确定特定的数据包是否在Fec恢复的列表中。进行这个判断需要查看FEC包引用的数据包集合;如果只有一个包缺失,可以进行恢复。恢复过程类似于生成FEC数据的过程。在数据包和FEC包的等价字段上进行异或(XOR)操作,结果就是原始的数据包。
- 恢复包的 SSRC 设置为其他包的 SSRC。
- 恢复包的填充、头扩展、CC 和标记位作为原始包和 FEC 包中相同字段的异或生成。
- 从原始序列号的间隙中知道恢复包的序列号(即,不需要恢复它,因为它是直接已知的)。
- 原始包中的有效负载类型字段的 XOR 异或,以及 FEC 包的有效负载类型恢复字段生成了恢复包的有效负载类型。时间戳以相同的方式恢复。
- 有效负载的长度计算方法是原始包长度的 XOR 异或和 FEC 包的长度恢复字段
- 贡献源(CSRC(contributing source) lists)(如果存在),扩展包头(如果存在)和恢复包的有效负载,通过原始数据包中那些字段的 XOR 异或,加上 FEC 数据包的有效负载来计算(因为 FEC 包从不包含 CSRC 列表或包头扩展本身,并且它携带原始字段的受保护版本作为其负载的一部分)
最终我们对丢失的数据包进行了精确的重建,与原始包在位级上完全相同。RFC 2733 FEC 方案没有部分恢复。如果有足够的 FEC 包,则丢失的包可以完全恢复;如果没有,则无法恢复任何内容。
非均匀错误保护
有些媒体类型需要精准恢复,而有些媒体类型可以恢复最重要的部分。有时可以在只恢复部分数据包的同时获得大部分数据。例如,有些音频编解码器具有最少的需要恢复的比特数,以提供可理解的语音,附加的数据不是必须的,但如果能够恢复,则可以提高音频质量。只恢复最小数据的恢复方案在质量上将低于恢复完整数据包的恢复方案,但其开销可能要小得多。
另外,也可以为整个包提供一定程度的保护,但对包中的最重要部分提供更高级别的保护。在这种情况下,整个包有一定概率被恢复,但是重要部分的恢复率更高。
这种方案叫不均匀分层保护(unequal layered protection ULP)。在撰写本文时,还没有将 ULP RTP 的标准。然而,IETF 正在 RFC 2733 中定义奇偶校验 FEC 码的扩展功能。这项工作还没有最终完成,最终标准可能与本文描述的略有不同。
该扩展提供分层编码,每一层都保护特定的 数据包的一部分。每一层可能有不同的长度,最大长度为 组中最长的数据包。各层的排列方式为多层保护 数据包的开头,后面的部分由较少的层保护。这 这种安排使数据包的开头更有可能被恢复。
基于奇偶校验 ULPFEC 的 RTP 负载格式如图 9.5 所示。负载包头的头部与 RFC 2733 的开始相同,但是设置了扩展位,并且随后附加的包头描述分层 FEC 操作。数据包的有效负载数据部分按顺序,包含每个层的受保护数据。
图 9.5. 基于奇偶校验 FEC 的 ULP RTP 负载格式
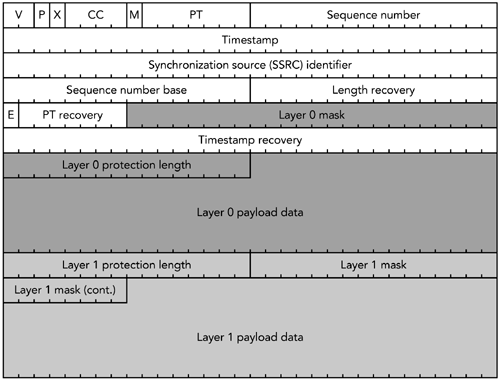
在撰写本文时,有一个针对这里描述的基于 ULP 的奇偶校验 FEC 的 RTP 有效负载格式的修改动作,以便除了提供分层保护之外,它还更新 RFC 2733 的奇偶校验 FEC 格式以更好地支持 RTP 混流器。这些改变预计不会改变所描述的分层编码概念,但分组格式的细节很可能会改变。
基于 ULP 的奇偶校验 FEC 的操作类似于标准奇偶校验 FEC 格式,只是每一层的 FEC 只对包的一部分(而不是整个包)进行计算。每一层都必须包含下层保护的包,保护下层的 FEC 的数量与层的数量累加。 FEC 包可能包含所有层的数据,一个接一个地堆积在包的负载部分。最低层的 FEC 出现在所有 FEC 包中;根据 FEC 操作,更高的层出现在包的子集中。只有一个 FEC 流,与保护层的数量无关。
恢复以层为基础进行,每层都可能恢复部分数据包。每一层的恢复算法与标准奇偶校验 FEC 格式相同。从基础层开始,依次恢复每个层,直到执行所有可能的恢复操作。
ULP 的使用不适合所有有效负载格式,因为要使其工作,解码器必须能够处理部分数据包。当这样的部分数据有用时,ULP 可以提供显著的质量增益,其开销比完全 FEC 保护所需的开销少。
里德-所罗门码
里德-所罗门码是奇偶校验码的一个替代方案,它以增加复杂性为代价 ,以更少的带宽开销提供保护。特别是,在传统奇偶校验码效率较低的情况下,它们提供了很好的抗突发丢失保护。
里德-所罗门码将每个数据块视为一个多项式方程的系数。该方程在一定的数字基数上对所有可能的输入进行评估,从而产生要发送的 FEC 数据。通常,该过程按字节操作,使实现更简单。完整的处理超出了本书的范围,但实际上 ,编码过程是相对直接的,并且解码算法可优化。
虽然里德-所罗门码相比奇偶校验码在技术上有许多优点,但它在RTP流传输中的应用还没有一个确定的标准。均匀和非均匀FEC的里德-所罗门编码技术已经引起广泛关注,且可能在未来制定相应标准。
音频冗余编码
到目前为止,我们所讨论的纠错方案都与所使用的媒体类型无关。但是,也可以使用与媒体类型相关的方法来纠错,这些方法通常可以提高恢复效果。
为 RTP 定义的第一种特定于媒体的纠错方案是 RFC 2198 中指定的音频冗余编码。这种编码方案的动机是交互式语音电话会议,在这种会议中,快速修复丢失的数据包比准确地修复更为重要。因此,每一包以更大的压缩格式包含音频数据的原始帧和前一帧的冗余副本。编码方案如图 9.6 所示。
图 9.6。音频冗余编码
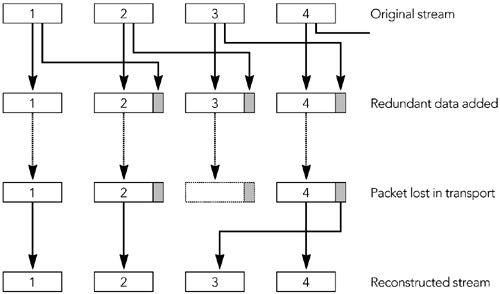
当收到冗余音频流时,接收端可以用冗余副本来填补原始数据流中的任何空白。由于冗余副本通常比主副本压缩得更狠,虽然不能精准恢复,但在感觉上比流中的有间隙要好。
冗余音频包的格式
冗余音频负载格式如图 9.7 所示。RTP 包头具有标准值,有效负载类型表示冗余音频的负载类型。
图 9.7. 音频冗余编码的 RTP 有效负载格式
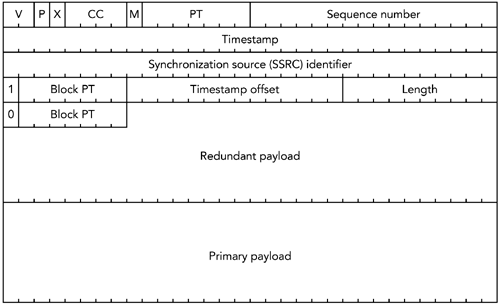
包头包含四个字节用于数据的冗余编码,外加一个表示原始媒体的有效负载类型的最后一个字节。每个冗余编码的四个字节负载头包含下面几个字段:
-
标识这是冗余编码还是主编码的bit位。
-
冗余编码的有效负载类型。
-
以 10 bit无符号整数存储的冗余编码的长度。
-
时间戳偏移量,存储为 14 bit无符号整数。该值从包的时间戳中减去,以指示冗余数据的原始播放时间。
最后的有效负载包头是一个单字节,由一个位组成,表示这是最后的包头,以及主数据的 7 位有效负载类型。有效负载包头之后紧跟着数据块,数据块按与包头相同的顺序存储。数据块之间没有填充或其他分隔符,它们通常不是 32bit 对齐的(尽管它们是八位对齐的)。
例如,如果主编码是 GSM,每包发送一帧 20 毫秒,冗余编码是以一个延迟发送的低速 LPC 包,则完整的冗余音频包将如图 9.8 所示。请注意,时间戳偏移量为 160,因为 8kHz 时钟的 160 个刻度表示 20 毫秒偏移量(8000 个刻度/秒 x 0.020 秒=160 个刻度)。
图 9.8 冗余音频包示例
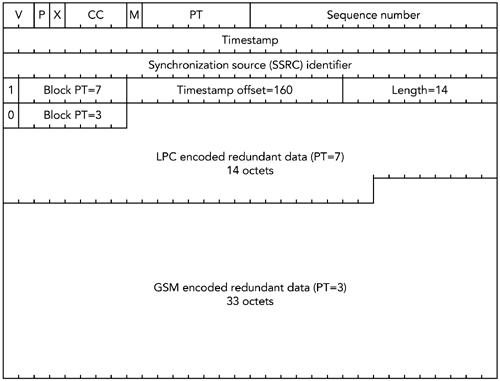
该格式允许冗余副本延迟多个包,作为一种以额外延迟为代价,抵消突发丢包的方法。例如,如果经常有突发的两个连续丢包,那么冗余副本可以在原始包之后发送两个包。
选择冗余编码应该反映这些编码的带宽要求。预期冗余编码使用的带宽将比主编码少得多——例外的情况是主编码的带宽非常低,处理要求很高,在这种情况下可以使用主编码的副本作为冗余。冗余编码的带宽不应高于主编码。
还可以在每个包中发送多个冗余数据块,允许每个包修复多个丢包事件。很少有必要使用多级冗余,因为在实践中,你通常可以通过延迟冗余以较低的开销实现类似的保护。但是,如果使用多个冗余级别,则每个级别所需的带宽预计将显著小于前一级别的带宽。
冗余音频格式在 SDP 中的定义如下例所示:
m=audio 1234 RTP/AVP 121 0 5
a=rtpmap:121 red/8000/1
a=fmtp:121 0/5
在这种情况下,冗余音频使用动态有效负载类型 121,主要和次要编码是有效负载类型 0(PCMμ-law)和 5(DVI)。
也可以使用动态负载类型作为主要或次要编码,例如:
m=audio 1234 RTP/AVP 121 0 122
a=rtpmap:121 red/8000/1
a=fmtp:121 0/122
a=rtpmap:122 g729/8000/1
其中初级为 PCM µ-law,次级为 G.729,采用动态有效负载类型 122。
请注意,SDP 片段的 m= 和a=fmtp: 行中都出现了主编码和次编码的负载类型。因此,接收端必须准备好使用这些编解码器接收冗余和非冗余音频,这两种编解码器都是必需的,因为在通话突发中发送的第一个和最后一个包可能是非冗余的。
冗余音频的实现在处理一次通话中的第一个和最后一个数据包的方式上不一致。第一个包不能用次要编码发送,因为没有前面的数据:一些实现使用主有效负载格式发送它,而另一些实现使用冗余音频格式,次要编码的长度为零。同样,发送最后一个包的冗余副本也很困难,因为没有任何东西可以承载它:大多数实现无法恢复最后一个数据包,但可能只发送带有次要编码的非冗余数据包。
冗余音频的局限性
虽然冗余音频编码可以提供精确的修复(如果冗余副本与主副本相同),但冗余编码更有可能带宽占用较低,因此质量较低,并且只能提供近似的修复。
冗余音频的有效负载格式也不会为每个冗余编码保留完整的 RTP 头,尤其是,不保留RTP 标记位和 CSRC 列表。标记位的丢失不会引起不必要的问题,因为即使标记位与冗余信息一起发送,它仍然有丢失的可能,因此,在编写应用时仍然必须考虑到这一点。同样,由于音频流中的 CSRC 列表一般改变相对较少,因此建议需要此信息的应用,可以假设 RTP 包头中的 CSRC 数据可以用于重构冗余数据。
使用冗余音频
冗余音频有效负载格式主要用于音频电话会议,在某种程度上,效果非常好;然而,编解码器技术的进步意味着,现在负载格式的开销可能太高了。
例如,提出冗余音频的原始论文,建议使用 pcm 编码的音频(每帧 160 个字节)做主编码,LPC 作为次要编码。在这种情况下,可以接受5字节负载包头。然而,如果主编码是 G.729,每帧 10 字节,那包头大小就不可接受了。
除了在一定程度上限制采用冗余音频的音频电话会议外,冗余音频还用于两种场景:奇偶校验 FEC 和 DTMF 音调。
前面描述的奇偶校验 FEC 格式要求 FEC 数据与原始数据包分开发送。一种常见的方法是将 FEC 作为另一个端口上的附加 RTP 流发送;然而,另一种方法是将其视为媒体的冗余编码,并使用冗余音频格式将其承载到原始媒体上。这种方法降低了 FEC 的开销,但接收端必须理解冗余的音频格式,从而降低了向后兼容性。
DTMF 音调和其他电话的 RTP 有效负载格式建议使用冗余编码,因为这些音调需要可靠地传送(例如,通过 DTMF 触摸音进行选择的电话语音菜单系统,如果音调不能可靠地识别,则会更加烦人)。对每个音调的多个冗余副本进行编码使得即使在包丢失的情况下也能够实现非常高的音调可靠性。
信道编码
前向纠错是信道编码的一种形式,它需要向媒体流中冗余信息防止丢包。媒体流还可以通过其他方式来匹配特定网络路径的丢包特性,下面几节将讨论其中的一些方式。
部分校验和
公共互联网中的大部分丢包是由网络拥塞引起的。然而,如第 2 章所述,分组网络上的语音和视频通信,在某些类别的网络(例如,无线网络)中非阻塞性丢包和包损坏是常见的。尽管在许多情况下丢弃具有损坏位的数据包是合理的,但是一些 RTP 有效负载格式可以使用损坏的数据(例如,AMR 音频编解码器)。你可以通过禁用 UDP 校验和(如果使用 IPv4的话)或使用带有部分校验和的传输来使用部分损坏的 RTP 数据包。
当在标准的 UDP/IPv4 协议使用 RTP 时,可以完全禁用 UDP 校验和(例如,在支持 sysctl 的 UNIX 计算机上使用 sysctlnet.inet.UDP.checksum=0, 或者在 Winsock2 上使用UDP-NOCHECKSUM套接字选项)。禁用 UDP 校验和,好处是,损坏的有效负载数据包将被传递到应用,从而可以挽救部分数据。缺点是,包头可能损坏,导致包被误用或不可用。
请注意,有些平台不允许禁用 UDP 校验和,而另一些平台允许将其作为全局设置,但不允许按流设置。在基于 IPv6 的实现中,UDP 校验和是必需的,不能禁用(尽管可以使用 UDP-Lite 建议)。
更好的方法是使用带有部分校验和的传输,例如 UDP-Lite,这些协议还在完善,它扩展了 UDP,使校验和只计算数据包的一部分。校验和可以只计算 RTP/UDP/IP 包头,或者包头 + 负载的开头。使用部分校验和,传输层可以丢包,因为包头(或其他有效负载的重要部分)已损坏,只传递那些在有效负载中非重要部分有错误的数据包。
第一个充分利用部分校验和的 RTP 负载格式是 AMR 音频编解码器。这是为许多第三代移动电话系统选择的编解码器,AMR RTP 负载类型的设计者高度重视对位错误的兼容性。裸流的每一帧都被分为 A 类数据(对解码至关重要)和 B 类和 C 类数据(如果接收到这些数据,质量会提高,但不是必须的)。AMR 输出的一个或多个帧被放入每个 RTP 包中,可以选择使用包含 RTP/UDP/IP 包头和 a 类位的部分校验和,而其他位则不受保护。这种缺乏保护的情况允许应用忽略 B 类和 C 类位中的错误,而不是丢弃数据包。例如,在图 9.9 中,阴影部分不受校验和保护。这种方法似乎没有什么优势,因为不受保护的比特相对较少,但是当使用包头压缩(见第 11 章)时,IP/UDP/RTP 包头和校验和被减少到只有4位,增加了部分校验和带来的收益。
图 9.9. 在 AMR 有效负载格式中使用部分校验和的示例
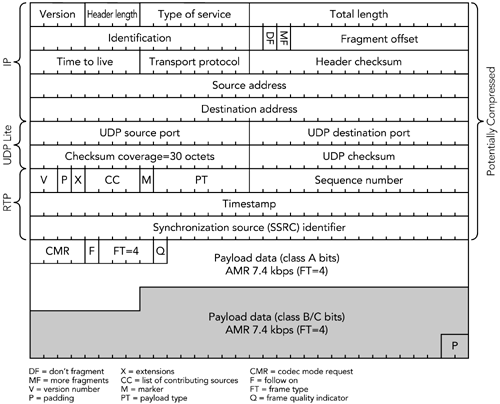
AMR 有效负载格式还支持交织和冗余传输,以增强健壮性。所以使用AMR非常健壮,可以很好地处理在蜂窝网络中常见的位损坏。
部分校验和并不是一个通用工具,因为它们不能改善由于拥塞而导致包丢失的网络的性能。然而,随着无线网络变得越来越普遍,预计未来的有效负载格式也将使用部分校验和。
参考帧选择
许多负载格式依赖于帧间编码,如果不使用前一帧中的数据,就不能解码当前帧。帧间编码最常用于视频编解码器,在这种编解码器中,运动矢量允许图像平移或图像的部分运动,而无需重新发送前一帧中已移动的部分。帧间编码对于获得良好的压缩效率至关重要,但它放大了包丢失的影响(显然,如果一个帧依赖于丢失的包,则该帧不能被解码)。
参考帧选择可以提升健壮性,如 H.263 和 MPEG-4 的一些变体中所使用的。这是另一种形式的信道编码,在这种编码中,如果预测其他帧的帧丢失,则根据接收到的另一帧重新编码未来的帧(见图 9.10)。与不进行帧间压缩(仅进行帧内压缩)发送下一帧相比,此过程节省了大量带宽。
图 9.10. 参考帧选择
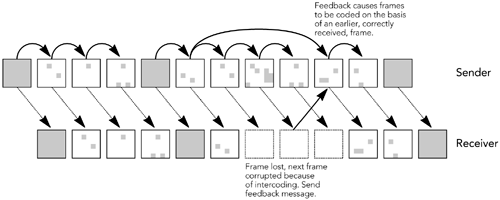
更改参考帧,接收端必须向发送端反馈数据包丢失。下一节将在重传中讨论反馈机制;同样的技术也可以用于参考帧的选择,只需要稍作修改。关于在 RTP 中使用参考帧选择的标准的工作正在进行中。
重传
如果接收方向发送方反馈请求重传传输过程中丢失的数据包,也可以恢复丢包。重传是一种简单但高效的纠错方法,在某些场景下表现优秀。然而,重传并非完全适用所有场景,有其适用范围。RTP标准目前没有包含重传,但人们正在研发一个新的RTP标准,它将提供基于RTCP的重传请求以及其他实时反馈机制。
作为重传体的 RTCP
因为 RTP 包含一个用于接收报告和其他数据的反馈通道 RTCP,所以自然也会使用该通道来进行重传请求。需要两个步骤:需要为重传请求定义数据格式,并且必须修改时序规则以允许立即反馈。
包格式
基于重传的反馈的标准文件定义了两种额外的 RTCP 包类型,表示肯定和否定的应答。最常见的类型应该是否定的确认,报告一组特定的数据包丢失。肯定的确认报告数据包已正确接收。
否定应答(NACK)的格式如图 9.11 所示。NACK 包含一个表示丢包的标识符和一个位图,该位图标识后面的 16 个包中的哪一个丢失了,值为 1 表示丢失。发送端不应该仅仅因为位掩码中相应的位置设置为零,就认为接收端已经收到了数据包;只能说明此时接收端没有报告丢失的包。在接收到一个 NACK 时,发送端需要重新发送标记为丢失的包,尽管它没有这样做的义务。
图 9.11. RTCP 反馈否定应答的格式
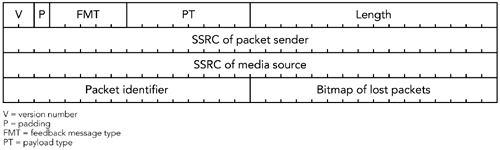
肯定确认(ACK)的格式如图 9.12 所示。ACK 包含表示正确接收的包的包标识符,以及位图或后面包的计数。如果 R 位设置为 1,则最后一个字段是在数据包标识符之后正确接收的数据包数的计数。如果 R 位设置为零,则最后一个字段是一个位图,表示还接收了以下 15 个数据包中的哪一个。这两个选项允许有效地发出少量丢包(R=1)的长时间 ack 和随机丢包(R=0)的偶发 ack 的信号。
图 9.12. RTCP 反馈肯定性确认的格式
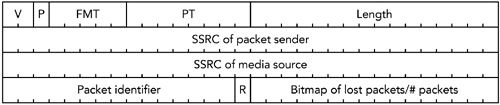
ACK 和 NACK 之间的选择取决于使用的修复算法和所需的语义。ACK 表示接收到了一些数据包;发送端可能认为其他数据包丢失了。另一方面,NACK 发出包丢失的请求,但不提供其余包的信息(例如,当重要包丢失时,接收端可以发送 NACK,但默默地忽略不重要数据的丢失)。
反馈包作为一个复合 RTCP 包的一部分发送,其方式与所有其他 RTCP 包相同。它们放在复合包的最后,在 SR/RR 和 SDES 项之后。(参见第 5 章,RTP 控制协议,以查看 RTCP 包格式。)
时序规则
RTCP 的标准定义有严格的时序规则,这些规则指定了何时可以发送数据包,并限制了 RTCP 的带宽消耗。重传标准文档修改了这些规则,允许比正常时间更早地发送反馈包,代价是延迟发生后续的包。其结果是短期内违反了带宽限制,长期看的 RTCP 传输速率保持不变。修改后的规则总结如下:
-
当不需要发送反馈消息时,根据标准时序规则发送 RTCP 数据包,但不强制执行 RTCP 报告之间的 5 秒最小间隔(应使用第 5 章 RTP 控制协议中标题为报告间隔一节中讨论的减小的最小间隔)。
-
如果一个接收端想在 RTCP 传输时间之前发送反馈,它应该等待一个短暂的、随机的抖动(dither)间隔,并检查它是否已经看到了来自另一个接收端的相应反馈消息。如果是,它必须避免发送,并遵循常规的 RTCP 调度。如果接收端没有看到来自任何其他接收端的类似反馈消息,并且在此报告间隔期间没有发送反馈,则可以将反馈消息作为复合 RTCP 包的一部分发送。
-
如果发送了反馈,则根据两倍标准间隔重估下一次调度的 RTCP 包传输时间。在重估的包被发送之前,接收端可能不会发送任何反馈(也就是说,对于每个常规的 RTCP 报告,它可能只发送一次反馈包)。
抖动(dither)间隔是根据组大小和 RTCP 带宽来选择的。如果会话只有两个参与者,则抖动间隔设置为 0;否则,它被设置为发送端和接收端之间往返时间的一半,乘以成员的数量(如果往返时间未知,则设置为 RTCP 报告间隔的一半)。
选择抖动间隔的算法允许每个接收端在小会话时几乎立即发送反馈。随着接收端数量的增加,每个接收端发送重传请求的速率降低了,但是另一个接收端看到相同丢包并发送相同反馈的机会增加了。
操作模式
RTP 重传标准文档允许比标准 RTCP 更高的速率发送反馈,但它仍然对发送时间施加了一些限制。根据组大小、可用带宽、码率、丢包率和所需的报告粒度,应用将在三种模式之一(即立即模式、早期模式和常规模式)下运行,如图 9.13 所示。
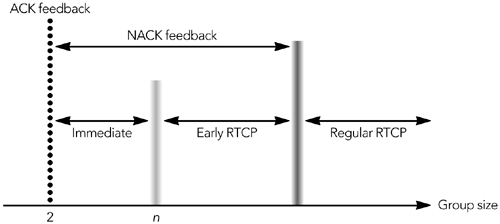
在即时反馈模式中,对于感兴趣的事件都有足够的带宽来发送反馈。在反馈模式初期,没有足够的带宽提供所有事件的反馈,接收端只能报告可能事件的子集。即时模式的性能最好。当应用进入早期反馈模式时,它开始依赖于丢包的统计抽样,并且只向发送端提供近似的反馈。在图 9.13 中,立即模式和早期模式之间的边界由组大小 n 表示,它随码率、组大小和发送端的比例而变化。
在即时和早期模式中,只允许 NACK 包。如果会话只有两个参与者,则可以使用 ACK 模式。在 ACK 模式下,发送对每个事件的确认,向发送端提供更详细的反馈(例如,ACK 模式可能允许视频应用确认每个完整的帧,从而使参考图片选择能够有效地操作)。同样,必须尊重重传配置文件的带宽限制。
适用性
限制重传适用性的主要因素是反馈延迟。重传请求到达发送端和重传包到达接收端至少需要一个往返时间。这种延迟会影响交互式应用,因为重新传输所花费的时间可能超过可接受的延迟界限。对于流媒体和其他延迟界限不那么严格的应用,重传可能是有效过的。重传允许接收端只请求丢失的包,并允许接受丢失部分包。在适当的情况下,结果可能是非常好修复效果。但在某些情况下,重传会很低效,例如:
-
每个重传请求使用一些带宽。当丢包率较低时,请求使用的带宽也较低,但是随着丢包变得更常见,请求消耗的带宽也会增加。
-
如果参与者众多,并且许多接收端看到相同的丢失,它们可能会同时请求重新传输。许多请求使用大量带宽,请求的内爆可能会压倒发送端。
-
如果参与者众多,并且每个接收端看到不同的丢失,则即使每个接收端只丢失一小部分数据包,发送端也必须重新传输大多数数据包。
当参与者较少且丢包率相对较低时,重传效果最好。当接收端数量增加,或丢包率增加时,请求重新传输丢失的包的效率会迅速降低。最后,超过这个边界后,如此使用正向纠错会更有效。
例如,Handley 观察了 122 个多播组,其中大多数包被至少一个接收端丢失。结果可能是几乎每个包都需要重新传输请求,这将需要巨大的开销。如果使用前向纠错,每个 FEC 包修复多个丢失,则必须发送的修复数据量要低得多。
重新传输的包不必与原始包相同。这种灵活性允许,在部分传输低效效率低的情况下使用重传,因为发送端可以通过发送一个 FEC 包来响应请求,而不是发送原始包的副本。事实上,重传的包和原始的包不一定是相同的,这也可能允许一次重新传输来修复多个丢包。
实现注意事项
如果使用纠错,RTP 可以显著增强对 IP 网络的不利影响的抗性。但是,这些技术是有代价的:实现会变得复杂,接收端需要更复杂的播放缓冲区算法,发送端需要实现逻辑来决定缓存多少待恢复数据以及何时丢弃这些数据。
接收端
使用这些纠错技术要求应用具有更复杂的播放缓冲区和信道编码框架。特别是,它需要将 FEC /重传延迟合并到播放点计算中,并且它需要允许在播放缓冲区中存在修复数据。
在计算媒体的播放点时,接收端必须为恢复数据的到达留出足够的时间。这可能意味着将音频/视频的播放延迟到其正常时间之外,具体多少取决于接收恢复数据所需的时间和所需的媒体播放点。
例如,交互式语音电话应用可能希望在短抖动缓冲区(short jitter buffer)和只有一个或两个数据包的音频播放延迟下运行。如果发送端使用如图 9.2 所示的奇偶校验 FEC 方案,其中每四个数据包后发送一个 FEC 包,它将在应用播放完它所保护的原始数据之后到达,FEC 数据将是无用的。
应用如何知道恢复数据何时到达?在某些情况下,可以提前发出信号,从而允许接收端调整其播放缓冲区的大小。信令可以是隐式的(例如,RFC 2198 冗余,其中发送端可以将零长度冗余数据插入音频流的前几个包中,允许接收端知道实际冗余数据将跟随在后面的包中),也可以是显式的会话设置(例如,包括在 SIP 邀请中的 SDP)。
不幸的是,信号可能延迟达到,修复方案可能会动态变化,或者修复时间不能提前知道(例如,使用重传时,接收端必须测量发送端的往返时间)。在这种情况下,接收端有责任通过延迟媒体播放或丢弃延迟到达的修复数据,来适应并最大限度地利用接收到的修复数据。通常情况下,接收端必须在没有发送端帮助的情况下进行调整,而依赖自己对应用场景的了解。
接收端需要缓冲到达的修复数据,以及原始的媒体包。如何做到这一点取决于修复的形式:一些方案与原始媒体耦合较弱,可以使用通用的信道编码层;其他方案与媒体紧密耦合,必须与编解码器集成。
在其他情况下,修复操作与媒体编解码器紧密耦合。例如,AMR 有效负载格式包括对部分校验和和冗余传输的支持。与 RFC 2198 中定义的音频冗余不同,这种冗余传输没有单独的包头,而且是针对 AMR 的:每个包包含多个帧,在时间上与下面的包重叠。在这种情况下,AMR 分组必须重叠,并且必须确保正确地帧添加到播放缓冲区(重复的帧被丢弃)。另一个例子是 MPEG-4 和 H.263 的一些模式中提供的参考画面选择,在这些模式中,信道编码依赖于编码器和解码器之间的共享状态。
发送端
在使用纠错功能时,发送端还需要缓冲比正常情况下更长的媒体数据。缓冲量取决于所使用的纠错技术:FEC 方案要求发送端保持足够的数据以生成 FEC 分组;重传方案要求发送端保持数据直到确定接收端不再请求重传。
在缓冲方面,发送端比接收端有优势,因为它知道所使用的修复方案的细节,并且可以适当地调整其缓冲区的大小。不论使用Fec 还是重传都是如此。
发送端须了解媒体流如何影响网络。本章大多技术均会在流中附加冗余数据可修复丢包,不可避免地提高码率。如果丢包源于互联网常见拥塞,码率升高或会恶化拥堵,进而增加丢包率。为规避此问题,纠错技术需要与拥塞控制结合,第10章将围绕此主题展开。
总结
在这一章中,我们讨论了各种方法来纠正由于丢包引起的错误。目前使用的方案包括各种前向纠错和信道编码,以及丢包重传。
如果正确得当,纠错技术可显著提升媒体体验,可以使不可用的系统变得可用。然而,如果使用不当,它可能导致原本要解决的问题恶化,并可能导致更严重的网络问题。拥塞控制的问题——使发送的数据量与网络容量相匹配,如在第 10 章《拥塞控制》中更详细地讨论的那样——形成了使用纠错的一个基本参考。
从这一章应该清楚的一件事是,错误纠正通过向媒体流中添加一些冗余,这些冗余可用于修复丢失的数据。这种操作模式与媒体压缩的目标有些不一致,后者的目标是消除流中的冗余。在压缩和容错之间需要进行权衡:在某些阶段,对媒体流进行额外的压缩会适得其反,最好使用固有的冗余来进行错误恢复(Error Correction)。当然,当然这个阈值取决于具体的网络、编解码器和应用。
第 十 章.拥塞控制
- 拥塞控制的必要性
- Internet的拥塞控制
- 对多媒体的影响
- 多媒体的拥塞控制
到目前为止,我们可以得出结论:以自然码率发送媒体流,如果试图超过自然码率,可能会导致数据包丢失。我们需要隐藏并纠正这些错误。然而,在现实世界中,媒体流很可能与其他流量共享网络。我们必须考虑发送码率对整体流量的影响,以及如何成为负责任的网络使用者。
拥塞控制的必要性
在讨论网络拥塞控制及其对媒体传输的影响之前,我们有必要了解下什么是拥塞控制,为什么需要拥塞控制以及忽视拥塞控制的影响。
正如我们在第2章《通过分组网络进行语音和视频通信》中所讨论的,IP网络提供了一种尽力而为的分组交换服务的功能。IP网络的一个基本特征是没有准入控制。网络层接收所有数据包,并尽最大努力将其交付。然而,网络层不能保证数据包的可靠送达,如果链路拥塞,多余的数据包将会丢失。上层协议关注丢包情况,并在拥塞发生时降低发送码率,这样就完成了拥塞控制过程。否则,可能会导致网络拥塞崩溃。
我们称网络负载的增加导致网络有效传输的数据包数量减少的情况叫做拥塞崩溃。图 10.1 ,当超过拥塞崩溃阈值时,到达率会突然下降。网络数据包在到达目的地之前就被丢弃(例如,由于中间节点的拥塞)而导致带宽浪费时,拥塞崩溃就发生了。
图 10.1. 拥塞崩溃

考虑这样一种情况: 数据源因为网络拥塞而丢弃了数据包,然后重新发送该数据包,但该数据包又被丢弃,周而复始。其他网络流量保持不变,网络的带宽完全被占用,却没有任何实际数据传输。这就是网络异常中的一种:拥塞崩溃。如果数据源能够检测到拥塞情况并相应降低发送码率,那么就可以缓解网络拥塞,避免上述情况出现。
拥塞崩溃不仅是一个理论模型。早期Internet中,TCP协议没有有效地控制拥塞,导致1980年代中期多次出现大规模的网络拥塞崩溃。为了防止此类事件的发生,Van Jacobson 开发了一种拥塞控制机制来优化TCP协议,详细内容我们将在下一部分“网络拥塞控制”中介绍。
随着非拥塞控制的多媒体流量的增加,人们再次开始关注拥塞崩溃的可能性。针对这个问题,人们提出了各种各样的机制。例如,路由器可以检测那些对拥塞事件没有响应的流,并对丢包率高于响应流的流进行惩罚。尽管这些机制目前尚未得到广泛应用,但未来可能会更积极地监督多媒体网络是否遵守拥塞控制的原则。
除了防止拥塞崩溃,拥塞控制还有另一个重要原因,就是实现公平的网络资源分配。不同流之间共享网络容量的策略不由IP层定义,而是由在其上运行的传输协议的拥塞控制算法定义。TCP采用基本平均分配带宽的模型。使用不同的拥塞控制算法会扰乱公平共享,结果通常降低TCP流的性能,因为它可能被更具侵占性的多媒体流挤占网络资源。
多媒体流量是否总应该比TCP流量得到优先受理,以及是否应始终分配更多网络带宽予多媒体流量,这仍待讨论。差异化服务和集成服务(RSVP)之类的机制,比如优先级队列(Priority Queue)等,允许根据应用需求,以可控制的方式为某些流赋予优先级。但是,目前这些服务优先机制在公共Internet还未全面部署。
Internet上的拥塞控制
互联网上的拥塞控制是通过运行在IP协议之上的传输协议层来实现的。简单来说,UDP并没有自带的拥塞控制功能,除非在UDP之上的应用程序层实现了相应的控制。相比之下,TCP则拥有一整套复杂的拥塞控制算法。
TCP是滑动窗口协议的一个典型案例。在发送数据包时,源端会为每个数据包附上序列号,并在接收方的ACK(肯定确认)数据包中回传这些序列号。最简单的滑动窗口协议要求每个数据包在发送后立即得到确认,然后才能发送下一个数据包,如图 10.2 所示。这就是所谓的“停止-等待”协议,因为发送端必须等待确认后才能发送下一个数据包。显然,“停止-等待”协议提供了流控制,防止发送数据量超出接收能力,但这也影响了传输性能,特别是当 RTT 比较大的时候。
图 10.2. 简单的停止等待协议

通过使用较大的窗口,可以在接收到确认之前发送多个数据包。每个TCP的ACK数据包都包含一个接收窗口,它告诉源端当前可以接收多少字节的数据,以及来自数据包的最高连续序列号。 允许源在接收到 ACK 之前发送足够的数据包以填充接收窗口。 随着 ACK 的出现,接收窗口随之滑动,从而允许发送更多数据。 此过程如图 10.3 所示,其中的窗口允许三个未完成的数据包。 与简单的停止等待协议相比,更大的接收窗口提高了性能。
图 10.3. 使用滑动接收端窗口
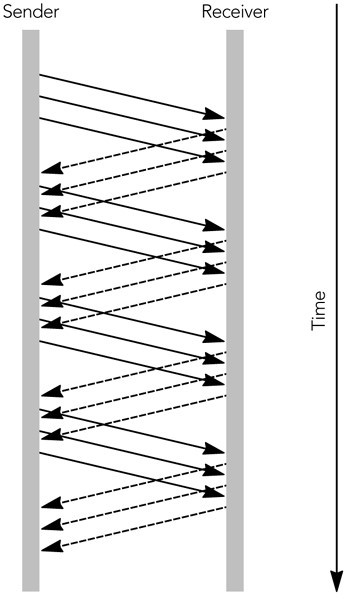
除了接收窗口之外,TCP 发送端还实现拥塞窗口。 通过估算网络容量来确定拥塞窗口的大小,并防止发送端使网络超载(即拥塞控制)。 发送端可以随时发送足够的数据包,来填满拥塞窗口和接收窗口中较小的那个。
拥塞窗口从一个数据包的大小开始。只要不发生丢包,它就会根据慢启动(slow start)算法或拥塞避免(congestion avoidance)算法增加拥塞窗口的数据包。新建连接最初使用慢启动算法,然后过渡到拥塞避免算法。
在慢启动模式下,每收到一个ACK,拥塞窗口的大小就增加一个数据包的大小。因此,发送端逐渐增加发送速率,直到达到网络能够承载的最大速率,如图 10.4 所示。慢启动模式会一直持续,直到发生数据包丢失,或者超过了慢启动阈值。
图 10.4. TCP 慢启动

在拥塞避免模式中,拥塞窗口每往返时间增加一个数据包的大小(而不是每个 ACK 的大小)。 结果是拥塞窗口呈线性增长,从而增加了发送码率。
TCP 连接根据这两种算法之一提高其发送码率,直到发生丢包为止。 丢包表示网络已达到容量上限,并且发生了短暂的拥塞。 发送端可以通过两种方式判断拥塞:超时或接收三个重复 ACK。
如果在发送数据之后很长一段时间内未收到 ACK,则假定数据已丢失。这是一种超时情况:当接收窗口中的最后一个数据包丢失时,或者当出现阻止数据包到达其目的地的(临时)故障时,会发生这种情况。当超时发生时,发送端将慢启动阈值设置为正在传输的数据包数的一半或两个数据包,以较大者为准。然后,它将拥塞窗口设置为一个数据包的大小,并进入慢启动。当发送端进入拥塞避免模式时,慢启动过程继续,直到超过慢启动阈值。长时间超时将导致发送端放弃,从而断开连接。
发送端可以检测到拥塞的另一种方法是通过存在重复的 ACK 数据包,当数据包丢失或重新排序时就会发生(见图 10.5)。 ACK 数据包包含接收到的最高连续序列号,因此,如果数据包丢失,则后续的 ACK 数据包将包含丢失之前的序列号,直到重新传输丢失的数据包为止。 如果对数据包进行重新排序,也会生成重复的 ACK,但是在这种情况下,当重新排序的数据包最终到达时,ACK 序列将恢复正常。
** 图 10.5. 生成重复的 ACK 包 **

如果发送端收到三个重复的 ACK 数据包,那我们可以推测,这是由于拥塞而丢了一个数据包。发送端通过将拥塞窗口和慢启动阈值设置为,发出去的数据包个数的一半或 2(以较大者为准)来作出响应。然后,发送端重新传输丢失的数据包, 并进入拥塞避免模式。
算法的组合给出了 TCP 连接吞吐量,如图 10.6 中所示。特性是线性增加、乘性降低(AIMD,备注:当 TCP 发送端收到 ACK,并且没有检测到丢包事件时,拥塞窗口加 1;当 TCP 发送端检测到丢包事件后,拥塞窗口除以 2。)锯齿模式,在短时间间隔内吞吐量的变化较大。
图 10.6. TCP 发送码率的变化

实际上,TCP系统的稳定性关键在于快速调整吞吐量。乘数降低可以确保快速响应网络拥塞,防止拥塞崩溃事件发生。加性增加能够探测最大可能的吞吐量,从而更充分地利用网络资源。
已经有许多研究对TCP吞吐量的变化和竞争TCP流的行为进行了深入研究。这些研究表明,竞争流在平均情况下获得了大致相等的带宽份额,尽管由于吞吐量的波动,它们在瞬时的带宽分配上可能不公平。
TCP 中存在一种系统的不公平性:因为该算法响应反馈,所以往返时间较短的连接可以更快地返回反馈,效果更好。 因此,具有较长 RTT 的连接只能获得较低的平均份额。
对多媒体的影响
如第 2 章所述,通过分组网络进行语音和视频通信,大部分流量(超过95%)采用TCP作为传输协议。为了维持多媒体流与网络上其他流量的和平共处,多媒体流量也应采用与TCP协议一致公平的拥塞控制算法。
TCP能够在非常短时间内响应网络拥塞,会给RTT较小的链接分配略高的带宽。TCP发展过程中涉及多种拥塞控制变体,每个变体之间行为又有细微差异。这就给TCP定义公平性带来麻烦:公平性应用瞬时带宽还是长期平均带宽来衡量? 大RTT链接获得带宽低于小RTT链接是否成问题?如何看待影响某些特定条件下TCP行为的协议变更?
研究越深入,TCP 不完全公平这一点就越明显。在短期内,一个流总是会战胜另一个流。从长期来看,这种不平衡又是趋于平均的,但是有一种情况除外,就是具有较大RTT的连接通常有较低的平均吞吐量。TCP 的不同变体也有一定的影响,例如,SACK-TCP 在特定的丢包模式下会获得更好的吞吐量,从长期来看,相比其他TCP控制协议吞吐量最多可以相差 2 或 3 倍。
作为多媒体应用拥塞控制的设计者,TCP 多样性实际上使我们的工作变得更容易。我们不必担心对任何特定类型的 TCP 完全公平,因为 TCP 本身并不完全公平。我们必须实施某种形式的拥塞控制--以避免拥塞崩溃的危险--但只要这对 TCP 大约是公平的,这就是可以预期的最佳结果。
有些人认为,多媒体应用不需要对 TCP 公平,而且这种业务占用的带宽超过其份额是可以接受的。毕竟,多媒体流量有严格的时序要求,而不像更具弹性的 TCP 流。在某种程度上,这一论点是有价值的,但重要的是要理解这种不公平可能产生的问题。
例如,一个用户同时收听网络音频和浏览网页。在这种情况下,使音频流比TCP流更具侵略性是可以理解的,从而从网络下载中抢占带宽。结果就是,音乐不会出現跳帧,但网页响应速度会变慢。在许多情况下,这可能是期望的运行模式。类似地,用户通话期间发送邮件,更希望邮件传输速度降低,而不是音频通话中断。
但是,我们不能保证多媒体流量的优先级总是高于 TCP 通信。也许用户提交的网页是网上拍卖中的出价,或者是股票交易请求,这些操作的响应速度非常重要。在这种情况下,如果在线电台是TCP延迟变大,用户可能会不高兴。
如果你的应用需要比正常通信更高的优先级,则应将此要求通知网络,而不是由特定的传输协议暗示。这种通信允许网络根据可用容量和用户的偏好在允许或拒绝更高优先级之间做出智能选择。RSVP/Integrated Services 和 differential Services 等协议为此提供信令。在撰写本文时,对这些服务的支持非常有限;它们可以在一些专用网络上使用,但不能在公共Internet上使用。面向公共Internet的应用应考虑某种形式的 TCP 友好拥塞控制。
多媒体拥塞控制
在撰写本文时,还没有因特网上音频/视频流的拥塞控制标准。可以直接使用 TCP 拥塞控制标准,也可以模拟它,正如下一节“类 TCP 码率控制”中所讨论的,尽管模拟 TCP 在实践中存在各种问题。IETF 内部做一些定义一个 TCP 友好码率控制标准(参见标题为 TCP 友好码率控制的章节)的工作,该标准可能更适合单播多媒体应用。多播拥塞控制的最新技术还不太清楚,但是本章后面讨论的分层编码技术可能是最有希望的。
类 TCP 码率控制
音视频应用中最简单的拥塞控制技术是使用 TCP 或模拟 TCP 拥塞控制算法。
正如在第 2 章<分组网络上的语音和视频通信>中所讨论的那样,TCP 具有一些不适合实时应用的特性,尤其是强调可靠性而不是及时性。然而,一些多媒体应用也确实在使用 TCP,并且定义了一个 RTP over TCP 封装,以便与 RTSP(实时流协议)一起使用。
除了直接使用 TCP,还可以在没有可靠性机制的情况下模拟 TCP 的拥塞控制算法。 尽管尚无标准,但人们已经进行了多次尝试来实现这样的协议,其中最完整的是 Rejaie 等人的码率自适应协议(RAP)。 与 TCP 非常相似,RAP 源发送包含序列号的数据包,这些数据包被接收端确认。发送端可以使用来自接收端的确认反馈,检测丢包,来保持RTT在平均上是平滑的。
RAP 发送端使用加法递增乘法递减(AIMD)算法来调整其传输码率,其方式与 TCP 发送端几乎相同,尽管由于它是基于码率的,因此它显示出比 TCP 更平滑的变化。与 TCP 不同,RAP 中的拥塞控制与可靠性机制是分离的。当检测到丢包时,RAP 发送端必须降低其传输码率,但没有重新发送丢失的包的义务。实际上,最可能的响应是调整编解码器输出以匹配新的码率,并在不恢复丢包数据的情况下继续保存原有码率。
像 RAP 这样的协议,在某种程度上模拟 TCP 拥塞控制的行为,表现出了对现有流量最公平的行为。 与标准 TCP 相比,它们还为应用提供了更大的灵活性,从而使它能够以所需的任何顺序或格式发送数据,而不会因为 TCP 所提供的可靠的顺序传递而受阻。
使用 TCP 或类似 TCP 的协议的缺点是,应用必须快速调整其发送码率,以匹配 TCP 流量的调整码率。它还必须遵循 TCP 的 AIMD 模型,这意味着码率的突变。对于大多数音频/视频应用来说,这是个难题,因为很少有编解码器能够在如此大的范围内快速适应,而且人们发现图像或声音质量的快速变化会干扰观看者。
这些问题并不一定意味着 TCP 或类似 TCP 的行为不适合所有音频/视频应用,当我们只需要关注其适用性。这些拥塞控制算法的主要问题是隐含的码率快速变化。在某种程度上,你可以通过缓冲输出、隐藏码率的短期变化并将平滑的平均码率反馈给编解码器,使应用不受这些更改的影响。这对于非交互应用可以很好地工作,这些应用可以容忍缓冲所隐含的端到端延迟的增加,但不适合交互使用。
正在进行的协议研究将类似 TCP 的拥塞控制与不可靠的传输结合起来。如果发现其中一个适合与 RTP 一起使用,则可以扩展 RTP 以支持必要的反馈(例如,使用第 9 章“纠错”中描述的 RTCP 扩展)。设计合适的拥塞控制算法仍然是一个难点。
在撰写本文时,这些新协议都不完整。希望使用类似 TCP 的拥塞控制的应用可能最适合直接使用 TCP。
TCP 友好码率控制
TCP 或类 TCP 的拥塞控制不适合交互式音频/视频传输的主要问题是:在短时间内的剧烈码率变化。许多音频编解码器是非自适应的,并且以单一固定码率(例如,GSM,G.711)工作,或者只能在固定码率集(例如,AMR)之间进行自适应。视频编解码器通常具有更大的码率适应范围,因为帧速率和压缩比都可以调整,但它们适应的码率通常较低。即使媒体编解码器能够快速适应,也不清楚这样做是否一定合适:研究表明,用户更喜欢稳定的质量,即使可变质量流具有更高的平均质量。
设计了各种 TCP 友好的码率控制算法,试图平滑发送码率的短期变化,从而使算法更适合音频/视频应用。这些算法在几秒的平均间隔内实现 TCP 的公平性,但在短期内可能不公平。它们在单播音频/视频应用中具有相当大的潜力,IETF 正在定义一种标准机制。
TCP 友好的码率控制是基于对由 Padhye 等人导出的 TCP 稳态响应函数的仿真。响应函数是 TCP 连接吞吐量的数学模型,是给定网络丢包率和往返时间的平均吞吐量的预测。响应函数的推导有点复杂,但 Padhye 已经表明,在稳定条件下,TCP 连接的平均吞吐量 T 可以通过以下方式建模:

在这个公式中,s 是以八位元为单位的数据包大小,R 是发送端和接收端之间的往返时间(以秒为单位),p 是丢包事件率(与丢失数据包的分数不完全相同;参见下面的讨论),而 Trto是 TCP 重传超时时间(以秒为单位)。
这个方程看起来很复杂,但参数的测量相对简单。基于 RTP 的应用知道其发送的数据包的大小,可以从 RTCP SR 和 RR 包中的信息获得往返时间,并且在 RTCP RR 包中报告丢包事件率的近似。这只剩下 TCP 重传超时,Trto,令人满意的近似是往返时间的四倍,Trto= 4R。
在测量了这些参数之后,发送端可以计算在稳定状态下,即在假定丢包率恒定的情况下,TCP 连接在类似网络路径上将达到的平均吞吐量(在几秒钟内的平均)。然后,这些数据可以用作拥塞控制方案的一部分。如果应用以高于 TCP 计算出的码率发送,则应降低传输码率以匹配计算值,否则可能会造成网络拥塞。如果它以较低的码率发送,它可以增加其码率以匹配 TCP 将达到的码率。应用运行一个反馈回路:改变传输码率、测量丢包事件码率、改变传输码率匹配、测量丢包事件码率,重复。对于使用 RTP 的应用,这个反馈循环可以由 RTCP 接收报告包的到达来驱动。这些报告导致应用重新评估并可能更改其发送码率,这将在下一个接收报告中测量效果。
例如,如果报告的往返时间为 100 毫秒,则应用正在发送带有 20 毫秒数据包(s = 200,包括 RTP / UDP / IP 标头)的 PCM µ-law 音频,丢包事件率为 1% (p = 0.01),TCP 等效吞吐量将为 T = 22,466 个八位位组每秒(21.9 Kbps)。
因为这低于 64kbit PCM 音频流的实际数据码率,所以发送端知道这引起了拥塞,因此必须降低其传输码率。 它可以通过切换到较低码率的编解码器(例如 GSM)来实现。 这似乎是一件简单的事情,但在实践中有一些问题需要解决。最关键的问题是如何测量平均丢包率,但在包大小、慢启动和非连续传输方面存在相对没那么关键的问题:
-
最重要的问题是计算要反馈给发送端的丢包事件率的算法。RTP 应用不直接测量丢包事件率,而是计算每个 RTCP 报告间隔中丢包的数量,并将该数量包含在 RTCP 接收报告包中作为丢包部分。对于 TCP 友好的码率控制算法来说,这是否是正确的度量还不清楚。
丢包率可能不是一个足够的度量,原因有二:首先,TCP 主要响应丢包事件,而不是实际丢失的数据包数量,大多数实现仅对一次往返时间内任何数量的丢包的响应定为将其拥塞窗口减半。将往返时间内连续丢失的多个数据包视为单个事件的丢包事件的度量,而不是将单个丢失的数据包计算在内,以与 TCP 更平等地竞争。丢包事件率可以通过 RTCP 接收端报告的扩展来报告,但目前还没有标准的解决方案。
第二个原因是,在任何特定时间间隔内报告的丢包率不一定是潜在丢包率的反映,因为丢包率可能会因不具代表性的丢包突发而突然变化。这是一个问题,因为如果发送端使用丢包分数直接计算其发送码率,可能会导致振荡行为。在某种程度上,这种行为是不可避免的,AIMD 算法本身是振荡的,但振荡应该尽可能减少。
用于减少振荡的解决方案是在特定时间段内的平均丢包报告,但是研究人员对正确的平均算法没有明确的共识。SiSalem 和 Schulzrinne 建议使用指数加权移动平均丢包分数,其优于原始丢包率,但在某些情况下仍可引起振荡。Handley 等人建议使用丢包事件率的加权平均值,修改以排除最近的丢包事件,除非这将增加平均丢包事件率。该修改的加权平均值防止了孤立的、无代表性的丢包破坏了丢包估计,并因此减少了振荡的机会。
虽然它不是最优的,但使用 RTCP 接收报告中所报告的丢包分数的指数加权移动平均来近似丢包事件率可能是足够的。其目标不是对 TCP 连接完全公平,而是在某种程度上公平,不造成拥塞,并且仍然可以用于音频/视频应用。一个更完整的实现将扩展 RTCP 接收报告,以直接返回丢包事件率。
-
TCP 友好的码率控制算法假设包大小 s 是固定的,而传输码率 R 是可变的。固定的 s 和可变的 R 在某些编解码器中很容易实现,但在其他编解码器中很难实现。编解码器变化对公平性的影响是一个正在进行的研究课题,它会影响包的大小和码率。
同样,应用可能正在使用具有有限适应范围的编解码器,并且可能无法以 TCP 友好算法指定的码率发送。安全的解决方案是以下一个可能较低的码率发送;如果不可能降低码率,则可能必须停止传输。
-
如前所述,TCP 在开始传输时实现一个慢启动算法。这种缓慢的启动允许发送端以渐进的方式探测网络容量,而不是从可能导致拥塞的突发开始。慢启动对于 TCP 来说实现起来很简单,因为在发生丢包时会有立即的反馈,但是对于以较长时间间隔发送反馈的基于码率的协议来说则更为困难。
适用于 TCP 友好码率控制的解决方案是,在慢启动期间,接收端每往返一次就对接收码率发送反馈。发送端以低码率启动(建议每秒一个包),每次反馈包到达时将其传输码率加倍,直到检测到第一个丢失。丢包发生后,系统开始正常运行,从丢包发生前使用的码率开始。这会逐渐增加到一个“合理”的值,此时码率控制算法将接管该值。
该解决方案适合于与 RTP 一起使用,其中接收端根据扩展的 RTCP 反馈配置文件发送确认(参见第 9 章《错误恢复》以及 OTT 等人 2003),并且发送端每往返时间将其码率加倍,直到发生丢包为止。然后,接收端回复到正常的 RTCP 操作,发送端遵循 TCP 友好的码率。
一些应用可能无法执行此倍率算法,因为它们支持的编解码器集受到限制。此类应用可能会考虑先发送虚拟数据,然后在知道可持续传输码率后切换到最合适的编解码器。
-
最后一个问题是不连续传输。如果源停止发送一段时间,则不会收到有关正确码率的反馈。在暂停期间,可用容量可能会发生变化,可能是因为启动了另一个源,所以当发送端恢复时,上次使用的传输码率可能不合适。对于这个问题,除了可能从零开始或从另一个慢启动算法降低的码率开始,直到确定正确的码率为止,几乎没有办法解决这个问题。
如果能够解决这些问题,TCP 友好的码率控制就有可能成为单播音频/视频应用拥塞控制的标准方法。强烈建议所有单播 RTP 实现包括某种形式的 TCP 友好拥塞控制。
实现至少应该观察 RTCP RR 包报告的丢包率,并将其发送码率与从该丢包率导出的 TCP 友好码率进行比较。如果实现发现其发送速度明显快于 TCP 友好码率,则应切换到较低码率的编解码器,或者在无法实现较低码率的情况下停止传输。这些措施可防止拥塞崩溃,并确保网络正常运行。
实现 TCP 友好的码率控制算法将使应用优化其传输以匹配网络,给用户最好的质量。在此过程中,它还将公平对待其他流量,以免干扰用户正在运行的其他应用。如果应用有一个合适的编解码器或一组编解码器,强烈建议不仅使用码率控制来降低网络拥塞时的码率,而且要允许应用在网络负载较少时提高其质量。
分层编码
多播大大增加了拥塞控制的难度:发送端需要调整其传输以同时适应多个接收端,这个要求乍一看似乎是不可能的。多播的优点是,它允许发送端有效地向一组接收端传输相同的数据,而拥塞控制要求每个接收端获得适应其特定网络环境的媒体流。这两个要求似乎从根本上是互相矛盾的。
解决方案来自分层编码,在分层编码中,发送端将其传输分成多个多播组,而接收端只加入可用组的一个子集。拥塞控制的负担从无法满足每个接收端的冲突需求的源头转移到能够适应其具体情况的接收端身上。
分层编码需要一个媒体编解码器,能够将一个信号编码成多个层,这些层可以增量组合以提供逐渐提高的质量。一个只接收基本层的接收端将得到一个低保真度信号,一个接收基本层和一个附加层的接收端将得到更高的质量,每个附加层增加接收信号的保真度。除了基本层之外,层本身是不可用的:它们只是细化由较低层之和提供的信号。
分层编码的最简单用法是给每个接收端一个或多个层的静态订阅。例如,发送端可以生成如图 10.7 所示排列的层,其中基本层对应于 14.4-Kbps 调制解调器的容量,基本层和第一增强层的组合匹配于 28.8-Kbps 调制解调器的容量,基本层和前两个增强层的组合匹配于 33.6-Kbps 调制解调器,等等。每一层都是在一个单独的多播组上发送的,接收端加入适当的组集合,以便他们只接收感兴趣的层。网络中支持多播的路由器确保流量仅在指向感兴趣的接收端的链路上流动,从而将适应的负担放在接收端和网络上。
图 10.7. 分层编码

相关解决方案涉及使用 simulcast,其中发送端生成适合于不同码率的多个完整媒体流,接收端加入单个最适当的组。此解决方案在发送端使用了更多的带宽-可能的码率的和,而不是最高的可能码率,但实现更简单。它不能解决瞬时拥塞引起的问题,但对码率选择问题提供了良好的解决方案。
虽然层的静态分配通过调整媒体流以服务于多个接收端来解决码率选择问题,但它不响应由于交叉业务引起的瞬时拥塞。不过,很明显,允许接收端根据拥塞情况动态更改其层订阅可能为多播拥塞控制提供了一种解决方案。基本思想是让每个接收端运行一个简单的控制回路:
-
如果出现拥挤,则丢弃一层或多层。
-
如果有备用容量,则添加一层。
如果适当地选择了层,则接收端将搜索最优的层订阅,以与 TCP 源在慢启动阶段探测网络容量相同的方式更改其接收带宽。接收端连接层直到观察到拥塞,然后返回到较低的订阅级别。
要驱动自适应,接收端必须确定它们的订阅级别是太高还是太低。很容易检测到超额订阅,因为会发生拥塞,并且接收端会看到数据包丢失。订阅不足很难检测,因为没有信号表明网络可以支持更高的码率。相反,接收端必须尝试加入一个附加层,如果该层导致拥塞,则必须立即丢弃该层,这是一个称为连接实验的过程,结果如图 10.8 所示,订阅级别订阅级别根据网络拥塞而变化。
图 10.8. 通过改变订阅级别进行适配

加入实验的困难在于试图实现共享学习。 考虑图 10.9 所示的网络,其中接收端 R1 执行加入实验,但 R2 和 R3 不执行。 如果源和 R1 之间的瓶颈链接是链接 A,则一切将正常工作。 但是,如果瓶颈是链接 B,则 R1 执行的连接实验将导致 R2 和 R3 出现拥塞,因为它们共享瓶颈链接的容量。 如果 R2 和 R3 不知道 R1 正在执行连接实验,则将拥塞视为丢弃层的信号-这不是期望的结果!
图 10.9. 加入实验的难点

还有第二个问题。如果链路 C 是瓶颈,而 R2 丢弃一层,则除非 R3 也丢弃一层,否则通过瓶颈的流量不会受到影响。因为 R2 仍然看到拥塞,它将丢弃另一层,这个过程将重复,直到 R2 厌恶地离开会话,或者 R3 也丢弃一层。
解决这两个问题的方法是同步接收端连接实验。如果每个接收端通知所有其他接收端它将加入或丢弃一个层,则可以实现此同步,但这样的通知很难实现。一个更好的解决方案是,发送端在数据流中包含同步点(特别标记的数据包),告知接收端何时执行连接实验。
其他问题与多播路由的操作有关。尽管多播连接速度很快,但处理丢弃请求通常需要一些时间。接收端必须留出处理丢弃请求的时间,然后才能将拥塞的持续存在视为丢弃附加层的信号。此外,快速连接或丢弃会导致大量的路由控制通信量,这可能是有问题的。
如果这些问题能够得到解决,并且为每一层选择适当的带宽,就有可能通过分层编码来实现 TCP 友好的拥塞控制。将这种拥塞控制应用于音频/视频应用的困难在于找到一种能够生成具有适当带宽的累积层的编解码器。
分层编码是最有前途的多播拥塞控制方案,它允许每个接收端选择合适的码率,而不必给发送端增加负担。IETF 中的可靠多播传输工作组正在开发一个分层拥塞控制标准,这项工作很可能将成为未来多播音频/视频拥塞控制标准的基础。
总结
拥塞控制是必要的。作为一个应用设计人员,如果忽略拥塞控制,可能会导致你的应用看起来运行的更好,但却可能对网络上的其他流量产生负面影响,甚至影响你自己应用的其他实例。因此,为了避免拥塞崩溃的风险,应用程序应该实现某种形式的拥塞控制。同时,我们希望所选择的算法能够近似公平地处理TCP流量,并允许以控制的方式在网络中引入不公平的优先级。
拥塞控制的标准仍在发展中,因此很难为实现者提供详细的规范。尽管如此,强烈建议单播应用实现一个TCP友好的码率控制算法,这些算法算是最佳开发实践。对于多播应用,拥塞控制的选择不太明确,但目前分层编码似乎是最佳选择。
第十一章. 包头压缩
- 初步概念
- 压缩 RTP
- 包头压缩健壮性
- RTP 应用注意事项
包头大小是 RTP 经常被批评的一个方面。有人认为 12 字节的 RTP 头加上 28 字节的 UDP/IPv4 头对于一个只有 14 个字节的音频数据包来说过于冗余,且认为应该使用一个更高效的压缩的头。某种程度上说这是对的,但是这个论点忽略了在某种情况下使用 RTP 的完整包头的必要性,并且忽略了单一开放的音视频传输标准对于社区的好处。
包头压缩在这两个论点之间取得了平衡:当应用于链路层时,它可以将整个40字节的RTP/UDP/IP头部压缩为2个字节,比UDP/IP上的专有协议更高效,同时又享受单一标准的好处。本章介绍了头部压缩的原理,并详细介绍了两种压缩标准:压缩RTP(CRTP)和鲁棒头部压缩(ROHC)。
初步概念
包头压缩技术的使用在 Internet 社区已有悠久的历史,自 1990 年 TCP/IP 包头压缩便被用于拨号网络的 PPP 协议广泛应用。而最近,TCP/IP 包头压缩标准已经被修订更新,并且 UDP/IP 和 RTP/UDP/IP 等包头压缩的新标准也已经被开发出来。
头部压缩的典型场景包括通过低速拨号调制解调器或无线链路连接到网络的主机。在这种情况下,主机和第一跳路由器会对通过低速链路传输的数据包进行压缩,提高该链路上的效率,而不会影响网络的其他部分。在大多数情况下,都会有一个特定的瓶颈链路,希望能更有效地利用带宽,而在网络的其他部分则不需要进行压缩。头部压缩在每个链路上透明地工作,非常适合这种场景。压缩后的链路看起来与其他IP链路没有区别,应用程序无法察觉到头部压缩的存在。
这些特点——每个链路的操作和应用程序的透明性——意味着头部压缩通常作为操作系统的一部分实现,通常作为PPP(点对点协议)实现的一部分。在大多数情况下,应用程序不需要意识到头部压缩的存在。然而,在某些情况下,考虑头部压缩的行为可以显着提高性能。这些情况将在本章后面的“RTP应用程序的考虑事项”部分进行讨论。
模式,稳定性和本地实现
压缩依赖于包头模式:许多字段是恒定的,或者在属于同一包流的连续包之间以可预测的方式变化。如果我们能够识别这些模式,我们可以将这些字段压缩为"头以期望的方式改变"的指征,而不是显式地发送它们。只有以不可预测的方式变化的头字段需要在每个头中传输。
在包头压缩标准的设计过程中一个重要的原则就是稳定性。主要体现在两方面:丢包稳定性和误识别流的稳定性。网络链接(尤其是无线链接)可能会丢失或破坏数据包,所以包头压缩方案必须能够在存在此类损坏的情况下起作用。最重要的要求是压缩比特流的损坏不会在未压缩的数据流中引发不可检测的损坏。如果数据包损坏,后续的数据包要能够被正确解码或丢弃。解码器绝不应该产生损坏的数据包。
第二个稳定性问题是 RTP 流无法自我识别。UDP 包头中没有字段能够分辨当前正在传输的是 RTP 流,并且编码器无法明确确定 UDP 数据包的特定序列包含 RTP 流量。编码器需要显式的被告知一个数据流中包括 RTP,或者需要它能够基于对数据包序列的观测来进行有依据的猜测。稳定性工程设计要求 如果错误的将其用于非 RTP 流,则压缩不得破坏任何内容。被误导的编码器预期不应压缩其他类型的 UDP 流,但是底线是一定不能破坏它们。
模式识别和稳定性原则结合在一起,形成了包头压缩的一般性原则:编码器间歇发送包含完整头部的数据包,然后进行增量更新,指征哪些头部字段以预期的方式进行更改,哪些头部字段中包含随机的无法被压缩的字段。完整的包头提供了稳定性:对增量包的破坏可能会导致解码器混淆并阻止操作,但是当下一个完整的包头到达时将会得到纠正。
最后,本地包头压缩非常重要。其目的是开发一种可在单个链路上运行而无需端到端支持的包头压缩方案:如果节省带宽很重要,两个系统可以花费一个CPU周期来压缩;否则如果处理成本太高,那么就发送未压缩的包头。如果两个系统决定压缩单个链接上的包头,应该能够让链路上其他系统都不可见的方式做到这一点。因此,包头压缩应该在网络协议栈而非应用 程序中实现。应用程序不需要自己实现包头压缩;应用程序设计人员应该了解包头压缩及其影响,应将其作为链接两端机器的协议栈的一部分来实现。
标准
RTP 包头压缩有两种标准。原始的压缩 RTP(CRTP)规范设计用于拨号调制解调器,是 TCP 包头压缩的直接扩展,可用于 RTP/UDP/IP。然而,随着以 IP 电话为载体的第三代蜂窝技术的发展,人们发现 CRTP 在高延迟和丢包的环境下表现不佳,因此开发了一种替代协议——健壮报头压缩(ROHC)。
CRTP 仍然是拨号使用的首选协议,因为它在该环境中具有简单性和良好的性能。 ROHC 相对复杂,但在无线环境中的性能要好得多。下面几节将详细讨论每个标准。
压缩 RTP(CRTP)
CRTP 的标准在 RFC 2508 中指定。CRTP是为低速串行链路设计的,比如拨号调制解调器,其误码率很低。CRTP 是 Van Jacobson 的 TCP 包头压缩算法的直接产物,与其具有相似的性能和局限性。
TCP 包头压缩主要收益来自于观察到 TCP/IP 包头中一半的字节在数据包之间是恒定不变的。这些信息在完整的包头数据包中只发送一次,然后从之后的数据包中删除。剩余的增益来自对变化的字段进行差分编码,减小其大小,以及通过在通常情况下计算数据包长度的变化来完全消除变化的字段。
RTP 包头压缩使用了很多相同的技术,观察表明,尽管每个数据包中有多个字段更改,但数据包和数据包之间的差异通常是恒定的,因此二阶差分为零。恒定的二阶差分使编码器能够抑制(suppress)不变的字段以及各个包之间可预测变化的字段。
图 11.1 展示了该流程。阴影部分的包头字段在数据包之间是常量,它们的一阶差分为 0,不需要发送。未着色部分字段是变化的字段;它们的一阶差分非 0。然而,它们的二阶差分通常是常数 0,这使得变化字段是可预测的。
图 11.1. 包头压缩原理

在图 11.1 中,除了 M 以外的所有字段要么恒定不变,要么其二阶差分为 0。因此,如果已知可预测字段的初始值,只需要发送 M 字段的更改。
CRTP 的运作:初始化和上下文
压缩 RTP 首先发送一个包含完整包头的初始数据包,从而在编码器和解码器之间建立相同的状态。此状态作为压缩数据流的初始上下文。后续数据包包含被缩减的包头,这些包头指示解码器使用存在的上下文来对其进行预测,或者包含必须用于后续数据包的更新。可以定期发送包含完整包头的数据包,以确保纠正编码器和解码器之间任何的同步丢失。
完整包头数据包包括未经压缩的原始数据包,以及两个附加信息(上下文标识符和序列号),如图 11.2 所示。上下文标识符占 8 或 16bit,唯一标识特定的流。序列号占 4 位,用于检测链路丢包。这些附加信息替换了原始数据包中的 IP 和 UDP 长度字段,而不会丢失数据,因为该长度字段对于链路层帧长度是多余的。完整包头格式在一些压缩方案中很常见,包括 IPv4 和 IPv6、TCP 和 UDP 包头。
图 11.2 完整包头中的附加信息

链路层协议向传输层表明这是一个 CRTP(而不是 IP)完整的包头包。此信息允许传输层将数据包路由到 CRTP 解码器,而不是将它们视为通常的 IP 数据包。链路层提供这种指示的方式取决于所使用的链路的类型。在RFC 2509中指定了对 PPP 链路的操作。
上下文标识符由编码器管理,每当它看到新的数据流,认为可以压缩的时,就会生产新上下文。在接收到新的上下文标识符后,解码器将为上下文分配存储空间。否则,它将上下文标识符作为存储上下文状态的状态表的索引。上下文标识符不需要顺序分配。当上下文较少时,应使用哈希表来减少状态所需的存储空间,当上下文较多时,应仅使用具有上下文标识符作为索引的数组。
上下文包含以下状态信息,这些信息将在收到完整的包头包时进行初始化:
- 传送的最后一个数据包的完整 IP,UDP 和 RTP 包头,可能包括 CSRC 列表
- 当接收到一个完整的包头时,将会把 IPv4 的 ID 字段的一阶差分初始化为 1。(当 RTP-over-UDP/IPv6 被压缩时,不需要此信息,因为 IPv6 没有 ID 字段)
- 当接收到一个完整的包头时,RTP 的 timestamp 字段 的一阶差分初始化为 0。
- CRTP 序列号(4bit)的最后一个值,用于检测压缩链路丢包。
有了这些上下文信息,接收端就可以解码收到的每个连续数据包。尽管可能需要使用每个数据包更新存储在上下文中的状态,但不再需要额外的其他状态。
CRTP 的运作:编码和解码
在发送完整的包头以建立上下文之后,可能会发生向压缩 RTP 数据包的过渡。解码器可以根据存储的上下文以及收到的压缩 RTP 数据包,来预测下一个数据包的包头。压缩的 RTP 数据包可能会更新该上下文,从而允许在不发送完整包头的情况下传达包头中的常见更改。压缩 RTP 数据包的格式如图 11.3 所示。在大多数情况下,仅存在具有实线轮廓的字段,这种情况下可以直接从上下文预测下一个包头。可以根据需要提供其他字段以更新上下文,也可以从上下文推断出它们的存在,或者直接在压缩包头中被示意。
图 11.3 一个压缩 RTP 数据包

编码器观察数据流的特点,并且忽略那些恒定不变或以可预测方式变化的字段。压缩算法会对任何可以通过预测得到的 IPv4 ID,RTP 序号,以及 RTP 时间戳字段 起作用。通常,编码器无法知道特定流是否真的是 RTP。它必须在包头中查找模式,如果存在特定模式,则开始压缩。如果该流不是 RTP,则不太可能存在这种特定模式,那它将不会被压缩(当然,如果流不是 RTP,但具有适当的模式,则对其进行压缩)。编码器预期会保持状态以跟踪哪些流是可压缩的,哪些流不是,以此来避免浪费压缩工作。
一旦接收到压缩 RTP 包,解码器就会重建包头。可以通过获取先前存储在上下文中的包头来重建 IPv4 包头,并从链路层包头中推断出校验和的值和总长度字段。如果在压缩 RTP 数据包中设置了 I 或 I` 位,则 IPv4 ID 将增加压缩 RTP 数据包中的 Delta IPv4 ID 字段的值,并更新上下文中存储的 IPv4 ID 的一阶差分。否则 IPv4 ID 会增加上下文中存储的一阶差分。
如果上下文中存在多个 IPv4 包头(例如,IP-in-IP 隧道的原因),将从压缩 RTP 数据包中恢复其 IPv4 ID 字段,并按顺序将它们存储为“随机”字段。如果使用 IPv6,则没有数据包 ID 和校验和字段,因此除负载长度(可从链路层长度推断出来)以外,所有字段都是恒定不变的。
你可以通过获取之前存储在上下文中的包头并从链路层包头中推断长度字段来重新构造 UDP 包头。如果上下文中存储的校验和为零,则假定不使用 UDP 校验和。否则,压缩的 RTP 包将包含校验和的新值。
你可以通过采用先前存储在上下文中的报头来重构 RTP 包头,按如下所述进行修改:
- 如果所有 M,S,T 和 I 都为 1,则数据包包含 CC 字段和 CSRC 列表以及 M‘,S’,T‘,I’。在这种情况下,M,S,T,I 字段用于预测标记位,序列号,时间戳和 IPv4 ID。CC 字段和 CSRC 列表基于压缩的 RTP 包被更新。否则,CC 和 CSRC 列表将基于先前的数据包进行重建。
- M 位被压缩 RTP 包中的 M(或 M’)位所代替。
- 如果压缩 RTP 包中的 S 或 S‘位为 1,则 RTP 序列号将增加由压缩 RTP 包中的 delta RTP sequence 指示的值。否则 RTP 序列号自增 1。
- 如果压缩 RTP 包中设置了 T 或 T’位,则将 RTP 时间戳增加压缩 RTP 数据包中的 delta RTP timestamp 字段指示的值,并更新上下文中存储的时间戳的一阶差分值。否则,RTP 时间戳会根据上下文中存储的一阶差分值递增。
- 如果上下文中设置了 X 位,将从压缩 RTP 中恢复 header extension 字段。
- 如果上下文中设置了 P 位,将从压缩 RTP 中恢复 padding 字段。
上下文以及任何对 IPv4 ID,RTP 时间戳 的一阶差分和链路层序列号的更新将使用新接收到的包头来进行更新。然后,将重构的包头和负载数据传递到 IP 栈,以常规方式进行处理。
通常只有上下文标识符,链路层序列号,M,S,T 和 I 字段存在,通常是 2 个八位组(如果使用 16bit 上下文标识符,则为 3 个八位组)。这比 40 个八位组的未压缩包头好很多。
丢包的影响
RTP 接收端通过 RTP 序列号的不连续来检测丢包,丢包是RTP 时间戳也可能跳跃。当丢包发生在编码器的上游时,新的 delta 值被发送到解码器来传达这些不连续。虽然压缩效率降低了,但数据包流仍在链路上准确通信。
同样的,如果丢包发生在压缩链路,会通过压缩 RTP 数据包中的链路层序列号来检测到丢包。然后,解码器将会发送一个消息给编码器,指示其应该发送一个完整包头数据包来修复状态。如果存在 UDP 校验和,解码器还可能尝试应用两次存储在上下文中的增量,来验证这样做是否生成了正确的数据包。只有当存在 UDP 校验和时,才可以使用两次算法。否则,解码器将无法知道恢复的数据是否正确。
当丢包发生时,需要请求一个完整的包头数据包来恢复上下文信息,这使得 CRTP 极易受到压缩链路上丢包的影响。特别是,如果链路的往返时间(RTT)较长,在传递上下文恢复请求期间可能会收到许多数据包。造成的影响如图 11.4 所示,结果是丢包倍增,其中单个数据包的丢失会影响到多个包,直到传递完整的包头数据包为止。因此,数据包丢失会严重影响 CRTP 的性能。
图 11.4 CRTP 面对丢包时的处理

CRTP 的另一个限制因素是数据包重排序。如果数据包在压缩链路之前进行重排序,则需要编码器发送包含序列号和时间戳更新的数据包以进行补偿。这些数据包相对较大(通常在两到四个八位组之间),对压缩率有显著影响,至少使压缩包头增大了一倍。
基本的 CRTP 是假设压缩链路上没有重新排序的。为了使 CRTP 在面对丢包和重新排序时更健壮,目前正在进行扩展工作。预计这些增强将使 CRTP 适用于在压缩链路上有少量或中等丢包或重新排序的环境。下一节讲述的稳定性包头压缩(ROHC)方案是针对更极端的环境设计的。
稳定性包头压缩(Robust Header Compression)
如之前所述,CRTP 在丢包和往返时间(RTT)较长的链路(例如许多蜂窝无线网络)上不能很好的工作。每个丢失的数据包都会导致后续多个数据包的丢失,因为上下文信息至少在一个链路往返时间不同步。
丢失多个数据包除了会降低媒体流的质量外,还会浪费带宽,因为已经发送的一些数据包被简单的丢弃了,并且必须发送一个完整包头数据包来刷新上下文。稳定性包头压缩(ROHC)旨在解决这些问题,提供适用于第三代蜂窝系统的压缩功能。在这些链路上,ROHC 相对于 CRTP 具有显著的性能提升,但代价是实现相对复杂。
观察媒体流包头字段的变化,可以发现这些字段分为三类:
- 有些字段或者大部分字段都是静态不变的。比如 RTP,SSRC,UDP 端口号和 IP 地址。这些字段在连接建立时发送一次,它们或者从不改变,或者变化不频繁。
- 有些字段随着数据包的发送以可预测的方式变化,但偶尔会突然变化。比如 RTP 时间戳,序列号,以及 IPv4 ID 字段。在这些字段可预测期间,它们通常有一个恒定的关系。当突然变化时,通常只有一个字段发生了不可预期的变化。
- 有些字段是不可预测的,基本上是随机的,必须按原样进行通信,不能进行压缩。主要是 UDP 校验和。
ROHC 通过在 RTP 序列号和其他可预测字段之间建立映射函数(mapping functions)进行操作,然后可靠的传输 RTP 序列号和不可预测的包头字段。这些静态函数与在启动或当这些字段更改时传递的静态字段一起构成了压缩上下文的一部分。
ROHC 和 CRTP 的主要差别在它们处理第二类字段(通常以可预测的方式变化的字段)的方式。在 CRTP 中,字段的值是隐式的,并且数据包中包含一个指示,表明它以可预测的方式更改。在 ROHC 中,单个关键字段的值(RTP 序列号)明确包含在所有数据包中,并且使用隐式映射函数推导出其他字段。
ROHC 的运作:状态和模式
ROHC 具有三种运行状态,具体取决于传输的上下文量:
- 系统以初始化和刷新状态启动,非常类似于 CRTP 的完整包头模式。 此状态传达了建立上下文的必要信息,使系统能够进入一阶或二阶压缩状态。
- 一阶压缩状态使系统有效地传播媒体流中的不规范信息(上下文的变化),同时仍然保持很高的压缩效率。在这种状态下,只传输 RTP 序列号的压缩表示以及上下文标识符和更改字段的简化表示。
- 当根据 RTP 序列号和存储的上下文可以预测整个包头时,二阶状态是最高的压缩级别。包中只包含 RTP 序列号的压缩表示(可能是隐式的)和上下文标识符,给出的包头可以小到只有一个八位组。
如果存在任何不可预测的字段(如 UDP 校验和),则一阶和二阶压缩方案都会不变的传递这些字段。如预期那样,造成的结果是压缩效率显著降低。为了简单起见,这个描述省略了对它们的进一步提及,尽管它们总会被传递。
编码器开始于初始化和刷新状态,将完整的包头信息发送给解码器。当确认解码器正确的接收到足够的信息来设置上下文之后,它将移动到一阶或二阶状态,发送压缩后的包头。
系统可以以三种模式之一运行:单向,双向乐观(bidirectional optimistic),双向可靠(bidirectional reliable)。根据选择的模式,编码器将根据超时或确认从初始化和刷新状态转换到一阶或二阶压缩状态:
- 单向模式。有可能没有反馈,编码器会在发送预定数量的数据包之后,转换到一阶或二阶状态。
- 双向乐观模式。与单向模式一样,编码器在发送了预定数量的数据包之后,或收到确认时将转换为一阶或二阶状态。
- 双向可靠模式。编码器在收到确认后转换为一阶或二阶状态。
单向或双向反馈模式的选择取决于编码器和解码器之间链路的特性。一些网络链路可能不支持(对其不友好)反馈消息的反向通道,从而迫使运行于单向模式。但是,在大多数情况下,可以使用双向模式之一,从而使接收端可以将其状态传达给发送端。
编码器以单向模式启动。如果链路支持,解码器将根据链路的丢失模式(loss pattern)选择是否发送反馈。如果编码器接收到反馈消息,就会认为解码器期望使用双向模式。解码器根据反向通道的容量和链路的丢包率在乐观和可靠模式之间选择。可靠模块需要发送更多的反馈信息,但容错性更高。
保持 ROHC 状态和模式之间的区别是很重要的。状态决定了每个数据包中的信息类型:完整的包头,部分更新或完全压缩。模式确定解码器发送反馈的方式和时间:(1)从不,(2)当有问题发生时,(3)总是
通常,在建立上下文之后,系统会从初始化和刷新状态过渡到二阶状态。然后它将保持二阶状态,直到发生丢包,或由于流特性的变化而需要更新上下文。
发生丢包时,系统的行为取决于当前的工作模式。处于两种双向模式之一时,解码器会发送反馈信息,然后导致编码器进入一阶状态发送更新信息来修复上下文。这个过程对应于在 CRTP 中发送上下文刷新消息,从而导致编码器生成包含完整包头的数据包。处于单向模式时,编码器会定期转换到低阶状态,以刷新解码器中的上下文。
在需要对一个可预测字段的映射进行更改或对一个静态字段进行更新时,编码器也会转换到一阶状态。这个过程对应于在 CRTP 中发送包含更新的 delta 字段或完整包头的压缩包。根据操作模式的不同,一阶状态的更改有可能会导致编码器发送反馈信息,来表明它已经正确接收到新的上下文。
ROHC 的运作:稳定性和压缩效率
在压缩链路可靠的情形下,ROHC 和 CRTP 具有相似的压缩效率,而 ROHC 却更加复杂。因此,拨号调制解调器链路通常不适用 ROHC,因为 CRTP 复杂度较低,并能产生相似的性能。
在压缩链路上有丢包发生时,ROHC 的优势才会体现出来,体现在发送上下文更新信息时的灵活性和对压缩数据的稳定性编码。在 CRTP 必须发送完整包头以更新上下文的情况下,ROHC 仅需发送部分更新的上下文信息。当链路有丢包发生时,ROHC 也可以减小上下文更新信息的大小。这些特性使得 ROHC 相比于 CRTP 具有明显的性能提升。
压缩值的稳定性和序列号驱动操作的组合也是一个关键因素。如前所述,ROHC 上下文中包含了 RTP 序列号和其他可预测包头字段的映射。二阶压缩包使用基于窗口的最低有效位(W-LSB)编码来传递序列号,其他字段由此得出。W-LSB 编码的大量使用使得 ROHC 在应对丢包时提供了稳定性。
标准 LSB 编码传输字段值的 k 个最低有效位,而不是整个字段。在接收到这些 k bits 后,然后给定先前传输的值 Vref,解码器推导出该字段的原始值,前提是该值位于称为 可解释区间(interpretation interval) 的范围内。
可解释区间是 Vref 偏移参数 p 后,周围 2k 范围内的值,从 Vref - p 到 Vref + 2k -1 - p 。参数p 是基于初始化期间被传输并传送到解码器的字段的特性来选择的,从而构成上下文的一部分。可能的选择包括:
- 果字段的值期望被增加,则 p = -1。
- 如果字段的值期望被增加或保持不变,则 p = 0。
- 如果字段的值期望与固定值不同,则 p = 2(k-1) + 1。
- 如果字段的值期望经历小的负变化和大的正变化(如使用 B 帧的视频流的 RTP 时间戳),则 p = 2(k-2) - 1。
序列号传输示例。假定,最后传输的值 Vref = 984 ,k = 4(表示 4 个最低有效位作为编码格式传输)。假设 p = -1,计算出可解释区间为 985 到 1000,如图 11.5 所示。下一个发送的值是 985(二进制:1111011001)被编码为 9(二进制:1001,985 的 4 个最低有效位)。收到编码后的值后,解码器获取到 Vref,然后使用接收到的数据替换其 k 个最低有效位,来恢复原始值。
图 11.5 LSB 编码示例
只要需要编码的值在解释区间内,LSB 编码就能很好的工作。在前面的示例中,如果丢失了一个数据包,解码器收到的下一个值是 10(二进制:1010),还原后是 986,这是正确的。如果丢失了超过 2k 个数据包,解码器将无法知道要解码的正确值。
W-LSB 是基于窗口的 LSB 的变体,W-LSB 将可解释区间保持为滑动窗口,当编码器确定解码器收到特定值时,就会向前滑动。滑动窗口可以向前滑动的时机可以通过不同的方式触发:双向可靠(原文应有误)模式下,解码器发送 ack 时;双向乐观模式下,除非解码器发送一个否定的应答,否则窗口将每隔一定时间向前滑动;在单向模式下,窗口每隔一定时间就会向前滑动。
W-LSB 编码的优点是,窗口内少量数据的丢失不会导致解码器失去同步。这种稳定性使得 ROHC 解码器在遇到 CRTP 解码器发送故障并需要上下文更新的情况下可以无需请求反馈而继续运行。结果是,ROHC 比 CRTP 更不容易受到丢包倍增效应的影响:链路上一个数据包的丢失只会在 ROHC 解码器输出端引起单个丢失,而 CRTP 解码器必须经常等待一个上下文更新才能继续解码。
RTP 应用程序注意事项
RTP 包头压缩(无论是 CRTP 还是 ROHC)对应用程序来说都是透明的。当使用包头压缩时,对 RTP 数据包来说,压缩链路会成为一个更高效的管道,除了提高性能之外,应用程序无法知晓正在使用压缩。
然而,应用程序可以使用一些方法来帮助编码器更好的运行。主要方法是保证发送的数据包的规律性:发送的包时间戳增量有规律,且负载类型不变,就会产生压缩良好的 RTP 流,而多样的负载类型或包间间隔会降低压缩效率。数据包间时序变化的常见原因包括音频编解码器的静音抑制,反向预测视频帧以及视频交织(interleaving):
- 在静音期间抑制信息包的音频编解码器以两种方式影响包头压缩:设置标记位并导致时间戳跳变。这些变化导致 CRTP 发送包含更新的时间戳增量的包;ROHC 发送包含标记位和新时间戳映射的一阶数据包。任何一种方式都会导致压缩包头大小至少增加一个八位组。尽管包头压缩效率降低了,但由于有些数据包未被发送,静音抑制总是会节省带宽。
- 反向预测视频帧(如 MPEG B 帧)的时间戳比前帧的时间戳小。结果导致 CRTP 会发送多个更新,严重降低了压缩效率。对 ROHC 来说,尽管也会降低压缩效率,但并没有那么严重。
- 交织通常是在 RTP 有效负载中实现的,其格式设计为使 RTP 时间戳增量恒定不变。这种情况下,交织不会影响包头压缩,甚至可能是有益的。如 CRTP 在高延迟链路上运行时具有丢包倍增效应,与非交织流相比,交织流的问题较小。但是,在某些情况下,交织会导致具有带有非恒定偏移量的 RTP 时间戳的数据包。因此交织将降低压缩效率,最好避免。
UDP 校验和也会影响压缩效率。启用后,UDP 校验和必须与每个数据包一起传送。这会导致压缩包头额外增加两个八位组,而完全压缩的 RTP/UDP/IP 包头对于 CRTP 来说是两个八位组,对 ROHC 来说是一个八位组,所以影响是显著的。
这意味着,想要提高压缩效率,应用程序应该禁用校验和,但这可能是不合适的。禁用校验和可以提高压缩效率,但是可能会使流容易受到未检测的包损坏的影响(取决于链路层,一些链路包含校验和,从而使 UDP 检验和变的冗余)。应用程序设计人员必须确定提升压缩效率带来的好处是否超过接收到损坏数据包带来的影响。在有线网络中,位错误比较罕见,关闭校验和通常是安全的,而在无线网络上使用的应用程序可能希望启用检验和。
最后一个可能影响包头压缩的因素是 IPv4 ID 字段的生成。一些系统为每个发送的数据包的 IPv4 ID 字段递增 1,使压缩比较高效。其他系统使用 IPv4 值的伪随机序列,从而使得该序列不可预测,从而避免了某些安全问题。不可预测的 IPv4 ID 值的使用大大降低了压缩效率,因为每个数据包中的 IPv4 ID 字段需要两个八位组,而不是对其进行预测。
虽然认识到 IP 层通常不会知道数据包的内容,但还是建议 IP 实现发送 RTP 包时将 IPv4 ID 字段递增 1(可能需要提供一个函数调用来通知系统对特定的 socket,IPv4 ID 字段应该统一递增)。
总结
当 RTP 在低速网络上运行时,使用 RTP 包头压缩(无论时 CRTP 还是 ROHC)可以显著提高性能。当有效负载很小时(低速率的音频,数据包长度几十个字节),与 40 个字节的未压缩包头相比,具有 2 个字节的压缩包头的 CRTP 所获得的效率非常显著。ROHC 的使用在某些情况下会获得更好的收益,但会增加额外的复杂性。
包头压缩开始得到广泛使用。ROHC 是第三代蜂窝电话系统的重要组成部分,该系统使用 RTP 作为语音承载通道。CRTP 已在路由器中广泛实现,并开始在终端主机中部署。
第十二章 多路复用和隧道技术
- 多路复用的动机
- 隧道复用压缩 RTP
- 多路复用的其他方法
多路复用和隧道传输为包头压缩提供了一种替代方案,通过将多个流捆绑在一个传输连接中来提高 RTP 的效率。其目的是通过跨多个流来平摊头部的大小,减少每个流的开销。本章讨论了复用的动机,并概述了用于复用 RTP 流的机制。
多路复用的动机
包头压缩在逐跳的基础上减少单个 RTP 流的包头大小。虽然包头压缩提供了非常高效的传输,但是需要网络的协作(因为头压缩是逐跳进行的,而不是端到端的)。由于附加的计算和特定于流的状态,包头压缩增加了路由器上的负载,在必须同时支持数百甚至数千个 RTP 流的系统中,这两种情况都是不可接受的。
对网络内的计算和状态问题的传统解决方案是将复杂性推到边缘,简化网络的中心,但以边缘的额外复杂性为代价:端到端参数。这个解决方案的应用导表明:如果可能的话,应该减少端到端的包头。你可以通过端到端执行包头压缩来减少包头,从而减少每个包头的大小,或者通过在每个包中放置多个有效负载来减少包头的数量。
在整个端到端的通信中应用RTP头部压缩是可行的,但遗憾的是它并没有带来太大的好处。即使完全删除了RTP头部,UDP/IP头部仍然存在。因此,在典型的IPv4情况下仍然会有28个字节的开销,这显然是无法接受的,尤其是当负载是一个只有14个字节的音频帧时。因此,唯一可行的端到端解决方案是在每个数据包中放置多个负载,以分摊由UDP/IP头部引起的开销。
多个负载数据帧可以来自单个流或多个流,如图12.1所示。将来自单个流的多个负载数据帧放入每个RTP数据包中被称为“捆绑”。正如第4章中所解释的RTP数据传输协议,捆绑是RTP的固有特性,不需要任何特殊支持。它在减少头部开销方面非常有效,但会给媒体流带来额外的延迟,因为在所有捆绑的数据都准备好之前,无法发送数据包。
另一种方法是“多路复用”,即将来自不同流的多个负载数据帧放入一个数据包中进行传输。多路复用避免了捆绑所带来的延迟问题,并且在某些情况下可以显著提高效率。然而,多路复用也并非适用所有场景:
-
多路复用需要在多路复用点上出现许多具有相似特性的流。如果帧的到达时间不一致,多路复用设备将不得不延迟一些帧,等待其他帧的到达。如果帧的大小不可预测,多路复用设备将无法提前确定可以多路复用多少帧。这可能意味着在帧的大小完全不适合于多路复用时,会发送部分多路复用包。结果是传输效率低下和延迟不稳定这两个问题都没有解决。
-
为 IP 提出的 QoS 服务质量机制(区分服务和集成服务)在 IP 流的粒度上进行操作。多路复用在一个 IP 流中传输多个流,不可能给这些流提供不同的服务质量。这可能会限制多路复用在使用 QoS 的环境中的有效性,因为多路复用要求所有流具有相同的 QoS。另一方面,如果多路流需要相同 QoS,则多路复用可能会降低QoS的作用。
-
类似地,多路复用意味着多路复用中的所有流都具有相同程度的错误恢复能力。但是者不一定对于所有流都是合适的 ,因为某些流可能被认为比其他流更重要,并且可以从额外的保护中受益。
尽管存在这些问题,在某些情况下,多路复用RTP流仍然是可取的。最常见的情况是在两个点之间传输大量基本相同的流时。当使用VoIP作为骨干“干线”来替代传统的电话线路时,这种情况经常发生。
RTP 不直接支持多路复用。如果需要在 RTP 中使用多路复用流,则必须使用本章中描述的RTP扩展。
隧道复用压缩 RTP
IETF音视频传输工作组收到了多个RTP多路复用解决方案的提案。这些提案往往是基于不同应用的特定需求。虽然其中一些可能满足了这些应用的需求,但通常没有提供全面的解决方案。然而,少数几个提案中,一种名为“隧道多路复用压缩RTP”(TCRTP)的方案成功保留了RTP的语义。TCRTP被采纳为推荐的“最佳当前实践”解决方案。
TCRTP 的基本概念
TCRTP规范描述了如何将现有协议组合起来提供多路复用系统。它并未引入任何新的机制。TCRTP系统通过将RTP头部压缩、第二层隧道协议(L2TP)和PPP多路复用相结合实现。如图12.2所示,这个协议栈由多个层级组成。RTP头部压缩用于减少单个RTP负载的头部开销。隧道用于在多跳IP网络中传输压缩的头部和负载,而无需在每个链路上进行压缩和解压缩。多路复用用于通过在多个RTP负载间分摊单个隧道头部的方式来减少隧道头部的开销。
多路复用是通过在多个 RTP 有效负载共享一个隧道包头,从而来减少隧道包头的开销。
TCRTP的第一阶段是对头部进行压缩,这一步骤与通常的做法一样,通过在PPP链路上协商使用CRTP或ROHC来完成。但不同之处在于,PPP链路是代表隧道的虚拟接口,而不是真实链路。隧道本身对于头部压缩过程来说是不可见的,只有通过引入的丢包和延迟特性才能感知到其存在。这个概念类似于在虚拟私有网络(VPN)链路上运行RTP,不同之处在于其目的是提供更高效的传输,而不是更安全的传输。
与单个物理链路相比,隧道通常有更长的往返时间和更高的包丢失率,并可能重新排序包。如第 11 章包头压缩所讨论的,与这些属性对 CRTP 包头压缩有不利影响,并可能导致较差的性能。正在开发的 CRTP 的增强功能将减少这个问题。ROHC 不是一个很好的选择,因为它需要按顺序交付,而不能通过隧道来保证。
隧道是通过 L2TP 创建的,它为 IP 网络上的 PPP 会话提供了一个通用的封装。这是一个自然的选择,因为 CRTP 和 ROHC 通常都映射到 PPP 连接上,而 L2TP 允许透明地协商任何类型的 PPP 会话。如果 PPP 层的接口正确实现,CRTP/ROHC 实现将不知道 PPP 链接是一个虚拟通道。
不幸的是,当将隧道包头的开销添加到单个压缩 RTP 有效负载时,与未压缩的 RTP 流传输相比,节省的带宽非常少。需要多路复用来分摊 RTP 有效负载上的隧道头开销。因此,TCRTP 规范提案使用 PPP 多路复用。PPP 多路复用将连续的 PPP 帧组合成一个传输帧。它是在 PPP 连接设置过程中协商的一个选项,并且它支持可变大小和 PPP 帧类型的多路复用,如图 12.3 所示。
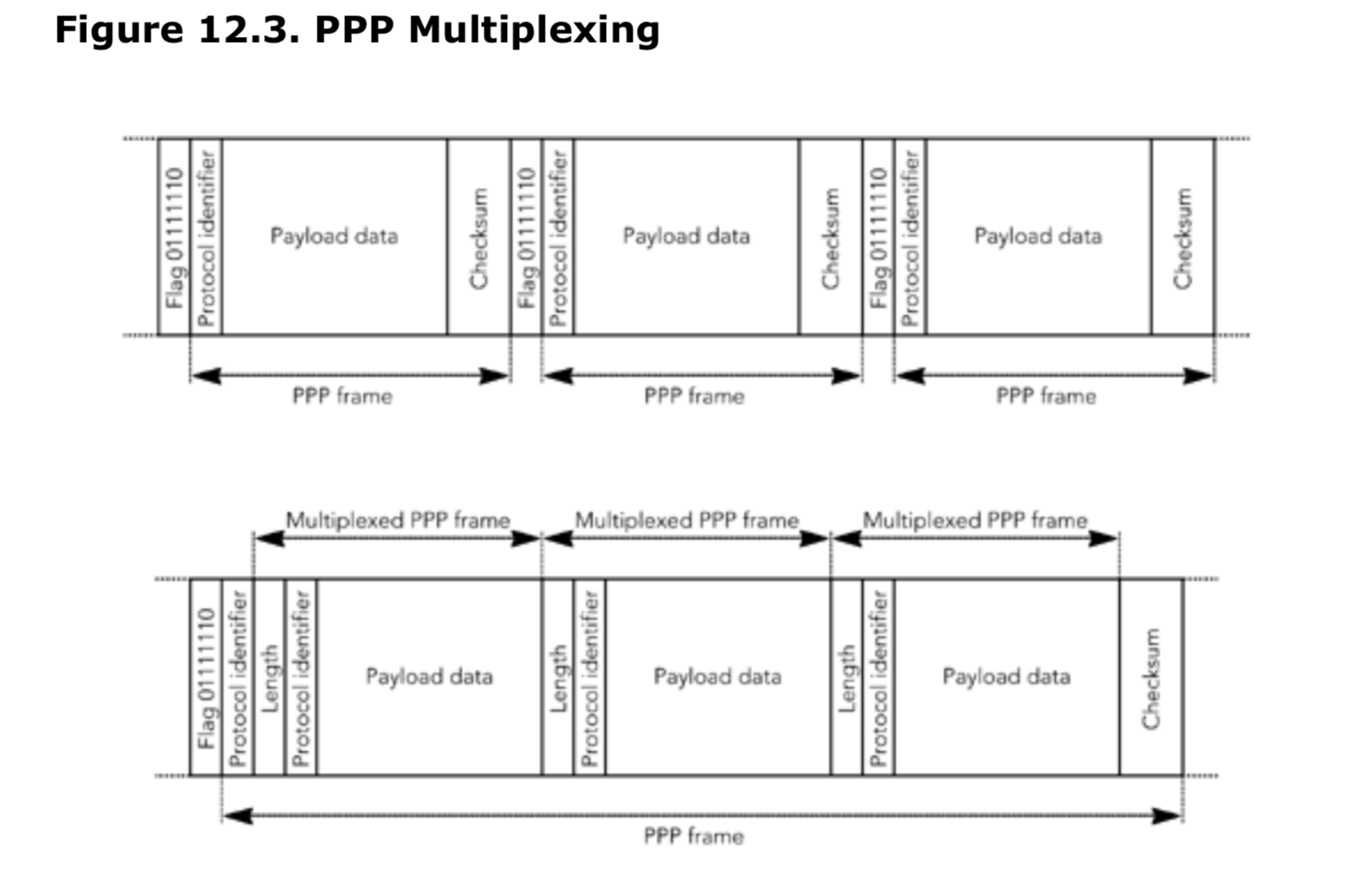
PPP在点对点比特流中添加帧结构,以便传输一系列的上层数据包。每个上层数据包至少添加了四个八位字节的帧结构:一个标志字节表示PPP帧的开始,接着是一个协议标识符,然后是作为有效数据的映射上层数据包,最后是一个两个八位字节的校验和(在通道建立期间协商的选项决定是否还有其他帧头)。通过将多个帧多路复用到一个帧中,PPP的开销从每个数据包的四个八位字节减少到两个。
当考虑到隧道开销时,TCRTP 多路复用的需求就变得很明显了。当PPP帧通过L2TP在IP上进行隧道传输时,每个帧会增加36个八位字节的开销(使用L2TP头部压缩HTPU46UTPH可以将这个数字降低到每个帧20个八位字节)。这样的开销增加会抵消头部压缩带来的好处,除非在进行隧道传输之前将帧进行多路复用。
实现 TCRTP
TCRTP 的优点是对上层协议不可见。生成 RTP 包的应用程序不能判断这些包是否被多路复用,而且应该可以在不更改现有应用程序的情况下将多路复用添加到现有应用程序中。
多路复用的通用性使 TCRTP 的使用具有很大的灵活性。例如,TCRTP 可以实现为主机上的虚拟网络接口,以多路复用本地生成的数据包,或者在路由器上实现为在两个公共中间点之间流动的多路复用数据包,或者作为独立网关的一部分,从 PSTN(公共交换电话网络)到 IP网络,在电话系统中多路复用语音呼叫。
根据不同的场景,可以以多种方式实现 TCRTP。一种可能的实现是将 TCRTP 协议栈作为标准的 PPP 网络接口呈现给系统的其余部分,该接口允许协商 RTP 包头压缩。在内部,它将实现 PPP 多路复用和 L2TP 隧道,这种实现对应用程序是透明的。
TCRTP 接口的透明性主要取决于操作系统。如果 IP 协议实现只是松散地耦合到第二层接口,那么应该可以相对容易和透明地添加一个新的接口—TCRTP。如果 IP 层与第二层接口紧密耦合,就像在嵌入式系统中 TCP/IP 实现根据特定链接的特性进行调优一样,那么这个过程可能会更加困难。
与网络堆栈的其他部分相互作用可能是一个更严重的问题。TCRTP是一种隧道协议,它将压缩的RTP/UDP/IP层叠在多路复用的PPP和L2TP之上,然后再层叠在UDP/IP之上。如果操作系统不支持隧道接口的概念,这种IP-over-something-over-IP的层叠可能会带来问题,并需要进行大量的工作来解决。如果系统将隧道接口隐藏在普通网络接口的抽象中,那会很有帮助,否则隧道接口的不同API可能导致与TCRTP不兼容的应用程序。
在TCRTP接口中,必须精确控制多路复用的程度,以限制延迟,并确保在多路复用中包含足够的数据包,以使头部开销保持在可接受的范围内。如果将过少的数据包进行多路复用,每个数据包的头部会变得很大,从而抵消了多路复用的效果。为了避免这个问题,我们可以延迟发送多路复用的数据包,直到它们累积了足够的数据,使头部开销达到可接受的水平。然而,由于交互式应用程序需要总的端到端延迟小于约150毫秒,多路复用不能引入太多的延迟。
非RTP流量也可以通过TCRTP隧道发送,但会显著降低压缩效率,因此最好将其与RTP流量分开。如果不同数据源的发送者配合,确保只有RTP数据包发送到特定的目的地,目的地址可以用来区分这两种类型的流量;可以通过更详细地检查数据包头部(例如,检查数据包是否为UDP数据包且目的端口位于特定范围内)来进行区分。由于RTP不使用固定的端口,无法直接区分RTP流和非RTP流;因此,除非生成这些数据包的应用程序以某种方式与多路复用器配合,否则多路复用器不能确定只传输RTP数据包。
性能
使用TCRTP可以节省带宽,具体取决于多种因素,包括多路复用的增益、隧道内预期的数据包丢失率以及多路复用的RTP和IP头部字段的变化速率。
多路复用减少了由于 PPP 和 L2TP 包头而造成的开销,并且随着越来越多的流加入多路复用 PPP 帧中,这种节省的比例增加。当更多的流被复用在一起时,性能一定提高,尽管每个流的增量增益随着复用中的流总数的增加而减少。
丢包率和包头字段的变化率会对包头压缩效率产生不利影响。丢包会导致上下文失效,在刷新上下文时压缩方法切换到效率较低的操作模式。如果使用标准的CRTP,问题尤其严重;而使用增强的CRTP可以稍微改善。包头字段的更改也可能导致压缩转换为效率较低的操作模式,从而发送一阶增量而不是完全压缩的二阶增量。对于这些情况,我们无法做太多改善,只能参考第11章中关于“RTP应用程序注意事项”的部分,其中也涉及到包头压缩和TCRTP。
TCRTP规范包含一个简单的性能模型,旨在预测使用增强的CRTP压缩的语音流在IP上所需的带宽、数据包大小和持续时间、平均通话长度、可复用的数据包数量以及由于RTP和IP包头的压缩变化而导致的开销估计。根据该模型的预测,对于一个G.729流,TCRTP将达到14.4 Kbps的速率。该流的数据包大小为20毫秒,有三个多路复用的数据包,并且平均对话并发长度为1500毫秒。这与逐跳CRTP实现的12Kbps以及没有包头压缩或多路复用的标准RTP(所有数字都包括由于PPP-in-HDLC[高级数据链路控制]帧造成的第二层开销)的25.4 Kbps形成了鲜明的对比。
当然,性能将严重依赖于媒体和网络的特性,但在这个示例中所见到的性能差异并不是不切实际的。只要有足够的流量进行多路复用,TCRTP的性能将明显优于标准的RTP,但略逊于逐跳头部压缩。
多路复用的其他方法
在 IETF 内部,多路复用一直存在一些争议和大量需要讨论的领域。虽然 TCRTP 是当前推荐的最佳实践,但还有其他一些建议值得进一步讨论。这包括通用的 RTP 多路复用 (GeRM),它是 TCRTP 的少数几个保持 RTP 语义的备选方案之一,以及几个特定于应用程序的多路复用。
GeRM
多路复用一直是IETF内部争议不断、讨论热烈的领域。尽管TCRTP被推荐为目前最佳实践,但还有其他值得进一步讨论的提案。其中包括通用RTP多路复用(GeRM),它是为数不多保持RTP语义的TCRTP替代方案之一,还有一些面向特定应用的多路复用方案。
概念和包格式
图12.4展示了GeRM的基本操作。首先创建一个单独的RTP数据包,然后在其中复用多个称为子数据包的RTP数据包。每个GeRM数据包都有一个外部的RTP头部,其中包含第一个子数据包的头部字段,但RTP有效载荷类型字段的值被设置为指示这是一个GeRM数据包的特定数值。
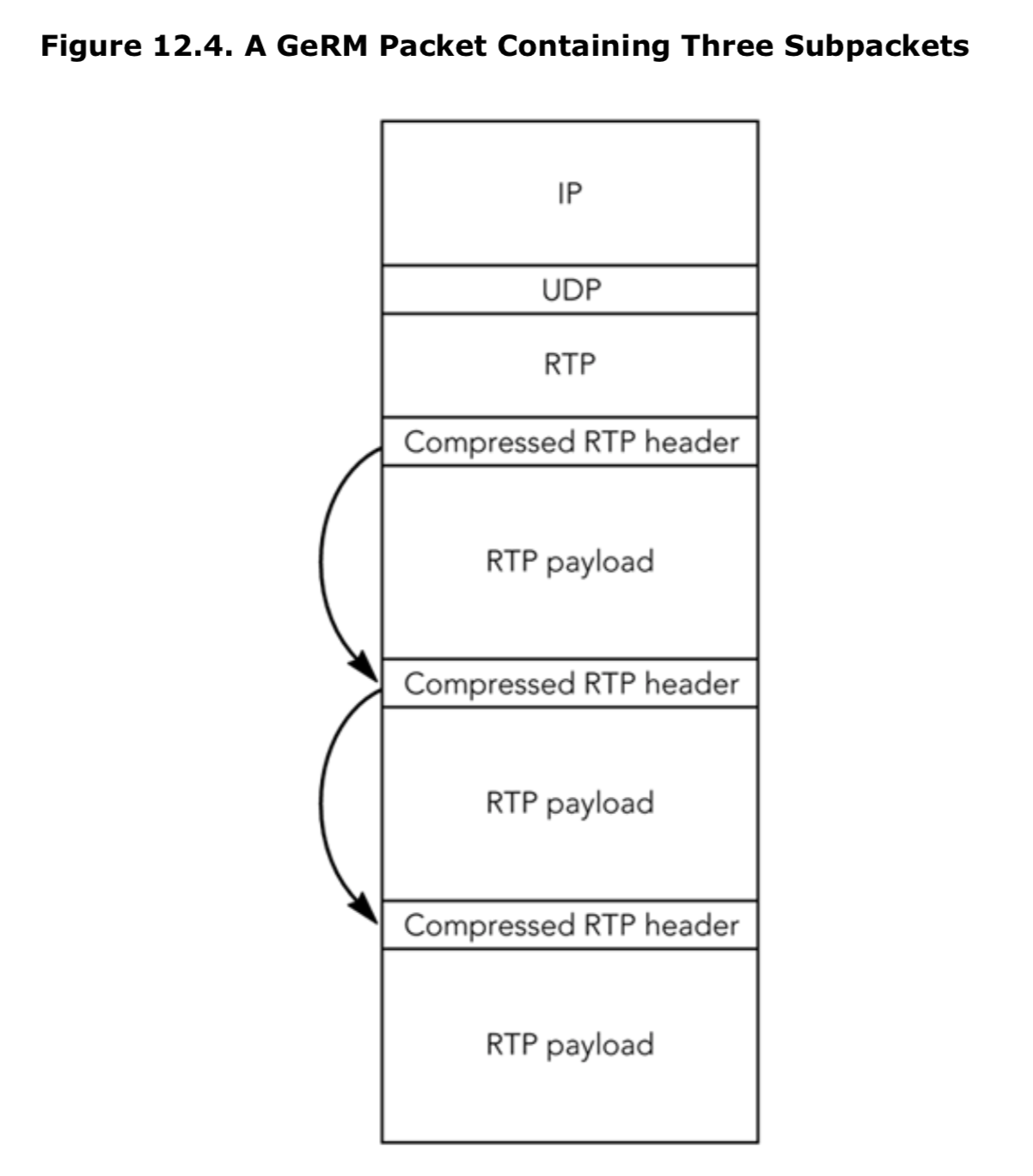
除了有效负载类型字段和长度外,第一个子包的包头将完全被压缩,因为完整的RTP包头和子包包头只在有效负载类型方面有所不同。然后,根据第二个子包的原始RTP包头与第一个子包的原始RTP包头之间预测的差异来对第二个子包的包头进行编码。接下来,第三个子包的包头基于其原始RTP包头与第二个子包的原始RTP包头的编码方式,以此类推。每个子包的包头由一个固定的8字节组成,后面跟着几个扩展的8字节,如图12.5所示。
强制八位中的位的含义如下:
B0: 0 表示原始 RTP 包头的第一个八位组与前一个子包中的原始 RTP 包头保持不变(如果此包中没有前一个子包,则为外 RTP 包头)。也就是说,V CC P 不变。1 表示原始 RTP 包头的第一个八位元紧接在 GeRM 包头之后。
B1: 这位包含子数据包 RTP 包头的标记位。 B2:0 表示负载类型保持不变。1 表示有效负载类型字段跟在 GeRM 头和任何可能出现的包头首字节之后。虽然 PT 是一个 7 位字段,但它是作为一个 8bit 字段添加的。这个字段的第 0 位总是 0。 B3:0 表示序列号保持不变。1 表示 16bit 序列号字段位于 GeRM 包头和可能存在的任何包头首字节或 PT 包头之后。 B4:0 表示时间戳保持不变。1 表示 32bit 的时间戳字段位于 GeRM 包头和可能存在的任何包头首字节、PT 或序列号包头之后。 B5:0 表示 SSRC 的最高有效的 24 位保持不变。1 表示 SSRC 最高有效的 24 位位于 GeRM 头和可能存在的PT、序列号或时间戳字段之后。 B6:0 表示 SSRC 的最低有效 8bit 比前一个 SSRC 高 1 位。1 表示 SSRC 的最低有效的 8bit 位于源包头和可能存在的首八位、PT、序列号、时间戳或 MSB SSRC 包头字段之后。 B7:0 表示以字节为单位的子包长度(忽略子包包头)与前面的子包相同。1 表示子包长度(忽略子包包头)遵循所有其他 GeRM 包头作为一个 8bit 无符号整数长度字段。一个 8bit 长度的字段就足够了,因为较大的数据包通过多路复用可以获得的增益很少。
原始 RTP 包头中存在的 CSRC 字段,跟随在原始包头。接下来的是 RTP 有效负载。
应用场景
由于 GeRM 而节省的带宽取决于多路复用包之间的包头的相似性。考虑两个场景:任意的包和协作应用程序生成的包。
如果要对任意的 RTP 包进行多路复用,则多路复用的增益很小。如果包之间没有相关性,那么所有可选字段都将出现,并且子包包头的长度为 14 字节。与非多路复用的 RTP 相比,仍然有优势,因为一个 14 字节的 RTP/UDP/IP 包头比 40 字节的 RTP/UDP/IP 包头要小,但是与标准包头压缩相比,节省的带宽相对较小。
如果要进行多路复用的包是通过协作应用程序产生的,则由 GeRM 节省的带宽可能要大得多。在最简单的情况下,所有要复用的包都具有相同的有效负载类型、长度和 CSRC 列表;除了第一个子数据包包头外,所有的字节都被删除了 3 个字节。如果生成包的应用程序相互协作,它们可以合作以确保子包中的序列号和时间戳匹配,从而节省额外的 6 个字节。如果应用生成具有连续同步源标识符的分组,也允许移除 SSRC,则可以节省更多带宽。
当然,这种相互协作扩展了RTP的应用范围。特别是,对于生成非随机SSRC标识符的应用程序,可能会在与使用标准RTP的发送端进行会话时引起严重问题。然而,在某些情况下,使用非随机SSRC是可以接受的:
- 当使用 RTP 和 GeRM 在两个网关之间传输媒体数据时。在这种情况下,数据的发送端和接收端意识不到 RTP 和 GeRM 被用来传输数据也算是一种幸运。例如,一个系统可以生成 ip 上的语音数据包,作为两个 PSTN 交换之间的网关的一部分。
- 当复用设备在被包含进 GeRM 之前重新映射 SSRC 时,用多路复用设备重新生成原始的 SSRC。在这种情况下,SSRC 标识符映射必须在带外发出信号,但这可以作为调用设置过程的一部分。
在最好的情况下,GeRM 可以生成每个多路复用数据包带有2字节标头的数据包,与非多路复用 RTP 相比,这可节省大量带宽。与非多路复用 RTP 相比,GeRM 将始终减少包头开销。
GeRM 的未来
GeRM 不是一个标准的协议,目前也没有计划完成它的规范。这样做有几个原因,其中最主要的原因是,如果在网络中应用了 GeRM,应用程序在生产 RTP 包头时协作的要求将限制协议的应用范围并影响互操作性。此外,带宽节省相对较小,除非这种协作发生,这可能使 GeRM 不那么有吸引力。
作为特定于应用程序的多路复用器,GeRM 的概念非常有用,它位于两个网关之间,这两个网关使用相同的编解码器对多个 RTP 流进行发送和接收,并且愿意为这些流协作生成 RTP 包头。典型的例子是 IP-PSTN 网关,其中 IP 网络充当两个 PSTN 交换机之间的长途中继链路。GeRM允许这样的系统保持大部分RTP语义,同时提供高效的多路复用,并且可以仅在应用层实现。
特定于应用程序的多路复用
除了 TCRTP 和 GeRM 等通用多路复用协议外,还提出了各种特定于应用的多路复用协议。这些多路复用的绝大多数都是针对 IP 到 PSTN 网关的,其中 IP 网络充当两个 PSTN 交换之间的长途中继。这些网关之间有许多并发的语音连接,可以通过多路复用来提高效率,支持使用低比特率的语音编解码器,提高可伸缩性。
这种网关通常使用 RTP 协议的一个非常有限的特性子集。所有要进行多路复用的流通常使用相同的有效负载格式和编解码器,它们可能不采用静音抑制。此外,每个流表示单个会话,因此不需要 RTP 的混流功能。所以 RTP 包头的 CC、CSRC、M、P 和 PT 字段是冗余的,序列号和时间戳之间有一个常量关系,可以省略其中一个。删除这些字段后,只剩下序列号/时间戳和同步源 (SSRC) 。鉴于 RTP 的使用如此有限,显然有必要在这些场景中使用特定于应用程序的多路复用。
将几个RTP流转换为具有减少头部的单个多路复用是一种特定于电话通信的多路复用操作。在最简单的情况下,这种多路复用可以将仅包含序列号和同步源的数据包组装成UDP数据包,并使用带外信令来定义这些减少的头部与完整RTP头部之间的映射关系。根据应用程序的不同,多路复用可以在真实的RTP数据包上进行操作,也可以是将PSTN数据包直接转换为多路复用数据包。目前还没有针对这种特定应用的多路复用的标准解决方案。
作为一种替代方案,可以为TDM(时分多路复用)有效负载定义一种RTP有效负载格式。这将允许直接传输PSTN语音,而无需首先将其映射到RTP。该格式可以被定义为一种"电路仿真"格式,旨在传输内容而不关心其内容。
在这种情况下,RTP头部将与链路相关联。同步源(SSRC)、序列号和时间戳与链路相关,和同意链路上的其他会话无关;有效载荷类型标识“T1仿真”;混音器功能相关字段未被使用,标记位和填充也未被使用。图12.6展示了该过程可能的工作方式,每个T1帧形成一个单独的RTP数据包。

当然,由于 RTP 开销很大,对 T1 线路的直接模拟收益很少。但是,在每个 RTP 包中包含几个连续的 T1 帧是完全合理的,或者模拟一个更高速率的链路,这两者都可以显著降低 RTP 开销。
IETF 有一个伪线边缘到边缘仿真工作组,该工作组正在开发电路仿真标准,包括 PSTN(公共交换电话网)、SONET(同步光网络)和 ATM(异步传输模式)电路。这些标准还没有完成,但 RTP 负载格式的电路仿真是一个建议的解决方案。
用于 ip-pstn 网关设计的电路仿真方法比特定于应用程序的多路复用解决方案更符合 RTP 原理。强烈建议将电路仿真作为此特定应用程序的解决方案。
总结
多路复用通常是不可取的。它强制所有媒体流使用单一传输,阻止接收端根据需要对其进行优先级排序,并使其难于应用错误纠正。在几乎所有情况下,包头压缩都提供了更合适、更高效的解决方案。
然而,在某些有限的情况下,多路复用可能是有用的,主要是当许多本质上相同的流在两个点之间传输时,这种情况经常发生在 ip 电话被用作取代传统电话线的主干“中继线”时。
第十三章 安全考虑
- 隐私
- 保密
- 认证
- 重播保护
- 拒绝服务
- 混流器和转换器
- 动态内容
- 其他注意事项
到目前为止,我们只考虑了在一个隔离的安全环境中怎么实现 RTP。然而,在现实世界中,有些人会试图窃听会话,冒充合法用户,以及出于恶意目的侵入系统,因此在现实世界中,一个正确的 RTP 系统实现应该能防卫此类攻击,为其用户提供稳私、机密性和身份验证服务。本章描述了用于增强用户隐私的 RTP 特性,并概述了各种潜在的攻击以及如何防范这些攻击。
隐私
显而易见的隐私问题是如何防止未经授权的第三方窃听 RTP 会话。这个问题在下一节讨论。然而,保密性并不是唯一的隐私问题;用户可能希望限制他们在会话期间向外暴露出的个人信息量,或者他们可能希望对其通信伙伴进行身份保密。
如第5章的RTP控制协议中所述,源信息(可能包括个人详细信息)被封装在RTCP源描述包中进行传输和交换。这些信息有多种用途,其中大多数是合法的,但有些用途可能被用户视为不恰当。例如,远程会议应用程序使用RTCP源描述包来传输参与者的名称和从属关系,或提供其他呼叫者的身份标识信息,这是一个合法的用途。然而,当用户收听在线广播时,通过RTCP源描述包收集个人详细信息,以便广播公司及其广告商追踪听众,这就是一个非法的使用例子。
必须发送的规范名 (CNAME) 是一个例外。CNAME 包括有参与者的 IP 地址,但这不应该被视做一个隐私问题,因为这些数据可以从 IP 包头得到(当使用了 NAT 设备,CNAME 中是一个内部的 IP 地址)。CNAME 还公开了参与者的用户名,这可能是一个更大的隐私问题,但应用可以省略或重写用户名以隐藏此信息,前提是通过 CNAME 关联会话的所有应用都一致地执行此操作。
CNAME 相当于一个唯一标识符,可以用来跟踪参与者。如果参与者从具有临时 IP 地址(例如,拨号用户的 IP 地址是动态分配的)的计算机加入,则可以避免被跟踪。如果系统有一个静态的 IP 地址,就无法保护该地址不被跟踪,但是 CNAME 暴露出的 IP 信息是比 IP 头中获得的信息要更少(尤其是当 CNAME 中用户名部分被隐藏时)。
一些接收端可能根本不想别人看到他们的存在。这些接收端不发送 RTCP 包也是可以接受的,但这样会阻止发送端使用接收质量信息来调整其传输以匹配接收端(并且也可能导致源认定接收端已失败,并停止传输)。此外,一些内容提供商可能需要 RTCP 报告来衡量其受众的规模。
一个相关的隐私问题涉及到在谈话中保密对方的身份。即使使用了下一节中描述的保密措施,窃听者也可以观察传输中的 RTP 包,并通过查看 IP 包头获得一些通信知识(例如你的老板可能会有兴趣知道你的 IP 语音呼叫的目的 IP 地址是否是招聘机构所拥有)。这个 IP 暴露的问题不容易解决,但是如果流量是通过一个可信的第三方网关来路由的,这个网关充当一个中间的 IP 地址,就可以减轻这个问题(对网关的流量分析可能仍然会揭示通信模式,除非网关设计为能够抵抗这种分析)。
保密
RTP 的关键安全要求之一是保密性,确保只有预期的接收端才能解码 RTP 包。RTP 内容通过加密来保密,无论是在应用级加密整个 RTP 包,还是仅加密有效负载部分,或是在 IP 层。
应用级的加密,对于 RTP 来说,有优点也有缺点。它的主要优点是允许包头压缩。如果仅对 RTP 有效负载进行加密(即应用级的加密),则包头压缩将正常工作,这对于某些应用(例如,使用 RTP 的无线电话)是必不可少的。如果 RTP 包头也被加密,则包头压缩的操作在一定程度上会中断,但仍然可以压缩 UDP/IP 包头。
应用级加密的另一个优点是它易于实现和部署,不需要更改主机操作系统或路由器。不幸的是,这也是一个潜在的缺点,因为它将正确实现的负担扩展到所有应用。加密代码是非常重要的,必须注意确保安全性不会因设计不当或实现中的缺陷而受到损害。
再次值得一提:加密代码是很重要的,必须注意确保安全,不会因不良的设计或实现中的缺陷而受到影响。我强烈建议读者在使用加密构建系统之前,先详细研究相关标准,并确保使用众所周知的,经过公开分析的加密技术。
应用级加密的另一个潜在缺点是,它会使某些包头字段未加密。在某些情况下,缺少加密可能会泄露敏感信息。例如,对负载类型字段的了解可能允许攻击者确定加密负载数据部分的值,这可能是因为每一帧以标准格式的负载头开始。如果选择了合适的加密算法,这不应该是个问题,但它有可能危及本已薄弱的解决方案。
作为替代方案,可以在 IP 层执行加密,例如,使用 IP 安全协议。这种方法的优点是对 RTP 是透明的,并且提供了一套经过充分测试的加密代码,可以信任它们是正确的。IP 层加密的缺点是它会中断 RTP 包头压缩的操作,并且其部署需要对主机操作系统进行大量改造。
RTP 规范中的保密特性
RTP 规范提供了对 RTP 数据包(包括头)和 RTCP 包的加密支持。
RTP 数据包的所有字节,包括 RTP 包头和有效负载数据,都是可以加密的。实现可以选择它们支持的加密方案。根据使用的加密算法,可能需要在执行加密之前将填充的八位字节附加到有效负载中。例如,DES 加密对 64 位的块进行操作,因此如果有效负载的长度不是 8 个字节的倍数,则需要对其进行填充。图 13.1 说明了该过程。当有填充字节时,RTP 头中的 P 位必须被设置,并且填充字节的最后一个字节,指示有填充多少字节。
图 13.1 RTP 数据包的标准加密

当 RTCP 包被加密时,在第一个包之前插入一个 32bit 随机数,如图 13.2 所示。这样做是为了防止已知的纯文本攻击。RTCP 包中很多的八位字节都具有标准格式;这些固定八位字节存在的知识使得狡猾的破解者的工作更容易,因为他知道他寻找的东西有部分一定在一个解密的包中。破解者可以使用强力密钥猜测,在解密尝试中使用那些具有标准格式的八位字节值来确定何时停止。
图 13.2 RTCP 数据包的标准加密

前缀的插入为加密算法提供初始化,从而有效地防止已知的纯文本攻击。数据包不使用前缀,因为固定头字段较少:同步源是随机选择的,序列号和时间戳字段具有随机偏移量。
在某些情况下,希望只加密部分 RTCP 数据包,而明文发送其他部分。典型的例子是加密 SDES 项,但不加密 RR(接收端报告)。我们可以通过将一个复合 RTCP 包拆分为两个单独的复合包来实现这一点。第一个包括 SR/RR 包;第二个包括空 RR 包(以满足所有复合 RTCP 包以 SR 或 RR 开头的规则)和 SDES 项。(有关 RTCP 数据包格式,请参阅第 5 章,RTP 控制协议。) 图 13.3 说明了这个过程。
图 13.3 对控制包进行部分加密的标准方式

该规则有一个例外,即所有复合 RTCP 数据包都必须同时包含 SR/RR 数据包和 SDES 数据包:将复合数据包拆分为两个单独的复合数据包进行加密时,SDES 数据包仅包含在一个复合数据包中,而不是全部。
以 CBC 模式工作的 DES 是默认的加密算法。在设计 RTP 时,DES 提供了适当的安全级别。然而,机器处理能力的提高使其变得很弱,因此建议在可能的情况下选择更强的加密算法。合适的强加密算法有 3DES 和 AES。为了最大限度地提高互操作性,支持加密的所有实现都应该支持 DES,尽管它不是强加密算法。
接收端通过包头或有效负载的有效性检查(如第 4 章 RTP 数据传输协议和第 5 章 RTP 控制协议的分组验证部分中所述的检查)来确认加密的存在和正确密钥的使用。
RTP 规范没有定义任何交换加密密钥的机制。然而,密钥交换是任何系统的重要组成部分,必须在会话启动期间执行。SIP 和 RTSP 等协议应以适合 RTP 的形式提供密钥交换。
使用安全 RTP 配置文件的机密性
安全 RTP(SRTP)配置文件提供了 RTP 规范中加密机制的替代方案。这一新的配置文件是根据无线电话的需要而设计的,它提供了保密性和身份验证,适用于可能具有较高丢包率的链路,并且需要包头压缩以实现高效操作。SRTP 是一项正在进行的工作,在撰写本文时,协议的细节仍在不断发展。规范完成后,读者应参考最终标准,以确保此处描述的细节仍然准确。
SRTP 通过仅加密数据包的有效负载部分来提供 RTP 数据包的机密性,如图 13.4 所示
图 13.4 数据包的 SRTP 加密

RTP 头以及任何头扩展都是在不加密的情况下发送的。假如 RTP 包中的负载数据区域,有一个负载头,则该负载头将与负载数据一起加密。认证头在“认证”这一节被详细描述,使用了本章后面的安全 RTP 配置文件。密钥管理协议可以使用可选的主密钥标识符,以便在加密上下文中重新设置和标识特定的主密钥。
使用 SRTP 时,发送端和接收端需要维护一个加密上下文,包括加密算法、主密钥和转换密钥、一个 32bit 滚动计数器(它记录 16bitRTP 序列号反转的次数)和会话密钥产生的速率。接收端还应记录接收到的最后一个分组的序列号,以及重播列表(当使用认证时)。RTP 会话的传输地址与 SSRC 一起用于确定哪个加密上下文用于加密或解密数据包。
默认的加密算法是计数器模式或 f8 模式下的 AES,计数器模式是强制实现的。未来可能会定义其他算法。
加密过程包括两个步骤:
- 系统通过一个非基于 RTP 的密钥交换协议提供一个或多个主密钥。每个会话密钥是一个伪随机函数的采样,在发送了一定数量的数据包后,以主密钥、数据包索引和密钥产生速率作为输入进行重新绘制。根据加密上下文中的密钥产生速率,会话密钥可能会针对发送的每个数据包进行更改。密钥管理协议可以使用主密钥标识符来指示要使用哪个预交换的主密钥,从而允许同步主密钥中的更改。
- 通过基于包索引和会话密钥生成密钥流,然后利用 RTP 包的有效负载部分计算该密钥流的逐位异或(XOR),以对包进行加密。
在这两个步骤中,包索引是 32bit 扩展的 RTP 序列号。如何生成密钥流的细节取决于加密算法和操作模式。
如果使用计数器模式下的 AES,则以这种方式生成密钥流:一个 128bit 整数的计算方法如下:(2 的 16 次方 x 包索引)XOR(加盐键(the salting key) x 2 的 16 次方)XOR(SSRC x 2 的 64 次方)。整数使用会话密钥加密,从而生成密钥流的第一个输出块。然后整数以 2 的 128 次方为模递增,用会话密钥再次对块进行加密。结果是密钥流的第二个输出块。该过程重复,直到密钥流至少与要加密的包的有效负载部分一样长。图 13.5 显示了这个密钥流的生成过程。
图 13.5 SRTP 密钥流的生成:计数器模式下的 AES

在计数器模式下实现 AES 时,你必须确保每个包都用唯一的密钥流加密(密钥流派生函数中存在包索引和 SSRC 可确保这一点)。如果意外地使用同一密钥流加密两个数据包,则加密将变得很容易被破解:只需将这两个包异或在一起,纯文本就变得可用了(请记住,在第 9 章错误恢复中对奇偶校验 FEC 的讨论中,A XOR B XOR B = A)。
如果在 f8 模式下使用 AES,则密钥流的生成方式如下:会话密钥和加盐密钥的异或结果,用于加密初始化向量。如果加盐密钥的长度小于 128bit,则用交替的 0 和 1 填充到 128bit。结果称为内部初始化向量。内部初始化向量和 128bit 变量的异或生成密钥流的第一个块,并且会被会话密钥加密。变量 j 递增,密钥流的第二个块是由内部初始化向量,变量 j 和密钥流的前一个块,三者的异或生成。该过程重复,j 每次递增,直到密钥流至少与要加密的包的有效负载部分一样长。图 13.6 显示了这个密钥流生成过程。
图 13.6 SRTP 密钥流的生成:f8 模式下的 AES

默认的加密算法和模式是 AES 的计数器模式;AES;f8 模式的使用可以在会话初始化期间协商。
SRTP 同样提供了 RTCP 加密功能。整个 RTCP 包被加密,不包括初始公共头(包的前 64 位)和添加到每个 RTCP 包末尾的几个附加字段,如图 13.7 所示。几个附加字段是 SRTCP 索引(E 位指示有效负载是否加密)、可选的主密钥标识符和验证头(验证头在本章后面的“使用安全 RTP 配置文件进行身份验证”一节中进行了描述)。
图 13.7 控制包的安全 RTP 加密

RTCP 包的加密过程与 RTP 数据包的加密过程基本相同,但使用 SRTCP 索引代替扩展的 RTP 序列号。
标准 RTCP 加密期间应用的加密前缀不与 SRTP 一起使用(加密算法的差异意味着前缀没有任何好处)。将 RTCP 数据包分成加密和未加密的数据包是合法的,就像标准 RTCP 加密一样,由 SRTCP 数据包中的 E 位表示。
与 RTP 规范一样,SRTP 配置文件没有定义交换加密密钥的机制。密钥必须通过非 RTP 方式交换,例如,在 SIP 或 RTSP 内。主密钥标识符可用于同步主密钥的更改。
使用 IP 安全的机密性
除了标准 RTP 和 SRTP 提供的应用级安全性外,还可以将 IP 级安全性与 RTP 结合使用。IP 安全是作为操作系统网络堆栈的一部分或在网关中实现的,而不是由应用实现的。它为来自主机的所有通信提供安全性,不是 RTP 特定的。
IP 安全(IPsec)有两种操作模式:传输模式和隧道模式。传输模式在 IP 和传输头之间插入一个附加头,提供 TCP 或 UDP 包头和有效负载的机密性,但不影响 IP 包头。隧道模式将整个 IP 数据包封装在一个安全头中。图 13.8 说明了两种操作模式之间的差异。隧道模式下的 IP 安全最常用于构建虚拟专用网络,在两个网关路由器之间进行隧道,以安全地在公共互联网上扩展内网(intranet)。当需要单个主机之间的端到端安全性时,使用传输模式。
图 13.8 传输模式与隧道模式

隧道模式和传输模式都支持数据包的保密和验证。保密是由一种称为封装安全有效负载(ESP)的协议提供的。ESP 由附加的包头和添加到每个数据包的尾部组成。头部包括安全参数索引和序列号;尾部包含填充和封装数据类型的指示(如果使用传输模式,则为 TCP 或 UDP;如果使用隧道模式,则为 IPIP 隧道). 封装在头和尾之间的是受保护的数据。图 13.9 显示了头,尾和封装过程。
图 13.9 一个封装的安全有效负载包

安全参数索引(SPI)和序列号分别占用 4 个字节。SPI 用于选择加密上下文,从而选择要使用的解密密钥。序列号是随着每个数据包的发送加一,用于提供重播保护(参见本章后面标题为重播保护的章节). 在这两个头字段之后是封装的负载:如果使用传输模式,则为 UDP 包头,后跟 RTP 包头和有效负载;如果使用隧道模式,则为 IP/UDP/RTP 包头和有效负载。
在有效负载数据之后是填充数据(如果需要填充对齐)和一个“下一个头”字段。最后一个字段确定封装头的类型。它的名字有点误导人,因为这个字段所指的包头实际上是在这个数据包的前面发送的。最后,可选的身份验证数据在数据包的末尾(请参阅本章后面标题为“使用 IP 安全进行身份验证”那部分内容)。
ESP 使用对称算法对数据包的受保护数据段进行加密(必须实现 DES;可以协商其他算法)。如果 ESP 是与 RTP 一起使用时,将对整个 RTP 包头和负载以及 UDP 包头和 IP 包头(如果使用隧道模式)进行加密。
在传输模式下,无法将包头压缩与 IP 安全一起使用。如果使用隧道模式,则在加密和封装之前可以压缩内部 IP/UDP/RTP 头。这样做很大程度上消除了 IPsec 包头带来的带宽损失,但并没有达到包头压缩所期望的效率。如果以带宽效率为目标,则应使用应用级 RTP 加密。
IPsec 也可能给某些防火墙和网络地址转换(NAT)设备带来困难。特别是,IPsec 隐藏 TCP 或 UDP 包头,用 ESP 包头替换它们。防火墙通常配置为阻止所有无法识别的通信,因此除了 TCP 和 UDP,防火墙还必须配置为允许 ESP。由于 TCP 或 UDP 端口号在 ESP 数据包中加密时无法转换,因此 NAT 会出现相关问题。如果存在防火墙和 NAT,则应用级 RTP 加密可能更成功。
IP 安全协议套件包括一个广泛的信令协议,Internet 密钥交换(IKE),用于设置必要的参数和加密密钥。IKE 的细节超出了本书的范围。
其他注意事项
当使用交织或前向纠错时,几种 RTP 有效负载格式提供包之间的耦合。数据包之间的耦合可能会影响加密操作,从而限制可以更改加密密钥的次数。图 13.10 显示了一个交织的例子,说明了这个问题。
图 13.10 加密与交织的交互

RTP 可以使用一系列加密算法,但它们定义了一个“必须实现”的算法,以确保互操作性。在许多情况下,DES 是必须实现的算法。计算能力的进步使得 DES 显得相对薄弱,目前已经证明了 DES 在不到 24 小时内就可以被强力破解,因此如果可能的话,协商一个更强大的算法是有必要的。3DES 和最近公布的高级加密标准(AES)是合适的选择。
使用端到端加密以确保 RTP 中的机密性,对于防止未经授权访问内容(无论内容是付费电视还是私人电话对话)是有效的。这种保护通常是可取的,但它确实还涉及一些更广泛的议题。特别是,在某些辖区中,有关执法人员是否有权力窃听通讯的争论一直在进行。在 RTP 中广泛使用加密作为保密措施,使得此类窃听和其他形式的窃听更加困难。此外,一些司法管辖区限制使用或分销包括加密的产品。在实施本章所述的保密措施之前,你应了解在你的管辖区内使用加密的法律和法规问题。
认证
有两种类型的身份验证:证明数据包没有被篡改,称为完整性保护,以及证明数据包来自正确的源,称为源身份验证。
完整性保护是通过使用消息身份验证代码来实现的。这些代码接受一个要保护的包和一个只有发送端和接收端知道的密钥,并使用它们生成一个唯一的签名。如果攻击者不知道密钥,则不可能在更改了包的内容,却还能使包的内容与消息身份验证代码相匹配。对称共享机密的使用限制了对多人参与的组中的源进行身份验证的能力,因为组中的所有成员都可以生成经过身份验证的数据包。
对于 RTP 应用而言,源认证是一个困难得多的问题。首先可能会认为它等同于生成消息身份验证代码的问题,但是由于发送端和接收端之间的共享机密不足,因此更加困难。相反,有必要在签名中标识发件人,这意味着签名更大且计算起来更昂贵(在很多方面,公钥加密比对称加密更昂贵)。该要求通常使得验证 RTP 流中每个数据包的源变得不可行。
像机密性一样,身份验证可以应用于应用级别或 IP 级别,具有相同的优点和缺点。两种替代方案均已开发用于 RTP。
使用标准 RTP 进行身份验证
标准 RTP 不支持完整性保护或源身份验证。需要身份验证的实现应该实现安全 RTP,或者使用较低层的身份验证服务,如 IP 安全扩展提供的服务。
使用安全 RTP 配置文件进行身份验证
SRTP 支持消息完整性保护和源身份验证。为了完整性保护,消息身份验证标签将附加到数据包的末尾,如图 13.4 所示。消息认证标签是在整个 RTP 数据包上计算的,并且是在数据包已加密后计算的。在撰写本文时,已指定了 HMAC-SHA-1 完整性保护算法用于 SRTP。其他完整性保护算法可能会在将来定义,并与 SRTP 协商使用。
TESLA 源认证算法已被考虑用于 SRTP,但在编写本文时 TESLA 尚未完全定义。建议你在完成时参考 SRTP 规范以了解详细信息。
SRTP 的身份验证机制不是强制性的,但我强烈建议所有实现都使用它们。特别是,你应该知道,除非使用身份验证,否则攻击者极有可能伪造使用 AES(计数器模式下)加密的数据。安全 RTP 配置文件规范详细描述了这个问题。
使用 IP 安全的身份验证
IP 安全扩展可以为从主机发送的所有数据包提供完整性保护和身份验证。有两种方法可以做到这一点:作为封装安全负载的一部分,或者作为身份验证头。
前面在标题为“使用 IP 安全性的机密性”中介绍了封装安全性有效负载。如图 13.9 所示,ESP 包括一个可选的身份验证数据部分,作为尾部的一部分。如果存在,则身份验证将对整个封装的有效负载以及 ESP 标头和尾标进行检查。外部 IP 头不受保护。
ESP 的替代方法是 RFC 2402 中定义的身份验证头(AH),如图 13.11 所示。此头中的字段非常类似于 ESP 中的对应字段,并且 AH 可以在隧道模式和传输模式中使用。关键区别在于整个数据包都经过了身份验证,包括外部 IP 标头。
图 13.11 IPsec 验证头

如果要求提供机密性和身份验证,则 ESP 是适当的(使用 ESP 加密和 AH 进行身份验证会导致过多的带宽开销)。如果唯一的要求是身份验证而不是机密性,那么 ESP 和 AH 之间的选择取决于是否认为有必要对外部 IP 包头进行身份验证。通过确保源 IP 地址不被欺骗,外部头的身份验证提供了一些额外的安全性。它还具有导致无法进行网络地址转换的副作用。
一系列认证算法可以与 IP 安全一起使用。如果使用身份验证,则 ESP 和 AH 的强制算法为 HMAC-MD5-96 和 HMAC-SHA-96,它们仅提供完整性保护。将来可能会定义用于源身份认证的算法。
前面标题为“使用 IP 安全进行保密”的部分提到了 IP 安全与包头压缩,防火墙和 NAT 之间的潜在交互问题。当使用 IP 安全提供身份验证时,这些问题也适用。
IP 安全协议套件包括一个扩展的信令协议,即 Internet 密钥交换(IKE),用于设置必要的参数和身份验证密钥。IKE 的详细信息超出了本书的范围。
重播保护
与身份验证相关的是重播保护问题:阻止攻击者记录 RTP 会话的数据包,并在以后出于恶意目的将其重新注入网络。RTP 时间戳和序列号提供有限的重播保护,因为实现应该丢弃旧数据。但是,攻击者可以在回放之前观察数据包流并修改记录的数据包,使它们与预期的时间戳和接收端的序列号相匹配。
为了提供重播保护,必须对消息进行身份验证以实现完整性保护。这样做可阻止攻击者更改重播数据包的序列号,从而使旧数据包无法重播到会话中。
拒绝服务
当有效负载格式使用了压缩技术,并且接收端进行解码要消耗大量计算时,会存在潜在的拒绝服务威胁。如果有效负载格式具有这种属性,则攻击者可能能够将病理数据包注入媒体流中,该数据包很难解码并导致接收端超载。接收端几乎无法避免此问题,除非在过载情况下停止处理数据包。
另一个可能导致拒绝服务的问题是未能正确实现 RTCP 时序规则。如果参与者以恒定速率发送 RTCP,而不是随着组大小的增加而增加包之间的间隔,则 RTCP 流量将随组大小线性增长。对于大型组,这种增长可能会导致严重的网络拥塞。解决方案是密切关注 RTCP 是否正确实现。
同样,当成员发生快速变化时,未能实现 RTCP 重新考虑算法可能会导致瞬时拥塞。这是一个次要问题,因为这种影响只是暂时的,但可能仍然是一个问题。
如果 RTP 实现对包丢失作出不适当的响应,也会发生网络拥塞。第 10 章《拥塞控制》详细描述了这些问题;就我们这里的目的而言,可以说拥塞会导致严重的拒绝服务。
混流器和转换器
不可能使用 RTP 混流器来组合加密的媒体流,除非该混流器是可信的并且可以访问加密密钥。如果会话需要保密,混流器是不能使用的。
如果对媒体流进行加密,则转换也很困难,尽管不一定是不可能的。除非转换器是可信的,否则涉及对媒体流重新编码的转换通常是不可能的。然而,一些转换不需要对媒体流重新编码,例如,IPv4 和 IPv6 传输之间的转换,并且这些转换可以在不影响加密的情况下提供,并且没有转换器是否可信的问题。
如果混流器或转换器修改媒体流,则源身份验证也同样困难。同样,如果混流器或转换器是可信的,则它可以对修改后的媒体流重新签名;否则无法对源进行身份验证。
动态内容
大多数视听内容都是被动的:它包含编码后的数据,这些数据可经静态解密算法生成原始内容。除了前面提到的由非均匀处理要求引起的问题外,此类内容并不危险。
然而,还有另一类内容:包含可执行代码的内容,例如 Java applets 或 ECMAScript,它们可以包含在 MPEG-4 流中。除非受到严格限制,否则此类动态内容有可能在接收系统上执行任意操作。
其他注意事项
SDES 项的文本不是以 NULL 结尾的,在假定以 NULL 结尾的字符串的语言中操作 SDES 项需要小心。这是基于 C 语言实现的一个特殊问题,必须注意确保它们使用长度检查字符串操作函数,例如 strncpy() 而不是 strcpy()。粗心的实现可能容易受到缓冲区溢出攻击。
SDES 项的文本是由用户输入的,因此不能信任它具有安全值。尤其是,它可能包含具有不良副作用的元字符。例如,某些用户界面脚本语言允许元字符触发命令替换,这可能会给攻击者提供执行任意代码的方法。
实现不应假定数据包格式良好。例如,攻击者可能会生成实际长度与预期长度不对应的数据包。同样,对于这个粗心的实现也有可能发生缓冲区溢出攻击。
总结
本章概述了 RTP 的一些特性,这些特性提供了通信的隐私性和机密性,以及参与者和媒体流的身份验证。它还描述了对系统的各种潜在攻击,以及如何预防这些攻击。
然而,这些并不是安全实现需要考虑的唯一问题;还必须确保会话启动和控制协议的安全。本章着重介绍了与这些启动和控制协议的安全性相关的一些问题,但是对这个主题的完整详细介绍超出了本书的范围。