第六章 媒体采集、播放和时序
- 发送者行为
- 媒体采集和编码
- RTP 包生成
- 接收者行为
- 包的接收
- 播放缓冲区
- 播放点自适应(adapting the playout point)
- 解码、混流(mixing)和播放
这一章我们不再讨论网络和协议,转入 RTP 系统设计。实现 RTP 需要兼顾很多功能,根据需求,有些是必须得,有些是可选得。本章主要讨论媒体采集、播放时序两个基本功能。后面章节描述了提高接收质量,减少资源开销的方法。
我们先讨论发送者的行为:媒体采集和编码、RTP 包封装以及底层的媒体时序模型。后面,主要讨论接收者,在不确定传输场景下,媒体播放以及时序恢复的问题。接收者最关键的部分是播放缓冲区是设计,本章的大部分内容都将集中在这方面的讨论。
需要牢牢记住的是,发送者和接收者在 RTP 的规范的允许下,实际可以有很多实现方案。这里讲的设计是其中一种考虑各种制约,折中的实现方案。实践中,应该根据特定的场景设计特定的方案(文献中描述了很多实现方案,例如:McCanne 和 Jacoboson 描述了一个RTP视频会议系统设计,这个设计有一定影响力)。
发送者的处理
如第一章 RTP 介绍中所述,发送者负责采集音视频数据(无论是实时采集还是来自文件),对音视频数据进行编码后封装 RTP 数据包传输。它还可以通过根据接收者反馈调整传输的媒体流的方式,进行纠错和拥塞控制。第一章中的图 1.2 显示了这个过程。
发送者首先将未编码的媒体数据 (音视频采样) 写入一个缓冲区,然后从中产生编码帧。帧数据可以用不同的编码算法进行编码,编码后的帧数据可能同时依赖之前和之后的数据。下一节,媒体的采集和编码,描述了这个过程。
被编码的帧会被分配一个时间戳和一个序列号,生成到 RTP 包,等待发送。如果一个帧信息太大,不能装到一个包中,它可能被分割成几个包进行传输。如果一个帧很小,可以将几个帧绑定到一个 RTP 包中。本章后面的《RTP 包的封装》一节,描述了这些功能,只有在有效负载(payload)支持的情况下,这两种功能才能实现。根据所使用的纠错方案,可以使用信道编码器来封装纠错数据包,或者在传输之前重新排序帧(第八章和第九章讨论了错误隐藏和错误恢复)。发送者将针对其封装的媒体流,以 RTCP 数据包的形式定期封装状态报告。发送者还将收到来自其他参与者的接收质量反馈,并可能使用这些信息来调整传输策略。RTCP 在第五章 RTP 控制协议中有详细描述。
媒体采集和编码
无论是传输音频还是视频,媒体采集过程在本质上是相同的:采集到未编码的数据,如果需要将其转换为合适的编码格式,然后调用编码器来封装编码帧。然后编码帧会传递到打包代码,并封装一个或多个 RTP 数据包。音视频采集相关的问题,将在接下来的两章中讨论,然后我么也会讨论对打包预先录制的内容所引发的问题。
音频的采集和编码
考虑到音频采集的特点,图 6.1 显示了在通用工作站上的采样过程:声音被采集、数字化并存储到音频输入缓冲区。输入缓冲区通常在收集到了固定数量的样本之后才能提供给上层逻辑。大多数音频采集 api 会以固定时长的帧,从输入缓冲区返回数据,直到采集足够的样本以形成完整的帧为止,在这个过程中 API 会被阻塞住。这会带来一些延迟,因为直到采样完最后一个样本(sample)之后,帧中的第一个样本才可用。如果我们可以选择,用于交互用途的应用程序,应选择最接近编码器一帧时长的缓冲大小(通常为 20ms 或者 30ms),来减少延迟。
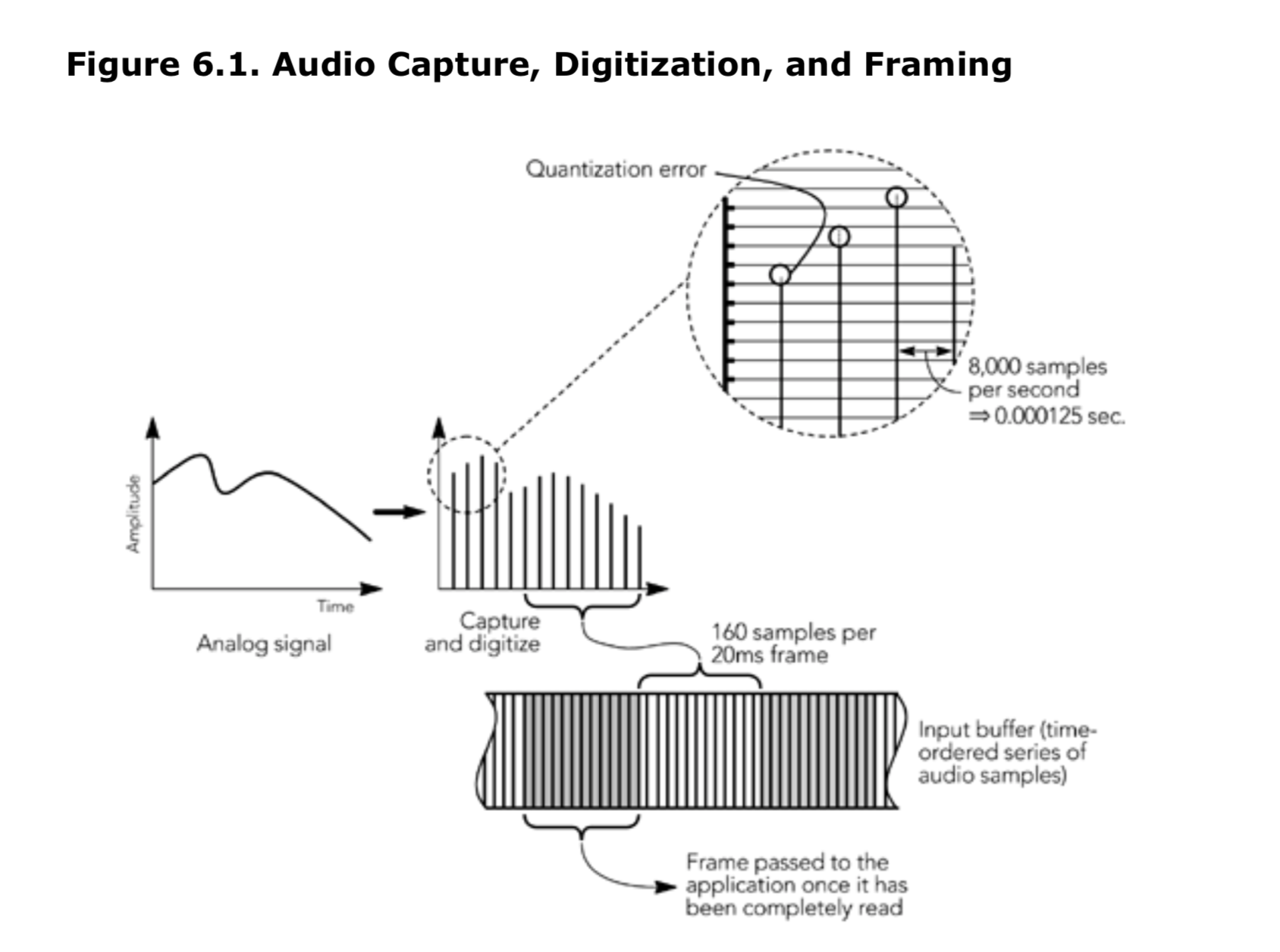
应用可以用不同的采样类型和采样率,从采集设备采集未编码的音频。常见的音频采集设备可以采样:
- 8bit、16bit或 24bit 的采样;
- 量化方式可以使用线性、μ-law 或 A-law,
- 采样率可以从 8000 到 96000 之间,
- 可以有单声道或多声道。根据采集设备的功能和编码器的不同, 在实际使用之前,还可以改变采样格式,例如更改采样率或更改量化方式从线性到 μ-law。转换音频格式算法,超出了本书的范围,标准的信号处理类书籍可以作为参考。
一种最常见的音频格式转换就是转换采样率,例如当采集设备是一个采样率,但是编码器设置的是另一种速率的时候(例如,该设备以 44.1KHz 固定速率运行,以支持高质量的 CD 播放,但是我们希望使用 8KHz 的语音编码进行传输)。虽说采样率可以直接以任意的数值进行转换,但是对于整数倍的采样率之间的转换,效率和准确度才是最高的。当选择音频硬件的采集模式时,应考虑采样率转换的计算要求。其他音频格式的转换,例如转换在线性量化和 μ-law 之间转换,开销会比较低,可以在软件中执行。
音频采样会传递到编码器进行编码。 根据编解码器的不同,状态可能会在帧(编码上下文)之间保持不变,必须与每个新的数据帧一起供编码器使用。 一些编解码器,尤其是音乐编解码器,其编码基于一系列未编码的帧,而不是孤立地基于未编码的帧。 在这些情况下,编码器可能需要传递几帧音频,或者可能在内部缓存帧并仅在接收到几帧后才产生输出。 一些编解码器会生成固定大小的帧作为其输出,产生可变大小的帧。 可变大小的帧通常根据所需的质量或信号内容从一组固定的输出速率中进行选择; 但是,实际上真正可变速率的很少。
许多语音编解码器通过静音抑制来执行语音活动检测,以检测和抑制仅包含静音或背景噪声的帧。 被抑制的帧不被发送,或者偶尔被低速率舒适噪声包所代替。 这样做可以大大节省网络流量,特别是如果使用统计多路复用的时候,则更能有效得利用有限容量的信道。
视频的采集和编码
通常,视频采集设备采集到是完整的视频帧,而不是返回逐行扫描线或隔行扫描的场。许多设备提供了以降低的分辨率对帧进行降采样或返回采集帧的子集的功能。帧可能具有一定分辨率的大小,并且采集设备可能会返回各种不同格式、颜色空间、深度和降采样的帧。
根据所使用的编解码器不同,可能需要先从采集格式转换编码器支持的格式,然后才能使用该帧的数据。 这种转换的算法不在本书的讨论范围之内,但是任何标准的视频信号处理书都将提供各种可能的方法,具体取决于所需的质量和可用资源。目前最常见的可能是在 RGB 和 YUV 颜色空间之间进行转换。 此外,色彩抖动和重采样也经常使用。 这些转换非常适合硬件加速,如许多处理器体系结构中存在的单指令多数据(SIMD)指令(例如,Intel MMX 指令,SPARC VIS 指令)。 图 6.2 说明了视频采集的过程,并以 YUV 格式采集的 NTSC 信号为例,在使用前将其转换为 RGB 格式。
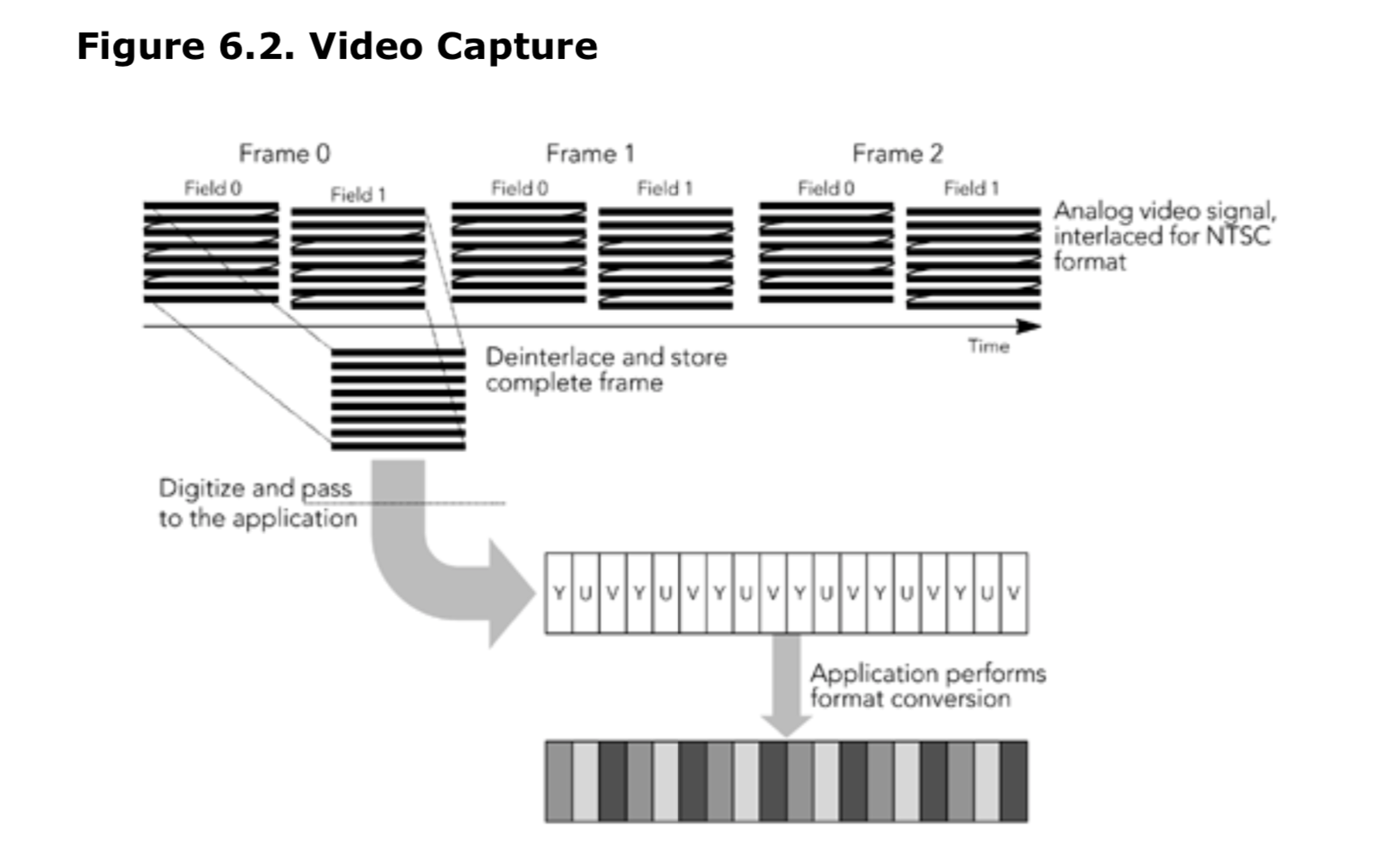
我们采集视频,加入缓冲区,然后再传递给编码器进行编码。缓冲区大小取决于编码方案;大多数视频编解码器使用帧间编码,每一帧都依赖于前后的帧。帧间编码可能需要编码器延迟特定的帧的编码,需要等待采集到它所依赖的帧为止。编码器将在帧之间维护状态信息,该信息必须与视频帧一起提供给编码器。
对于音视频,采集设备都可以直接产生编码媒体,而不是分为单独的采集和编码阶段。 这在专用硬件上很常见,但是某些视听工作站也具有内置编码功能。 以这种方式工作的采集设备可简化 RTP 实现,因为 RTP 实现的时候不需要包括单独的编解码器了,但是它们可能将适应范围限制为时钟偏移(clock skew)和/或网络抖动,如本章稍后所述。
无论媒体类型是什么以及如何编码,采集和编码阶段的产出都是一系列编码帧,每个编码帧都有关联的采集时间。 这些帧被传递到 RTP 模块,以进行打包和传输,如下一节《RTP 包的封装》所述。
使用预先录制的内容
从预先录制和编码的内容文件流式传输时,媒体帧将以与直播内容几乎相同的方式传递到打包程序。 RTP 规范没有区分直播媒体和预录媒体,发送者无论如何封装帧,都以相同的方式从编码帧解封装为数据包。
特别是,当开始流式传输预先录制的内容时,发送者必须生成新的 SSRC,并为 RTP 时间戳和序列号选择随机初始值。 在流传输过程中,发送者必须准备处理 SSRC 冲突,并且应生成并响应该流的 RTCP 包。 另外,如果发送者实现了控制协议(例如 RTSP),允许接收者在媒体流中暂停或查找(seek),则发送者必须跟踪此类交互,以便可以将正确的编号和时间戳插入 RTP 数据包中(这些问题在第 4 章《RTP 数据传输协议》中讨论过了)。
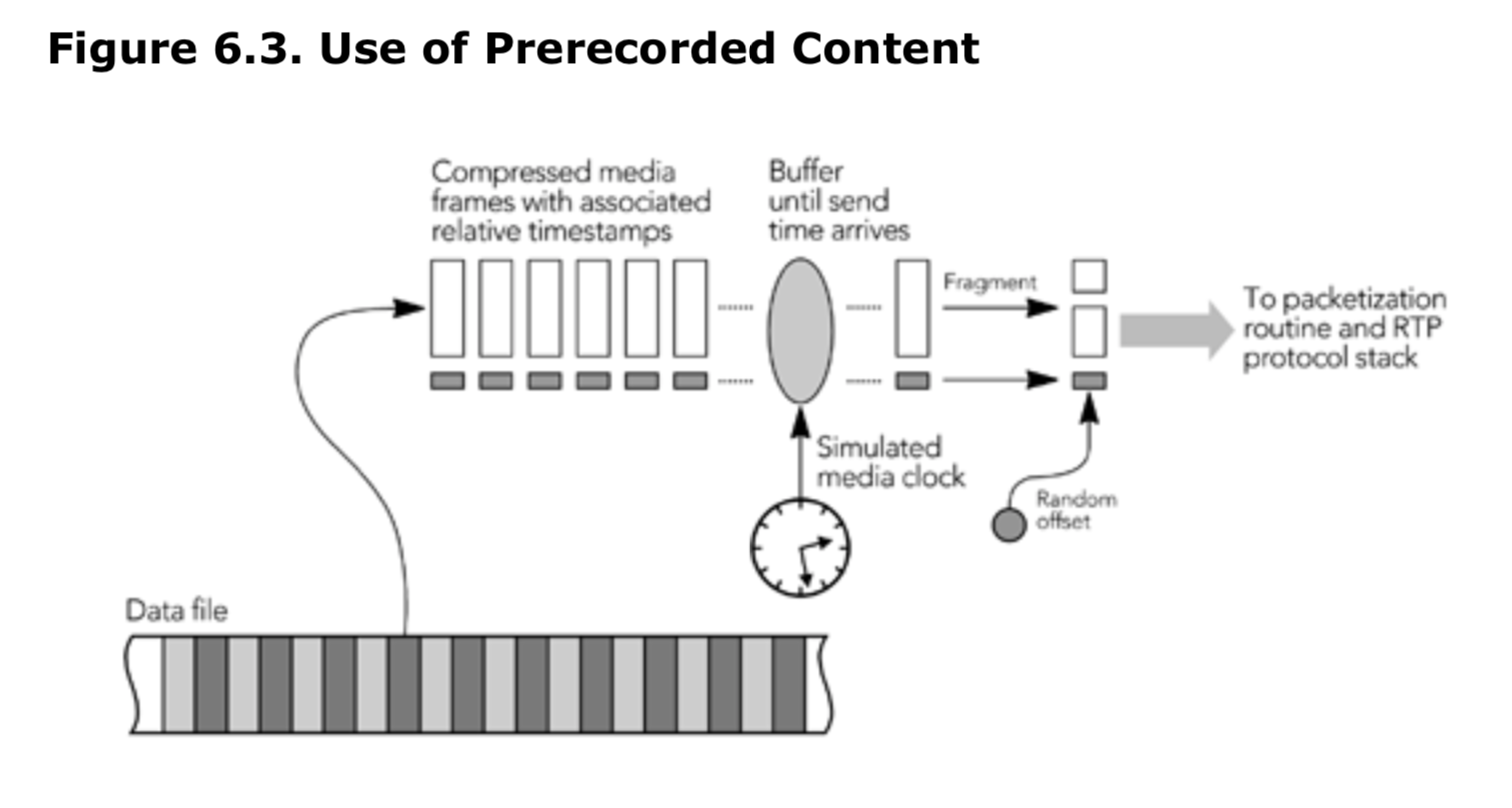
需要实现 RTCP,并确保序列号和时间戳正确,这意味着发送者不能简单地将完整的 RTP 数据包存储在文件中,也不能直接从文件流式传输。 相反,如图 6.3 所示,必须实时存储和打包媒体数据帧。
封装 RTP 包
生成编码帧后,会将它们传递到 RTP 打包程序。 每个帧都有一个关联的时间戳,可从中导出 RTP 时间戳。 如果有效负载格式支持分段,则将过大的帧分段以适合网络的 MTU(通常仅视频需要)。最后,为每个帧生成一个或多个 RTP 数据包,每个数据包都包括媒体数据和任何所需的有效负载头。 媒体数据包和有效负载头的格式是根据所用编解码器的有效负载格式规范定义的。数据包生成过程的关键部分是为帧分配时间戳,分割过大的帧以及生成有效负载包头。在以下各节中将更详细地讨论这些问题。
除了直接表示媒体帧的 RTP 数据包之外,发送者还可以生成纠错包,并可以在传输之前对帧进行重新排序。 这些过程在第 8 章《错误隐藏》和第 9 章《错误恢复》中进行了描述。 在发送 RTP 数据包之后,与这些数据包相对应的缓冲媒体数据最终将被清空。 发送者不得丢弃纠错或编码过程中可能需要的数据。此要求可能意味着发送者必须在发送完相应的数据包后将数据缓冲一段时间,具体取决于所使用的编解码器和纠错方案。
时间戳与 RTP 的时序模型
RTP 时间戳表示帧数据第一个比特位的采样时刻(sampling instant)。它从一个随机初始值开始,速率递增和媒体类型相关。
在采集实时媒体流期间,采样时刻就是从视频帧采集器或音频采样设备采集媒体的时间。如果要同步音视频,必须确保考虑了不同采集设备中的处理延迟。对于大多数音频有效负载格式,每帧的 RTP 时间戳增量等于从采集设备读取的样本数量。MPEG 音频,包括 MP3,它使用 90kHz 媒体时钟,以与其他 MPEG 内容兼容。对于视频,根据时钟和帧速率,对于采集的每个帧,RTP 时间戳都会以标称的每帧值递增。 大多数视频格式使用 90kHz 时钟,因为这样可以为常见的视频格式和帧速率提供整数时间戳记增量。 例如,如果使用带有 90kHz 时钟的有效负载格式以每秒(大约)29.97 帧的 NTSC 标准速率发送,则 RTP 时间戳将每个数据包增加 TexactlyT 3003。
对于从文件流式传输的预录制内容,时间戳给出了播放序列中帧的时间,加上一个恒定的随机偏移量。 如第 4 章《RTP 数据传输协议》所述,从中导出 RTP 时间戳的时钟必须以连续和单调的方式增加,不需要考虑查找(seek)操作或播放中的暂停。 这意味着时间戳并不总是对应于帧从文件开始的时间偏移; 而是以自播放开始以来的时间轴为测量基准。
时间戳是按帧分配的。 如果将一个帧分成多个 RTP 数据包,那么组成该帧的每个数据包都将具有相同的时间戳。
RTP 规范不保证媒体时钟的分辨率、准确性或稳定性。发送者负责选择合适的时钟,并为所选应用提供足够的准确性和稳定性。接收者知道标称时钟速率,但通常不了解时钟精度。除非应用程序具有相反的特定知识,否则应用程序在发送者和接收者都应对媒体时钟的可变性具有鲁棒性。
RTP 数据包和 RTCP 发送者报告中的时间戳表示发送者媒体的时序:采样过程的时序以及采样过程与参考时钟之间的关系。 接收者期望根据该信息来重建媒体的时序。 请注意,RTP 时序模型没有说明何时播放媒体数据。 数据包中的时间戳给出了相对时序,RTCP 发送者报告提供了流间同步的参考,但 RTP 并未说明接收者可能需要的缓冲量或包的解码时间。
尽管很好地定义了时序模型,但 RTP 规范并未提及用于重建接收者时序的算法。这是有意为之的:播放算法的设计取决于应用程序的需求,按需实现。
分段 Fragmentation)
超出网络最大传输单位(MTU)的帧必须在传输之前分成几个 RTP 数据包,如图 6.4 所示。每个分段都有该帧的时间戳,并可能有一个额外的有效负载包头来描述分段。
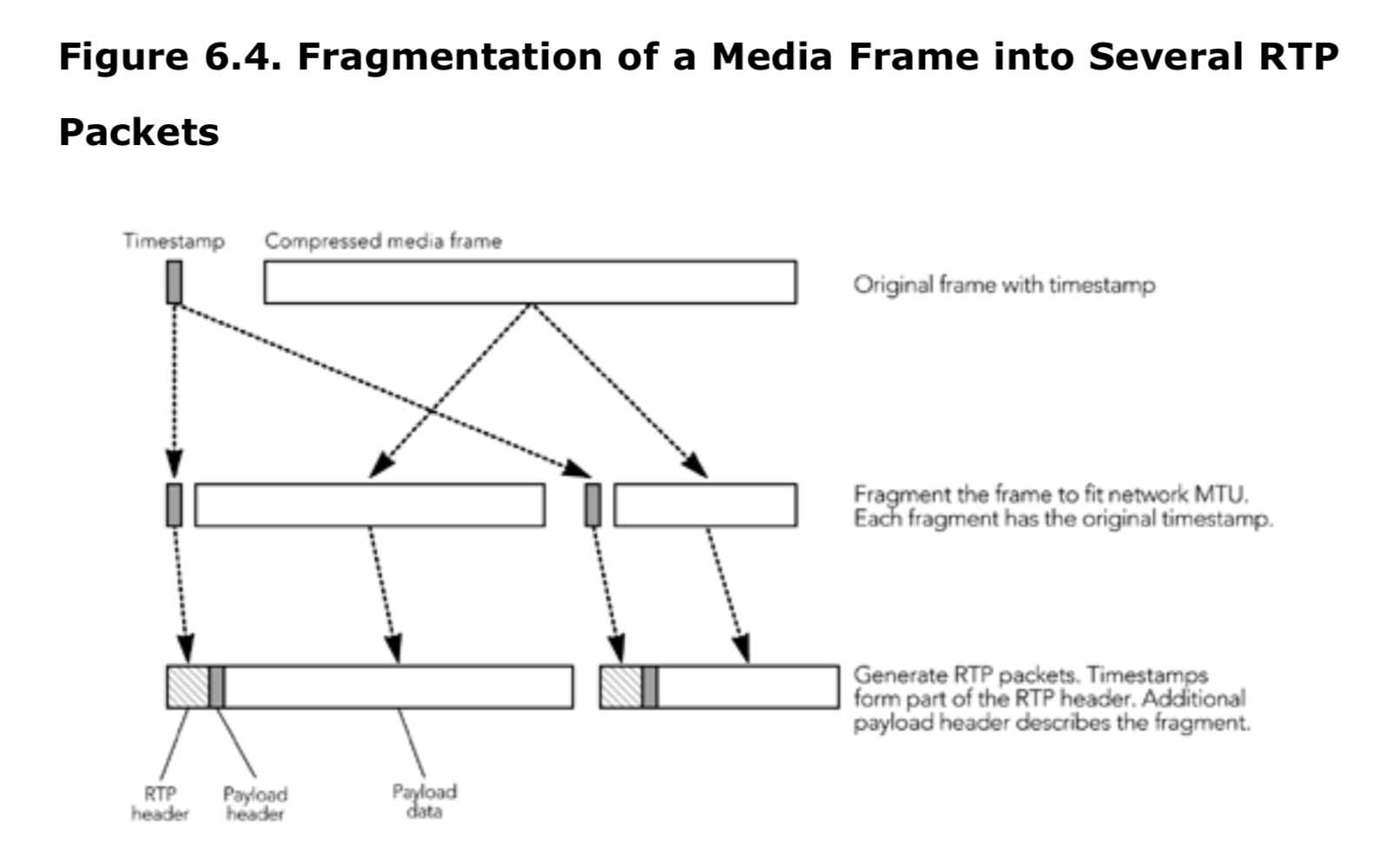
在丢包的情况下,分段的处理对媒体质量至关重要。最理想的情况是独立解码每一个分段。否则单个分段的丢失会将导致整个帧都被丢弃, 这是我们不希望看到的。可能需要在分段的时候制定一些规则,根据这些规则,负载数据可以在适当的位置做分割,并加上负载头,以帮助接收者在某些片段丢失的情况下还可以使用。这些规则需要编码器的支持,以生成既符合有效负载格式的打包规则又适合网络 MTU 的片段。
如果编码器不能生成适当大小的片段,发送者可能必须使用任意的片段。可以通过 RTP 层上的应用程序或使用 IP 分段的网络来实现分段。如果丢失了任意分段的帧的某些片段,则很可能必须丢弃整个帧,从而大大降低质量(Handley 和 Perkins 更详细地描述了这些问题)。
当为每帧封装多个 RTP 包时,发送者必须在以下方式中选择其一:一次性发送数据包(sending the packets in single burst)还是拆分后的多个数据包分散开传输在帧间隔中。一次性发包会减少端到端的延迟,但是可能会超出网络或接受主机的缓冲区大小。出于这个原因,一般都是选择发送者在帧间隔内及时分发包。无论是否存在其他的场景,这对于发送者,特别是高速发送者,这都是非常重要的办法。
负载的格式-特殊的头信息
除了 RTP 报头和媒体数据之外,包通常还包含一个额外的特定于负载的包头。此包头由使用中的 RTP 有效负载格式规范定义,并在 RTP 和编解码器之间,提供了一个适配层。
有效负载包头的典型用法是使编解码器(该编解码器不适合在有损数据包网络上使用)在 IP 上工作,以提供错误恢复能力或支持分段。精心设计的有效负载包头可以大大提高有效负载格式的性能,实现者应注意以正确生成这些包头,并使用提供的数据来修复接收者丢包的影响。
在第四章《RTP 数据传输协议》中,“负载头信息”这一节详细讨论了有效负载头的使用。
接收者的处理
正如第一章《RTP 介绍》中所强调的,接收者负责从网络中读取 RTP 数据包,修复丢失的数据包,恢复时序,解码媒体,并将结果呈现给用户。此外,接收者需要发送接收质量报告,以便发送者能够根据网络特性调整传输策略。接收者通常还将维护会话中的参与者数据库,以便能够向用户提供其他参与者的信息。第一章的图 1.3 显示了接收者的框图。
接收过程的第一步是读取来自网络的数据包,验证数据包的正确性,并将它们插入到发送者对应的缓存队列中。这流程并不复杂,媒体格式无关。下一节 包接收将描述这个过程。
接收方的后续操作针对每个发送方,并且与传输的媒体类型有关。数据包从缓冲队列中取出,如果实现了信道编码,则会将数据包放入信道编码队列以纠正丢包。当接收到完整的帧后,数据包会被插入到与数据源相关的播放缓冲区中,以平滑处由于网络引起的数据包间到达时序的变化。计算出适当的缓冲延迟是一个关键的技术问题,该部分在本章后面的“播放缓冲区”一节中进行了详细解释。本章的“调整播放点”一节描述了如何在不中断媒体播放的情况下调整时序。
在达到播放时间之前,数据包被组合成完整的帧。使用在第8章中描述的算法修复损坏或丢失的帧,然后进行解码。最终,媒体数据将被呈现给用户。根据媒体格式和输出设备的不同,单独播放每个流,例如在各自的窗口中显示多个视频流。或者说,可能需要将所有来源的媒体混合成一个单一的流进行播放,例如将多个音频来源混合后通过一套扬声器播放。本章的最后一节“解码、混音和播放”描述了这些操作。
RTP 接收者的实现相比于发送者的实现更为复杂。这种复杂性的增加,很大程度上是因为 IP 网络的固有变化造成的(丢包补偿和时序恢复)。
数据包接收
RTP 会话由数据流和控制流组成,在不同的端口上运行(通常数据包在偶数端口上运行,控制数据包在下一个奇数端口上运行)。这意味着接收应用程序为每个会话打开两个套接字:一个用于数据,一个用于控制。因为 RTP 运行在 UDP/IP 之上,所以使用的套接字是标准的 SOCK_DGRAM 套接字,就像类似于 unix 上的 Berkeley sockets API 或者 Microsoft 平台上的 Winsock 所提供的那样。
一旦创建了套接字,应用程序就应该准备接收来自网络的数据包,并将它们存储起来以便进一步处理。许多应用程序将其实现成一个循环,反复调用 select()来接收包 -- 例如:
fd_data = create_socket(...);
fd_ctrl = create_socket(...);
while (not_done)
{
if (FD_ISSET(fd_data, &rfd))
{
...validate data packet
...process data packet
}
if (FD_ISSET(fd_ctrl, &rfd))
{
...validate control packet
...process control packet
}
}
如第四章《RTP 数据传输协议》和第五章《RTP 控制协议》所述,对数据和控制包进行校验,之后按照后面两节所述进行处理。select()操作的超时,通常是根据媒体的帧间隔配置。例如,接收 20 毫秒音频数据包需要设置 20 毫秒的超时时间,从而允许其他处理(例如解码接收到的数据包), 并实现播放同步进行,所以应用程序每 20 毫秒循环一次。
接收者其他模块的实现是根据事件驱动或者轮训,但基本概念保持不变:数据包在从网络接收时持续进行验证和处理,其他模块的处理需要与之并行(可以是显式的时间片轮询,,或作为独立的线程运行),根据媒体处理的需求来编排媒体时序。对于RTP接收方来说,实时操作非常关键;数据包必须按照到达的速度进行处理,否则接收质量将受到影响。
数据包的接收
媒体播放过程的第一阶段是从网络获取 RTP 数据包,加入缓冲,进行处理。由于网络运用,到达时序很难保证,如图 6.5 所示会出现多个数据包同时到达或没有数据包到达的时间片,甚至可能出现数据包乱序的情况。接收方并不知道数据包何时到达,因此需要准备好在任何时间以任何顺序接收数据包。
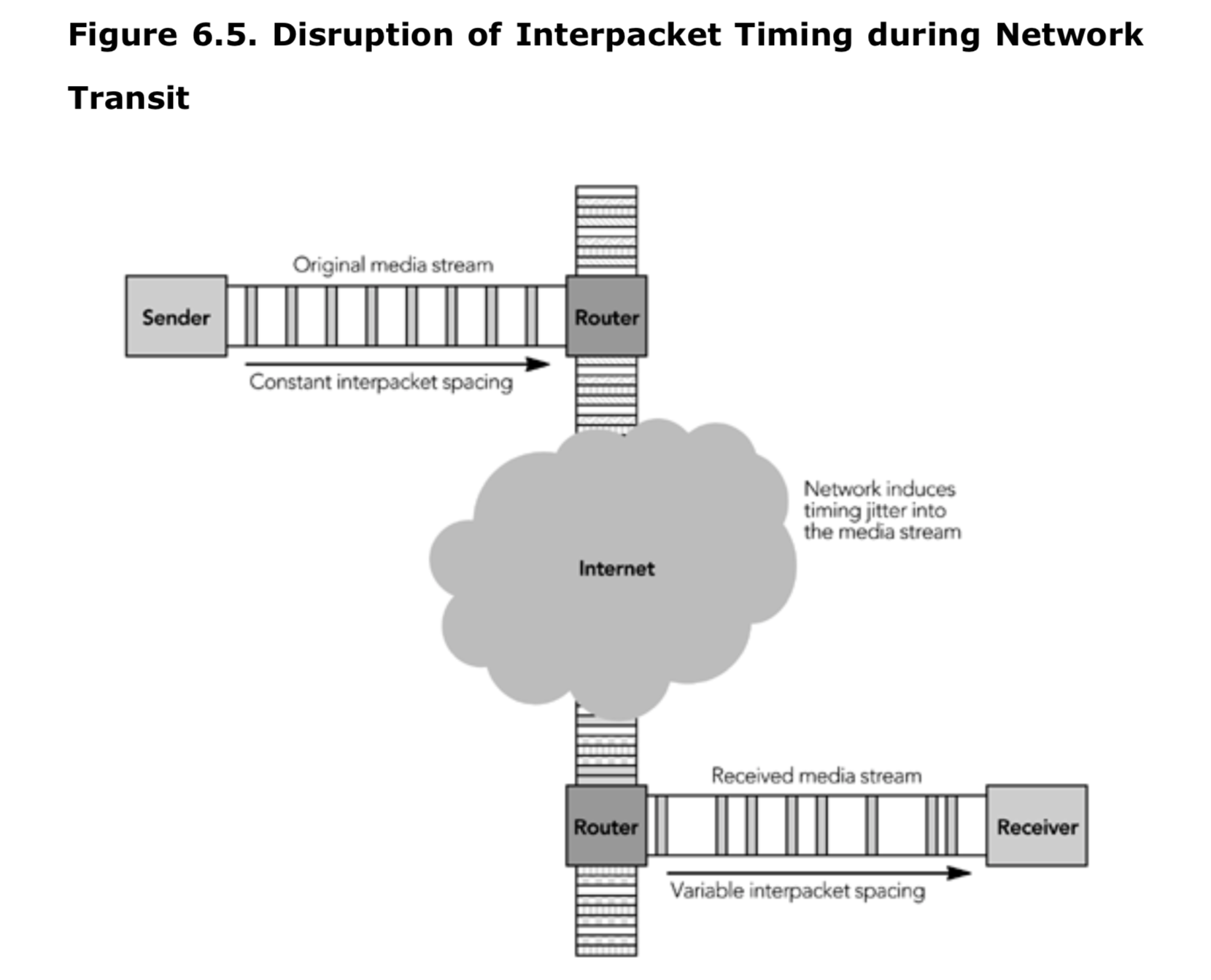
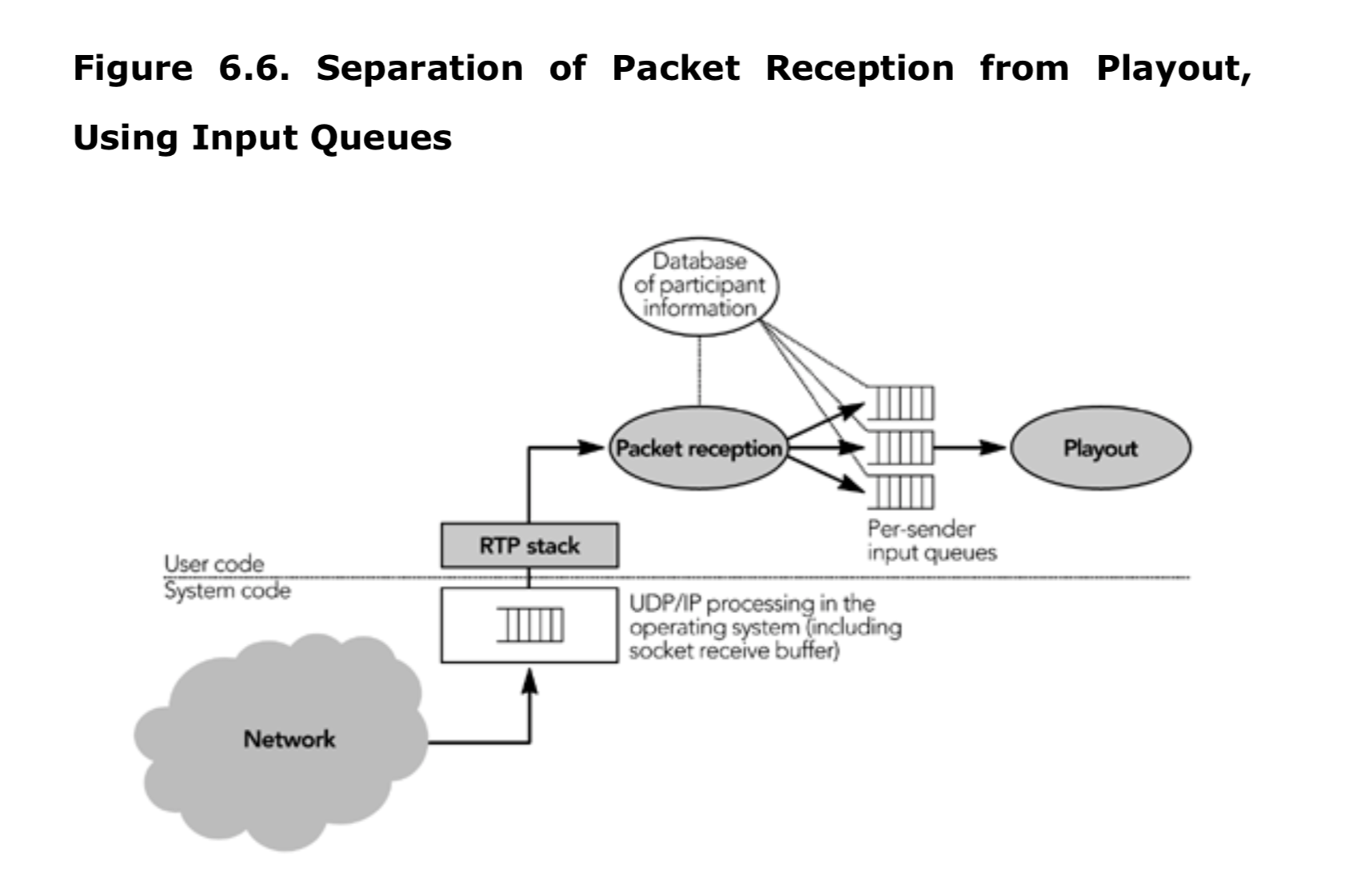
接收到数据包后,进行正确性校验,记录到达时间,并按照 RTP 时间戳排序,然后将数据包添加到每个发送者的输入队列中,以供以后处理。这些步骤可以将数据包的到达速率与处理和播放分离,应对到达速率的变化。图 6.6 显示了数据包接收和播放程序之间的分离,二者仅由输入队列串联。
准确到记录RTP数据包的到达时间对于计算抖动非常重要。如果达时间测量不准确 ,会让网络抖动看起来更严重,并导致播放延迟增加。到达时间应该基于本地参考时钟T进行测量,并转换为媒体时钟速率R。由于接收方通常没有这样的时钟,所以通常我们通过采样参考时钟(通常是系统墙钟时间)并将其转换为本地时间轴来计算到达时间:
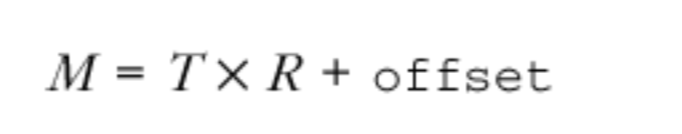
在校正媒体时钟和参考时钟之间的偏差的过程中,使用 offset 从参考时钟映射到媒体的时间线。
如前所述,数据包的处理可以在单线程的应用程序中与数据包接收一同处理,按时间片隔离,或者可以在单独线程中运行。在时间片设计中,单个线程同时处理数据包接收和播放操作。在每个循环中,所有未完成的数据包都会从套接字中读取并插入到输入队列中。根据需要,数据包会从队列中移除并进行播放。如果数据包以突发形式到达,一些数据可能会保留在输入队列中,需要多次循环才能处理完全,具体取决于所需的播放速率和处理效率。
通常,多线程接收者有一个线程在套接字上等待数据到达,将到达的数据包放入输入队列进行排序。其他线程从输入队列中提取数据,并进行解码和播放媒体。线程的异步操作,以及输入队列中的缓冲,有效地将播放过程与输入速率的短期波动解耦,使得播放过程不受输入速率短期变化的影响。
无论选择那种设计,应用程序通常无法持续接收和处理数据包。输入队列可以处理放过程中的波动,但是对于数据包接收过程的延迟呢?幸运的是,大多数通用操作系统以中断驱动的方式处理UDP/IP数据包的接收,并且即使应用程序处于busy状态,也可以在套接字层面缓冲数据包。这种能力在数据包到达应用程序之前提供了有限的缓冲。默认套接字缓冲区能适配大多数场景,但是接收高速流或长时间无法处理接收可能需要增加套接字缓冲区的大小,增加默认值(在许多系统上,setsockopt(fd, SOL_SOCKET, SO_RCVBUF, ...)函数)。较大的套接字缓冲区可以容纳数据包接收处理中的变化延迟,但是数据包在套接字缓冲区中停留的时间在应用程序中表现为网络抖动。应用程序可能会增加其播放延迟以弥补这种感知上的变化。
接收控制包
在数据包到来的同时,应用程序必须准备接收、校验、处理和发送 RTCP 控制包。RTCP 包中的信息用于维护会话内发送者和接收者的数据库,如第五章《RTP 控制协议》中所讨论的,主要用于参与者校验和识别、适应网络条件和音视频同步。参与者数据库也是挂起参与者特定的输入队列、播放缓冲区和接收者需要的其他状态的好地方。
单线程应用程序通常在 select()循环中同时包含数据和控制套接字,从而将控制数据包的接收和其他处理交织在一起。多线程的应用程序可以将一个线程用于 RTCP 接收和处理。由于与数据包相比,RTCP 包很少出现,因此它们的处理开销通常比较低,而且对时间要求不是特别严格。但是,记录发送报告(SR)数据包的确切到达时间非常重要,因为这个值在接收者报告(RR)数据包中返回,用于计算往返时间。
当 RTCP 发送者/接收者报告包到达时(描述在特定接收者处看到的接收质量),将存储它们包含的信息。解析 SR/RR 包中的报告块很简单,只要你记住数据是按照网络字节顺序进行排列的,在使用之前必须将其转换为主机的顺序。RTCP 包头中的 count 字段表示有多少报告块;请记住,0 是一个有效值,表示 RTCP 包的发送者没有接收到任何 RTP 数据包。
RTCP的发送者/接收者报告主要用于应用程序监视其发送的流的接收情况。如果报告显示接收情况不佳,应用程序可以采取一些措施,如添加错误保护或降低发送速率来进行补偿。在多发送者会话中,还可以监视其他发送者的质量。例如,网络操作中心可以通过监视SR/RR数据包来检查网络是否正常运行。应用程序通常会在接收时存储接收质量数据,并定期使用这些存储的数据来适应其传输。
发送者报告还包含 RTP 媒体时钟和参考时钟之间的映射(用于音视频同步),以及发送数据量的计数。同样,这些信息是按照网络字节顺序排列的,在使用前需要进行转换。如果用于音视频同步的目的,那么需要存储下来。
当 RTCP 源描述包到达时,它们包含的信息被存储并可能显示给用户。RTP 规范包含用于解析 SDES 数据包的示例代码(参见规范的附录 A.5)。SDES CNAME(规范名)提供音视频流之间的关系,表明那些流需要同步。RTCP 源描述包还用于对来自单个源的多个流进行分组(例如,如果一个参与者有多个摄像头向一个 RTP 会话发送视频),这可能会影响向用户显示媒体的方式。
在验证RTCP数据包后,其中包含的信息将被添加到参与者数据库中。由于对RTCP数据包进行了强大的有效性检查,因此数据库中存在的参与者可以可靠地表明其有效性。这对于验证RTP数据包非常有用:如果之前在RTCP数据包中看到过RTP数据包中的SSRC(同步源标识符),那么该SSRC很可能是一个有效的数据源。
当接收到RTCP Bye包时,参与者数据库中的条目将被标记为稍后删除。根据《RTP控制协议》第五章的描述,当收到Bye包时,RTP控制协议不会立即删除条目,而是保留一段时间,以允许延迟的数据包到达。在我的实现中,我使用了一个固定的两秒超时,具体的值并不重要,只要它大于典型的网络抖动即可,接收者还会定期执行清理工作,以便将不活跃的参与者标记为超时。这个操作不需要针对每个,每个RTCP报告间隔执行一次就足够了。
播放缓冲区
数据包从其输入队列中提取出来,插入播放缓冲区中 ,缓冲区里面的 RTP 包根据时间戳排序。帧会被保存在播放缓冲区一段时间,来平滑网络引起的时间变化。将数据保存在播出缓冲区中还可以接收分段帧的分段并进行分组,并且可以允许任何纠错数据到达。然后解码帧,隐藏任何剩余的错误,并且为用户做展现。图 6.7 说明了该过程。
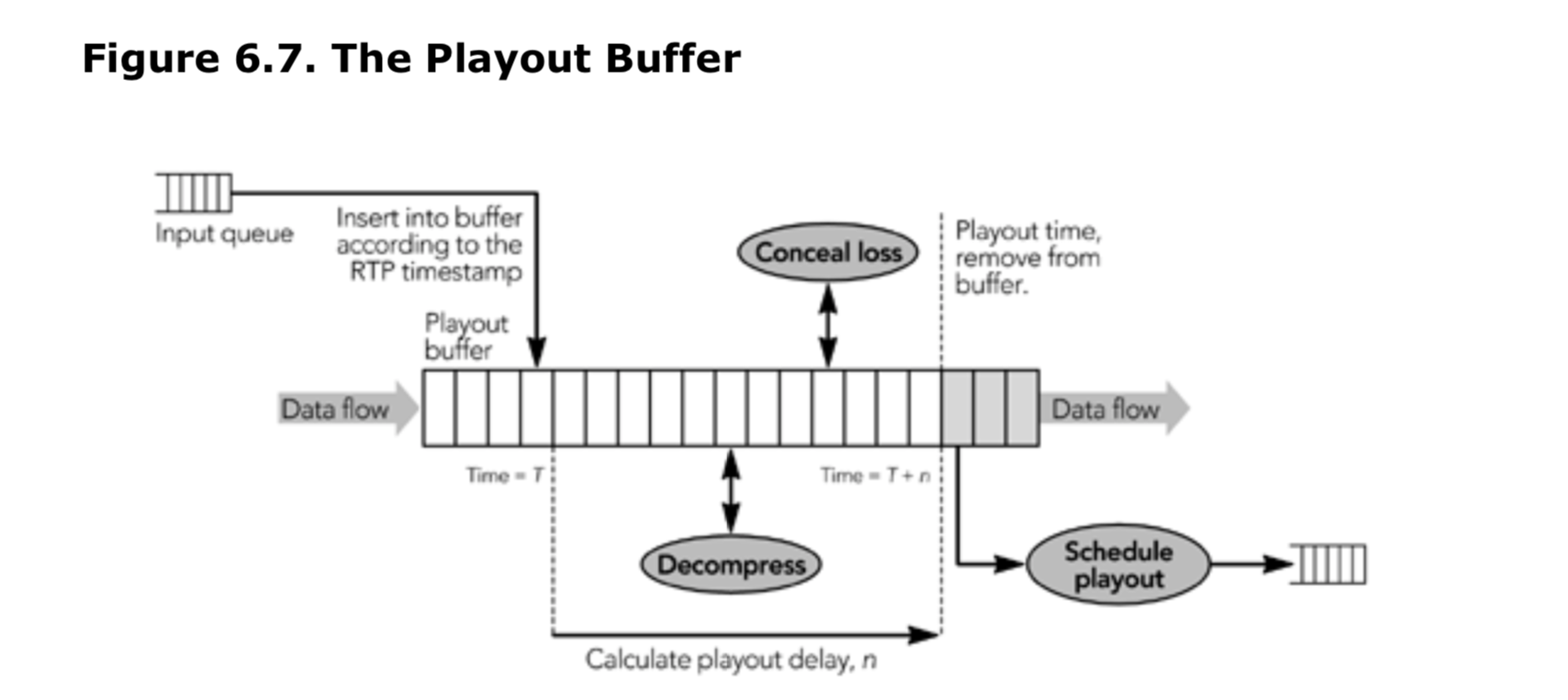
单个的缓冲区可以用来补偿网络到达时间的变化,并作为解码缓冲区的媒体解码器。也可以分离这些功能:使用单独的缓冲区进行抖动消除和解码。在 RTP 中从来没有严格的分层要求:高效的实现常常应该跨越层的边界混合相关功能,这就是“集成层处理”(integrated layer processing)的概念。
基础操作
播放缓冲区包含一个按时间序列排列的链表。每个节点代表一帧及时序信息。每个节点的数据结构包含指向相邻节点的指针、到达时间、RTP 时间戳和播放时间,以及指向帧的编码片段(RTP 包接收的数据)和未编码的媒体数据的指针。图 6.8 说明了所涉及的数据结构。
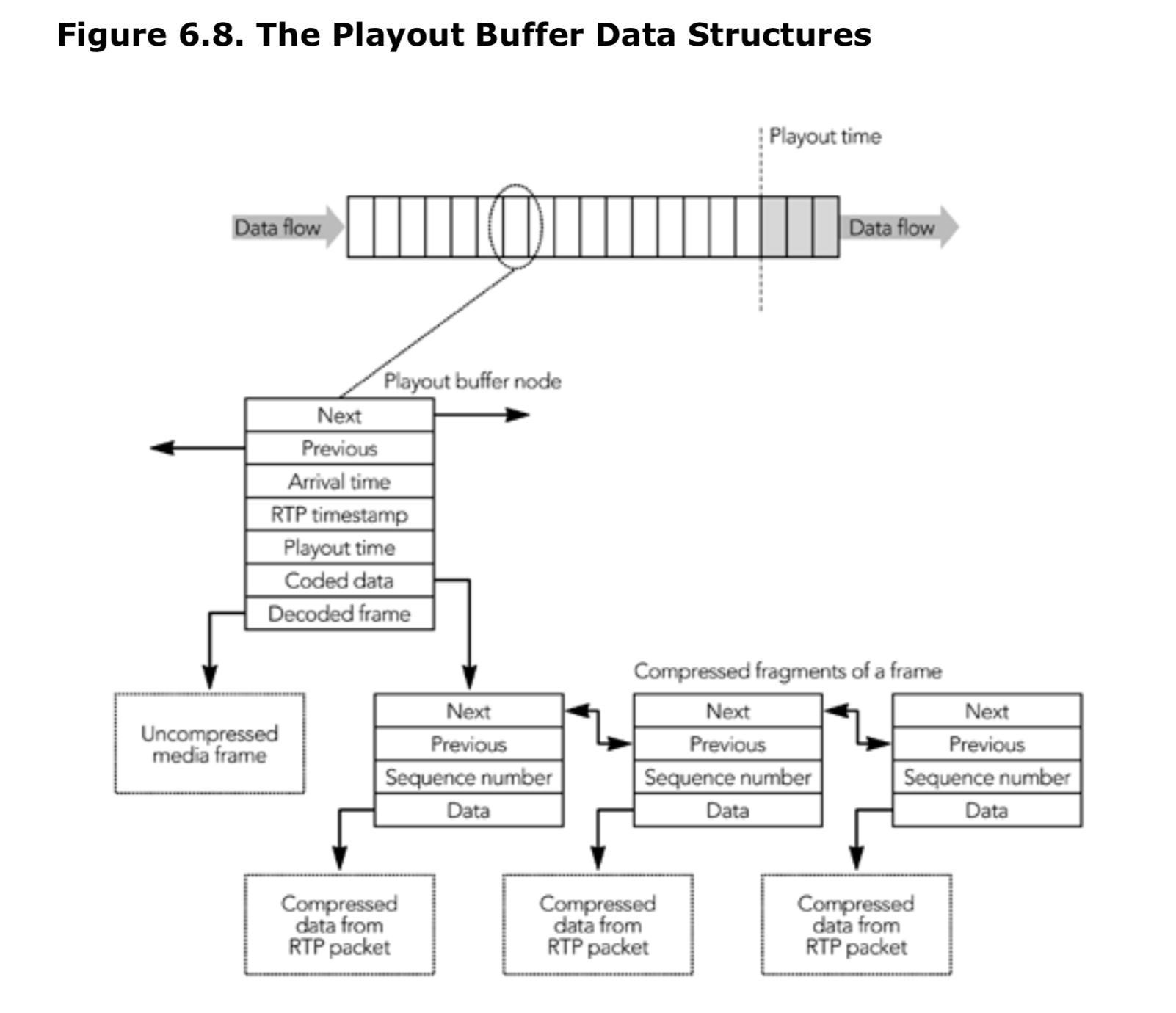
当一帧中的第一个RTP包到达后,把这帧的数据包从输入队列中移除,并按照RTP时间戳的顺序,保存在播放缓冲区中。这需要创建一个新的播放缓冲区节点,并将其插入到播放缓冲区的链表中。最近到达的数据包中的压缩数据与播放缓冲区节点进行链接,以便稍后进行解码。最后,根据本章后面解释的方法计算出该帧的播放时间。
新创建的节点驻留在播放缓冲区中,直到达到播放时间为止。在此期间,包含帧的其他片段的包,可能到达并从此节点链接。一旦确定已接收到帧的全部片段,就会调用解码器,并从播放缓冲区节点链接封装未编码的帧。如何确定是否收到一个完整的帧取决于编码器:
- 音频编码器通常不分段帧,每帧只有一个包(mp3 是常见的例外)
- 视频编解码器通常为每个视频帧封装多个包,并设置 RTP 标记位来指示包含最后一个分段的 RTP 包。
接收到设置了标记位的视频数据包并不意味着已经接收到完整的帧,因为数据包可能会在传输过程中丢失或重新排序。相反,它提供了帧的最高RTP序列号。要确定帧是否完整,需要接收到所有具有相同时间戳但序列号较低的RTP数据包。如果接收到带有前一帧标记位的数据包,则可以轻松确定该帧是否完整。如果该数据包丢失(例如没有收到标记位但时间戳发生了改变),并且根据序列号只丢失了一个数据包,则丢失的包后面的第一个数据包将是帧的第一个数据包。如果丢失了多个数据包,则通常无法确定这些数据包是属于新帧还是前一帧(在某些情况下,媒体格式可以确定帧的边界,但这取决于编解码器和有效负载格式)。
何时调用解码器的决定取决于接收方,而不是协议规定。数据帧可以在完整到达后立即解码,也可以保持压缩状态直到最后一刻再解码。在需要在处理效率以及缓存的空间之间权衡。例如,如果接收方知道关键帧即将到来,接下来会有大量计算,可能会提前解码数据。
最终,如果帧的到了播放时间,帧将排队等待播放,如本章后面的《解码,混流和播放》部分所述。 即使在等待播放的帧尚未解码时,即使某些分片丢失,接收者也必须尽最大努力解码该帧,因为这是解码该帧的最后机会。同时,这也是调用错误隐藏(请参阅第8章)来纠正的数据包丢失的时间。
一旦帧播放完,相应的播放缓冲区节点,及其关联的数据应该被销毁或回收。但是,如果使用了错误隐藏,则最好将此过程延迟到周围的帧也完成之后,因为相关的媒体数据可能对隐藏操作有用。
应该丢弃那些延迟到达的数据包,延迟到达的数据包指错过播放时间的数据包。数据包是否即使到达,可以通过比较当前数据包的时间戳和播放缓冲中,最旧的数据包的时间戳来完成(注意,比较应该使用模运算,兼容时间戳的翻转场景)。显然,应该选择适当的播放延迟,以使延迟数据包的出现的概率,应用程序应该监控延迟数据包的数量,并准备根据情况调整播放延迟。延迟数据包表明播放延迟需要调整,数据包到达延迟通常是由于网络延迟或发送者和接收主机之间时钟偏差的变化所致。
播放缓冲区需要在保真度和延迟之间做权衡:应用程序必须确定可以接受的最大播放延迟。为交互式系统 -- 例如,视频会议或电话 -- 必须尽量减少播放延迟,因为它无法承受缓冲带来的延迟。对人类感知能力的研究表明,互动的最大可容忍的往返时间限制在 300ms 左右。如果系统是对称的,则该限制意味着只有 150 毫秒的端到端延迟,包括网络传输时间和缓冲延迟。然而,非交互式的系统,如流视频、电视或广播,可能允许播放的缓冲区增长到几秒,从而使非交互式系统能更好的处理包到达的时间。
计算播放时序
设计 RTP 播放缓冲区的最大难点是确定播放延迟,在播放之前,数据包应该在缓冲区中停留多长时间?答案取决于多种因素:
- 接收帧的第一个和最后一个数据包之间的延迟
- 接收任何纠错数据包之前的延迟(见第九章《错误恢复》)
- 由于网络抖动和路由更改导致的数据包间的时序变化
- 发送者和接收者之间的相对时钟偏移(skew)
- 应用程序的端到端之间延迟预测,以及接收质量和延迟的相对重要性。
发送端可以控制帧内数据包之间的延迟,以及数据包和纠错包之间的延迟。这些因素对播放延迟计算的影响在本章后面的“发送方行为的HTU补偿”一节中有详细讨论。
应用程序无法控制的因素包括网络的行为以及发送方和接收方时钟的准确性和稳定性。以图6.9为例,该图显示了一组RTP音频数据包的传输时间和接收时间之间的关系。如果发送方和接收方的时钟以相同的速率运行,就如期望的那样,这个图的斜率应该恰好为45度。但实际上,发送方和接收方的时钟通常无法同步,运行速率也会略有差异。在图6.9中,发送方的时钟比接收方的时钟运行得更快,因此图的斜率小于45度(这个图是为了更容易看到效果而极端化的例子;通常情况下,斜率会更接近45度)。本章后面的“时钟偏差的补偿”一节将详细解释如何纠正不同步的时钟。
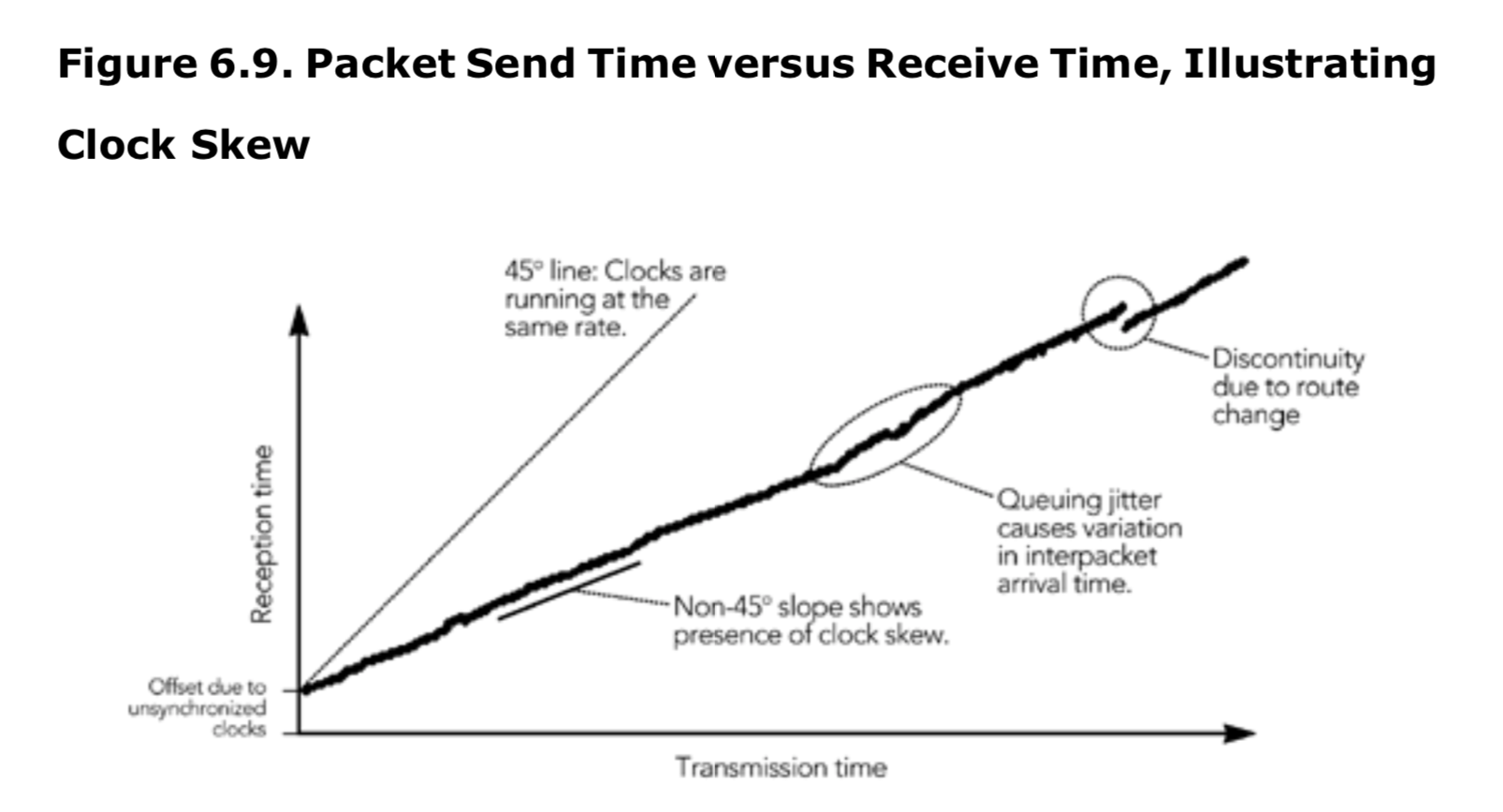
如果数据包具有恒定的网络传输时间,图6.9中将呈现出完全直线。然而,通常由于排队延迟的变化,网络会引入一些抖动,导致数据包之间的间隔波动,这在图中可以看到,呈现出与直线图的偏离。图中还显示了一个不连续点,这是由于网络传输时间发生了突变,很可能是由于网络中的路由变化引起的。HTU第2章《数据包网络上的语音和视频通信》详细讨论了这些影响,本章后面的“抖动的HTU补偿”一节解释了如何纠正这些问题。如何纠正更极端的变化在“路由变化的HTU补偿”和“数据包重排序的HTU补偿”这两节中进行了讨论。
最后需要考虑的是端到端延迟的容忍阈值。这主要取决于个人因素:对于用户来说,他们能够接受的最大端到端延迟是多少?在网络传输时间被排除后,用于平滑播放缓冲的剩余时间是多少?显然,可用于缓冲的时间会影响播放缓冲的设计。本章后面的"抖动的补偿"一节进一步讨论了这个问题。
在决定每一帧的播放时间的时候,接收者应该上面的因素。所以对播放的计算步骤如下:
- 发送者的时间轴映射到本地播放时间轴,以补偿发送者和接收者时钟之间的相对偏移,以导出播放时间计算的基准时间(请参考本章后面的映射到本地时间轴)。
- 如果有必要,接受者可以通过添加一个偏移补偿偏移来补偿相对发送者的时钟,该偏移会定期校准基准时间(参见时钟偏移补偿)。
- 本地时间轴上的播放延迟是根据播放延迟中与发送者相关的部分(参考“发送者行为的补偿”)和与抖动相关的部分(请参见“抖动补偿”)计算的。
- 如果路由发生了变化(参见路由变化的补偿),如果包被重新排序(参见排序的补偿),如果选择的播放延迟导致帧重叠,或者相应媒体中其他的变化(参见调整播放点),则会调整播放延迟。
- 最后,将播放延迟添加到基准时间中,以获得帧的实际播放时间。
图 6.10 说明了计算的过程,并记录了此过程。下面给出了每个阶段的详细信息。
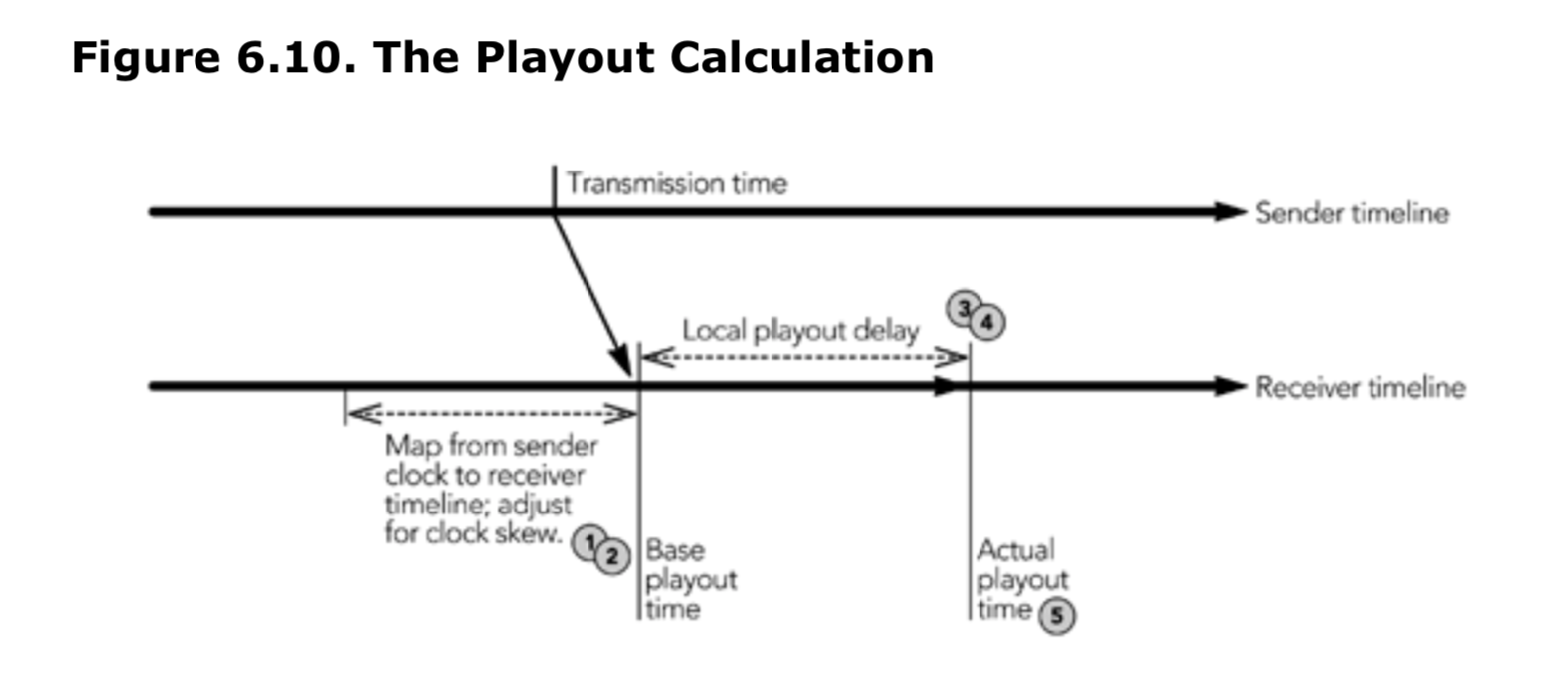
本地时间轴映射
播放时间计算的第一阶段是通过将发送者和接收者时钟之间的相对偏移添加到 RTP 时间戳,将发送者的时间轴(以 RTP 时间戳表示)映射到接收者的时间轴。
为了计算相对偏移量,接收者需要以相同的单位计算第 n 个包的 RTP 时间戳 与该包的到达时间
与该包的到达时间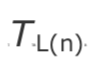 之间的差值 d(n):
之间的差值 d(n):
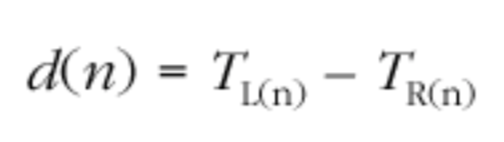
这个差值包含一个常数因子,设置这个常数因子是因为发送者和接受者的时钟是在不同的时间用不同的随机值初始化的,也是因为在发送者处的数据准备时间而引起的延迟可变,也是因为网络传输时间最短而导致的常数因子,更是因为网络时序抖动引起的可变延迟以及由于时钟偏斜引起的速率差。
这个差值 d(n)包括一个常数因数,因为发送者和接收者时钟在不同的时间使用不同的随机值进行初始化;由于在发送者处的数据准备时间而导致的可变延迟;由于最小网络传输时间而导致的常数;由于网络时序抖动以及由于时钟偏移引起的速率差异。差值是一个 32bit 无符号整数,就像计算它的时间戳一样。 并且由于发送者和接收者时钟未同步,因此它可以具有任何 32bit 值。
在每个数据包到达时计算差值,并且接收者跟踪其最小观测值以获得相对偏移:
由于时钟偏移导致 和
和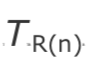 之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
之间的速率差异,差异 d(n)趋于更大或更小。为了防止这种偏移,在一个窗口 w 上计算最小偏移量,即自上一次补偿时钟偏移以来的差值。还请注意,由于值可能会有翻转效应,因此需要进行无符号比较:
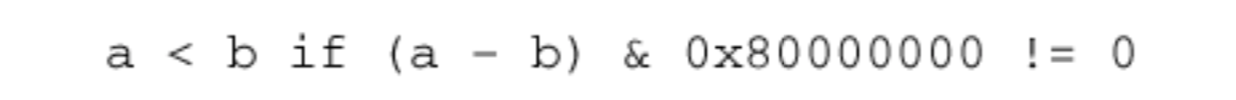
根据接收者的时间轴,偏移量用于计算基本的播放点:
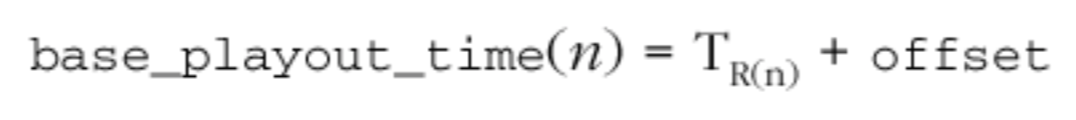
这是对播出时间的初始预估,并应用了其他因素来补偿时钟偏斜(skew)以及抖动等。
时钟偏移(skew)补偿
RTP 有效负载格式定义了媒体流的标准时钟速率,但是对时钟的稳定性和准确性没有任何要求。发送者和接收者的运行速率通常稍微不同,迫使接收者对需要变化进行补偿。数据包的传输时间与接收时间的关系图,如图 6.9 所示。如果曲线的斜率正好是 45 度,那么时钟的频率是一样的,偏移是由发送者和接收者之间的时钟倾斜造成的。
接收方需要检测时钟偏差是否存在,并估计其大小,然后通过调整播放点进行补偿。有两种可能的补偿策略:一种是调整接收方时钟以与发送方时钟匹配,另一种是定期调整播放缓冲区的重新对齐。
后一种方法不调整受时钟偏差,而是通过插入或删除数据来周期性地重新对齐播放缓冲区。如果发送方的速度更快,接收方最终需要丢弃保持对齐时钟,否则播放缓冲区将溢出。如果发送方的速度较慢,接收方将用完可播放的媒体内容,必须合成一些数据来填补剩余的空白。时钟偏差的大小决定了播放点调整的频率,从而决定了体验下降程度。
如果接收方的时钟频率可以进行精确调节,可以调整速率以完全匹配发送方的速率,从而避免了对播放缓冲区进行重新对齐。这种方法可以提供更高的质量,因为数据不会因为时钟偏差而被丢弃,但可能需要硬件支持,这种硬件并不常见(音频系统可以用软件的方法重新采样来匹配所需的速率)。
估计初始时钟偏差看起来似乎很简单:观察发送方时钟的速率,即RTP时间戳,然后与本地时钟进行比较。如果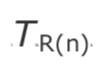 是接收到的第 n 个数据包的 RTP 时间戳,
是接收到的第 n 个数据包的 RTP 时间戳,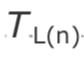 是当时的本地时钟的值,那么时钟偏移的预估如下:
是当时的本地时钟的值,那么时钟偏移的预估如下:
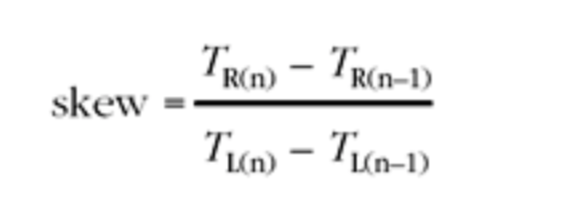
偏移小于 1 表示发送者比接收者慢,而偏移大于 1 表示发送者时钟比接收者快。然而不幸的是,因为网络时序抖动的存在, 这种估算是存在不足的;网络时序抖动回影响到达时间。为了估算更准确时钟偏差,接收方必须观察数据包到达时间长期变化,剔除时序抖动的影响。
准确性和对抖动的敏感性是时钟偏移管理中的重要考虑因素,有多种算法可用于处理这些问题。在下面的讨论中,我将介绍一种简单的方法来估计和补偿时钟偏移,这种方法已被证明适用于VOIP,并提供了适用于对准确性要求更高的应用的算法的指南。
对时钟偏移的管理方法是,持续监控平均网络传输延迟,并将其与主动延迟预估进行比较。有效延迟预估和测得的平均延迟之间的差距越大,越表示了时钟倾斜存在,这最终将导致接收者调整播放。当每个包到达时,接受方根据包的接收时间以及其 RTP 时间戳计算 n 个数据包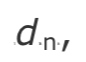 的瞬时单向延迟:
的瞬时单向延迟:
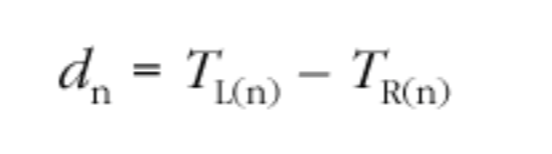
在接收到第一个数据包时,接收者设置延迟为 E = d0,预估平均延迟为 D0 = d0。对于每个后续的数据包,平均延迟预估的值 Dn 将通过指数加权移动平均值(exponentially weighted moving average)进行更新:
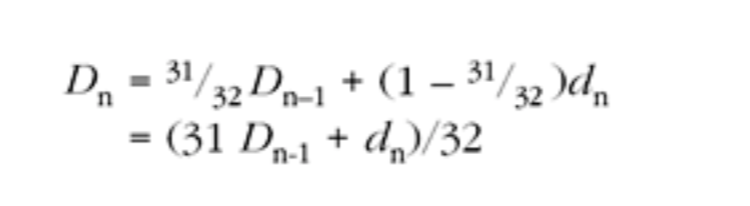
31/32 这个因子控制了平均过程,数值越接近单位 1,平均值对传输时间的短期波动越不敏感。需要注意的是,这个计算类似于估计抖动的计算;但是它保留了变化的符号,并且使用了一个经过选择的时间常数来捕捉长期变化并减小对短期抖动的反应。
将平均单向延迟 Dn 与主动延迟预估 E 进行比较,用来预估自上次预估以来的差异:
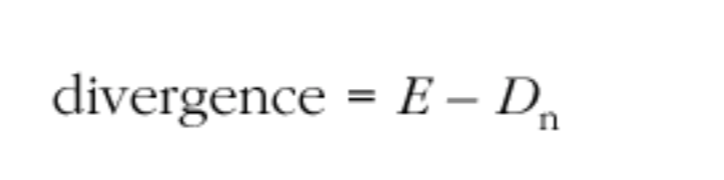
如果发送者时钟和接收者时钟保持同步,那么它们之间的差异(divergence)将接近于零,只会因为网络抖动而产生微小的变化。如果时钟存在偏移,那么差异将会增加或减少,直到超过预定的阈值,从而促使接收者采取补偿措施。该阈值的选择取决于抖动的程度,以及编码器。阈值必须足够大,以避免由于抖动引起的错误调整,并且选择调整的时机需要慎重选择,避免播放不连续。通常情况下,合适的时间点是在帧间隔,这意味着可以插入或删除整个帧。
补偿包括增加或减少播放缓冲区,如本章后面的“自适应播放点”一节所述。播放点可以根据 RTP 时间戳单元的差异做变化(对于音频,差异通常给出要添加或删除的样本数量)。在补偿偏移之后,接收者将活动预估值 E,重置为当前延迟预估的值 Dn,在此过程中差异(divergence)重置为 0(此时还将重置 base_play-out_time(n) 的预估值).
在类 C 的伪代码中,当接收到每个包时,执行的算法是这样的:
adjustment_due_to_skew(rtp_packet p, uint32_t curr_time)
{
static int first_time = 1;
static uint32_t delay_estimate;
static uint32_t active_delay;
uint32_t adjustment = 0; uint32_t d_n = p->ts – curr_time;
if (first_time)
{
first_time = 0;
delay_estimate = d_n;
active_delay = d_n;
}
else
{
delay_estimate = (31 * delay_estimate + d_n)/32;
}
if (active_delay – delay_estimate > SKEW_THRESHOLD)
{
// Sender is slow compared to receiver adjustment =SKEW_THRESHOLD; active_delay = delay_estimate;
}
if (active_delay – delay_estimate < -SKEW_THRESHOLD)
{
// Sender is fast compared to receiver adjustment =-SKEW_THRESHOLD; active_delay = delay_estimate;
}
// Adjustment will be 0, SKEW_THRESHOLD, or –SKEW_THRESHOLD. It is // appropriate that SKEW_THRESHOLD equals the framing interval. return adjustment;
}
该算法的假设是抖动分布是对称的,并且任何系统性偏差都是由于时钟偏差引起的。如果偏差值的分布非对称,原因并非时钟偏差,那么该算法会得出错误的偏差。此外,网络传输时间的显著短期波动也可能导致算法失灵,接收方会将网络抖动误认为时钟偏差,调整播放点。然而,这些问题都不能带来实际的问题:偏差补偿算法最终会自我纠正,而任何调整步骤都可能需要来适应这些波动。
另一个偏移补偿的假设是对播放点进行逐步调整,例如逐次添加或删除一个完整的帧,同时隐藏不连续性,就好像丢失了一个包一样。这对许多编解码器(尤其是基于帧的语音编解码器)是适当的行为,因为它们经过优化以隐藏丢失的帧。偏移补偿可以利用这种能力,只需小心地添加或删除不重要的、通常是低能量的帧。然而,在某些情况下,更平滑地自适应是可取的,可能一次插入一个样本。
如果需要更平滑的自适应,Moon等人提出的算法可能更合适,尽管它更加复杂,对状态维护的要求也更高。他们的方法基于观测到的单向延迟与时间之间的关系图,使用线性规划来拟合一条最接近所有数据点的线。一种等效的方法是在图6.9所示的数据点上获得最佳拟合直线,并使用它来估计时钟的倾斜。如果偏移是恒定的,那么这个算法将更准确,但显然会有更高的成本,因为它需要接收者记录点的历史数据,并执行昂贵的线性拟合算法。然而,如果延迟测量采样间隔足够长,该算法可以获得高精度的偏移估计。
对于长期运行的应用程序来说,应考虑时钟偏移的不稳定性,它会受外界影响而随时间变化。例如,温度变化会影响振荡器的频率,从而导致时钟频率和发送方与接收方之间偏移的变化。非稳定的时钟偏差可能会影响依赖于长期观测的数据的一些算法(如Moon等人提出的算法)的效果。其他一些算法,例如前文提到的Hodson等人的算法,由于它们在较短时间内工作并定期重新计算偏差,因此对时钟变化具有较强的鲁棒性。
在选择时钟偏差估算算法时,关键是考虑播出时间点可能的变化规律,并选择一个具有适当精度的估算器。例如,基于帧的音频编解码应用可以通过添加或删除单个帧实现自适应,因此直接基于最近样本测量得到的偏差估算可能会过大。本章后续部分"适应播放点"将更深入地探讨此问题。
虽然它们超出了本书的范围,但是 NTP 的算法可能也会引起读者的兴趣。对于那些对时钟同步和偏移补偿感兴趣的人,推荐阅读 PFC 1305(PDF 版本,可以从 RFC 编辑器的网站http://www.rfc-editor.org获得,比纯文本的版本可读性要强很多)。
发送者补偿
发送者数据包生成方式,可能影响接收者的计算播放时间,从而导致播放缓冲延迟增加。
如果发送者将组成一帧视频发送时间扩展到整个帧间隔,则帧的第一个和最后一个数据包之间将存在延迟,接收者必须缓冲数据包,直到接收到整个帧为止 。 图 6.11 显示了附加的播放延迟 Td 的插入,以确保接收者在所有片段到达之前都不会尝试播放该帧。
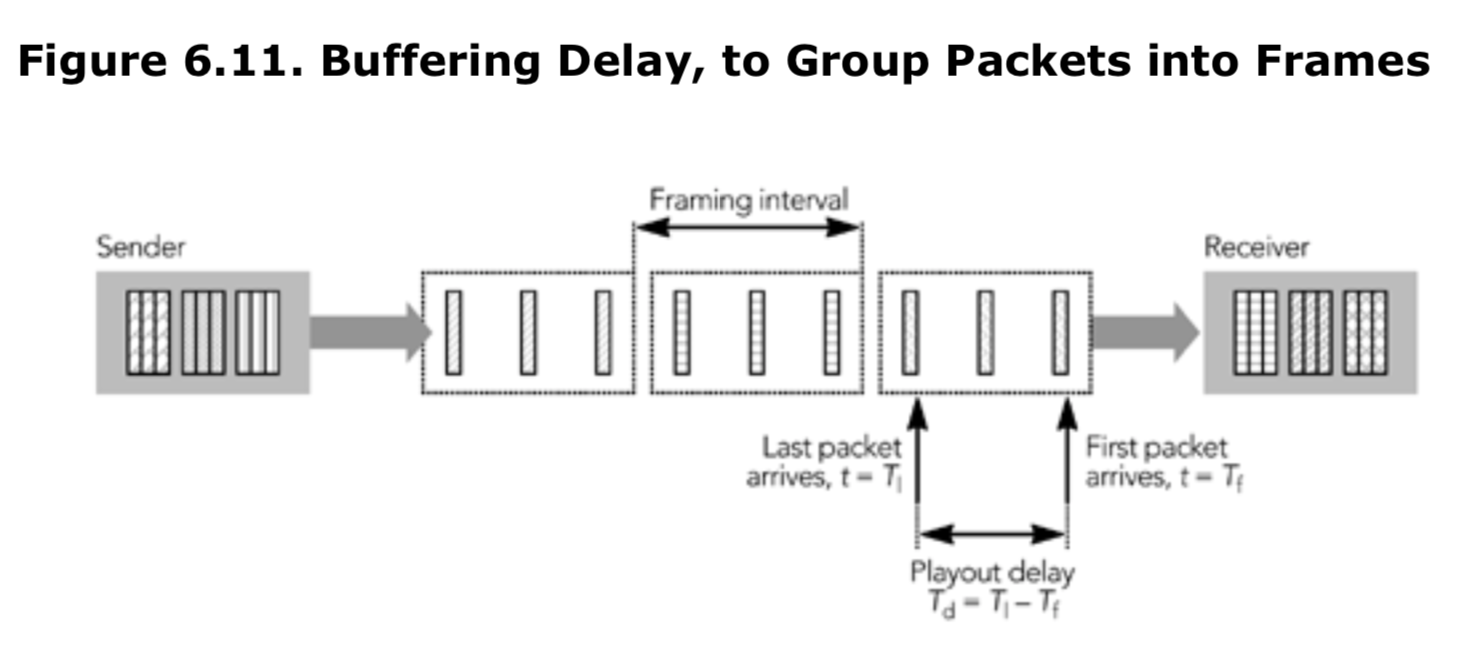
如果我们知道帧之间的时间间隔和每帧的数据包数量,那么插入额外的延迟就会变得很简单。假设发送者发送数据包的间隔是均匀的,那么我们可以进行以下调整:
adjustment_due_to_fragmentation = (packets_per_frame – 1) x (interframe_time / packets_per_frame)
不幸的是,接收者并不能总是提前知道这些变量。例如,在会话设置期间可能没有信令告知帧率,会话期间帧速率可能会变化,或者会话期间每帧的数据包数量可能会变化。这种变化可能会使得调度播放变得困难,因为不清楚需要添加多少延迟才能让所有片段到达。接收方必须估计所需的播放延迟,并在估计不准确时做出适应。
一个专门的模块复杂计算播放延时补偿,根据分片的到达时间来计算平均片片延迟。幸运的是,这不是唯一的计算方式,抖动计算可以起到同样的作用。一个帧的所有数据包具有相同的时间戳,表示帧的采集时间,而不是数据包发送的时间,因此分割的帧会导致接收抖动的出现(接收方无法区分在网络中延迟的数据包还是因为发送方延迟的数据包)。因此,下一节将讨论的抖动补偿策略可以用来估算必需的缓冲延迟来弥补分片带来的影响,而不需要在播放延迟机制中考虑分片问题。
如果发送方使用第9章中描述的纠错技术,就会出现类似的问题。为了让纠错包发挥作用,需要延迟播放,以便纠错包能够及时到达并被使用。纠错包的存在会在会话设置期间进行信令,并且信令可能包含足够的信息,使接收方能够正确调整播放缓冲区的大小。或者,正确的播放延迟必须从媒体流中推断出来。所需的补偿延迟取决于所采用的纠错类型。常见的三种纠错类型是奇偶FEC(前向纠错)、音频冗余和重传。
在第9章中讨论的错误纠正中,音频冗余方案包括在冗余数据包中使用时间偏移量,该偏移量可以用于确定播放缓冲区的大小。在对话开始时,冗余音频可以有两种方式:初始数据包可以不带冗余标头发送,或者可以带有零长度的冗余块。如图6.12所示,如果对话的初始数据包包含零长度的冗余块,可以更方便确定播放缓冲区的大小。然而,标准没有强制要求包含这些块,如果没有,可能需要估算出适当的播放延迟。在信息不足的情况下,常用方法是利用单个数据包的偏移值进行一个合理的估算。一旦确定了媒体流是否使用冗余,就应将偏移量应用于该流中的所有数据包,包括在对话开始时没有冗余的数据包。如果收到了完整的对话段而没有冗余,可以假设发送方已停止发送冗余数据包,未来的对话段可以无延迟播放。
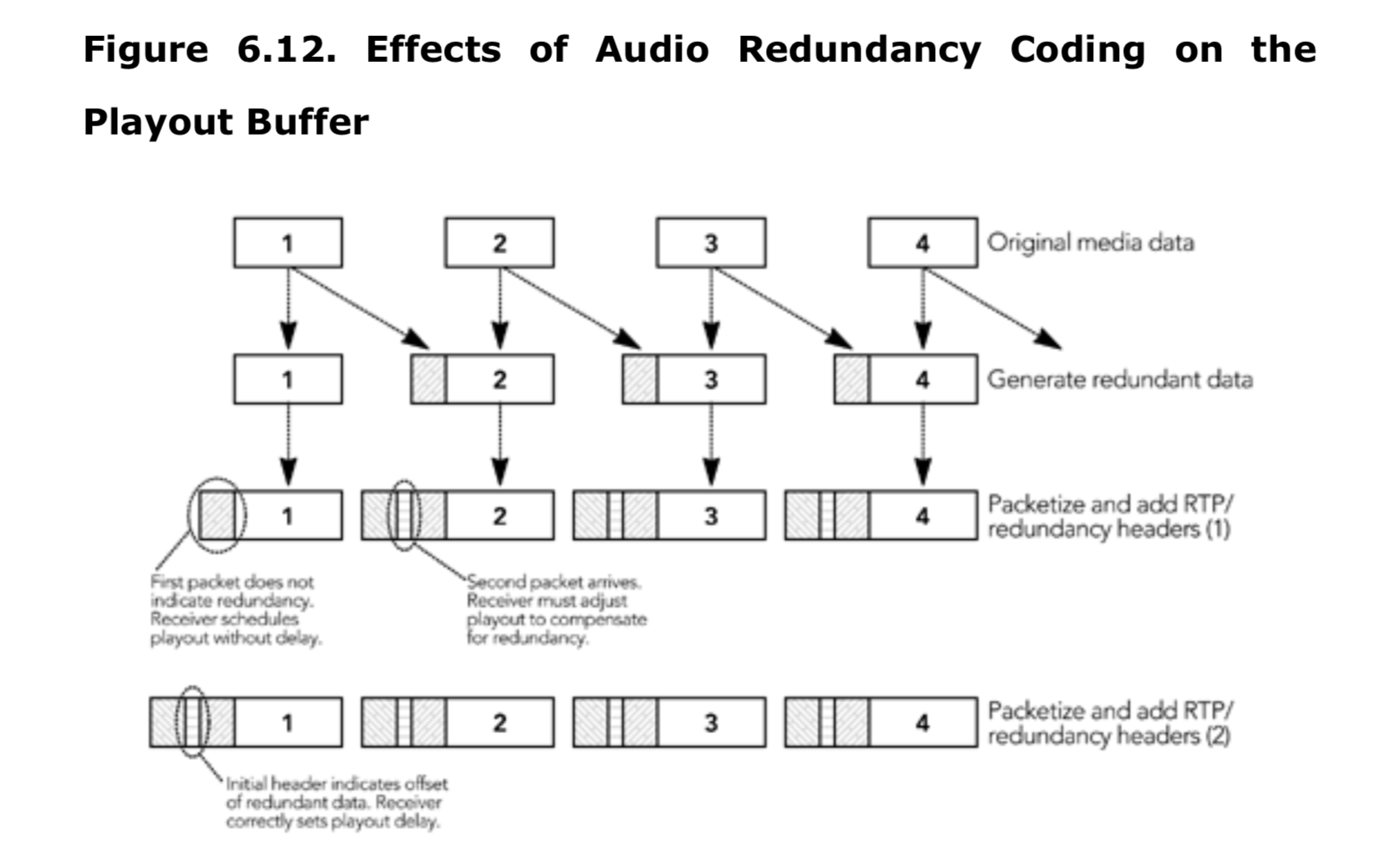
如果使用了奇偶校验 FEC 或冗余,接收者最初应该选择一个大的播放延迟,以确保到达的任何数据包都进入缓冲区。当第一个错误恢复包到达时,它将导致接受方减少它的播放延迟,重新安排时间,并播放当前缓冲的包。这个过程避免了由于缓冲延迟的增加而导致的播放间隙,代价是初始包会稍微延迟。
当使用包重传机制时,播放缓冲区的大小必须大于发送方和接收方之间的往返时延,以支持重传请求的往返和服务。接收方无法获知往返时延,只能通过发送重传请求来估测它。这对大多数实施没有影响,因为重传通常用于非交互应用,在这类应用中,播放缓冲延迟一般大于往返时延。但如果往返时延过大,可能会引起问题。
无论采用何种纠错方案,发送者都可能产生超量的纠错数据。例如,在向多播组发送数据时,发送端可能根据最差条件下的接收端选择错误纠错码,这对其他接收端来说可能过于保守。如Roseno-Berg等研究人员指出,仅利用部分错误纠错数据就可能修复部分数据丢失。在这种情况下,接收端可以选择比完全利用所有纠错数据需要的延迟更小的播放延迟,而不是等待足够长时间来修复其选择修复的损失部分。忽略某些纠错数据的决定,完全是由接收者根据其对传输质量的看法做出的。
最后,如果发送者使用了交织媒体流 -- 如第八章所述,错误隐藏 -- 接收者必须在播放计算中考虑这一点,这样才能将交织的数据包按照播放顺序排序。交织参数通常在会话设置期间发出信令,允许接收者选择适当的缓冲延迟。例如,AMR 有效负载格式定义了一个交织参数,该参数可以在 SDP a = fmtp:行中发出信令,表示每个交织组数据包的数量(因此应该插入到播放缓冲区中进行补偿的数据包数量方面的延迟量)。其他支持交织的编解码器应该提供类似的参数。
总而言之,发送者可以通过三种方式影响播放缓冲区:通过对帧进行分段和延迟发送分段,通过使用纠错包或通过交织。 其中的第一个将根据常规的抖动补偿算法进行补偿。 其他要求接收机调整播放缓冲区以进行补偿。这种补偿主要对于使用小的播放缓冲区来减少延迟的交互式应用程序而言是一个问题;而流媒体系统可以简单地设置较大的播放缓冲区。
抖动补偿
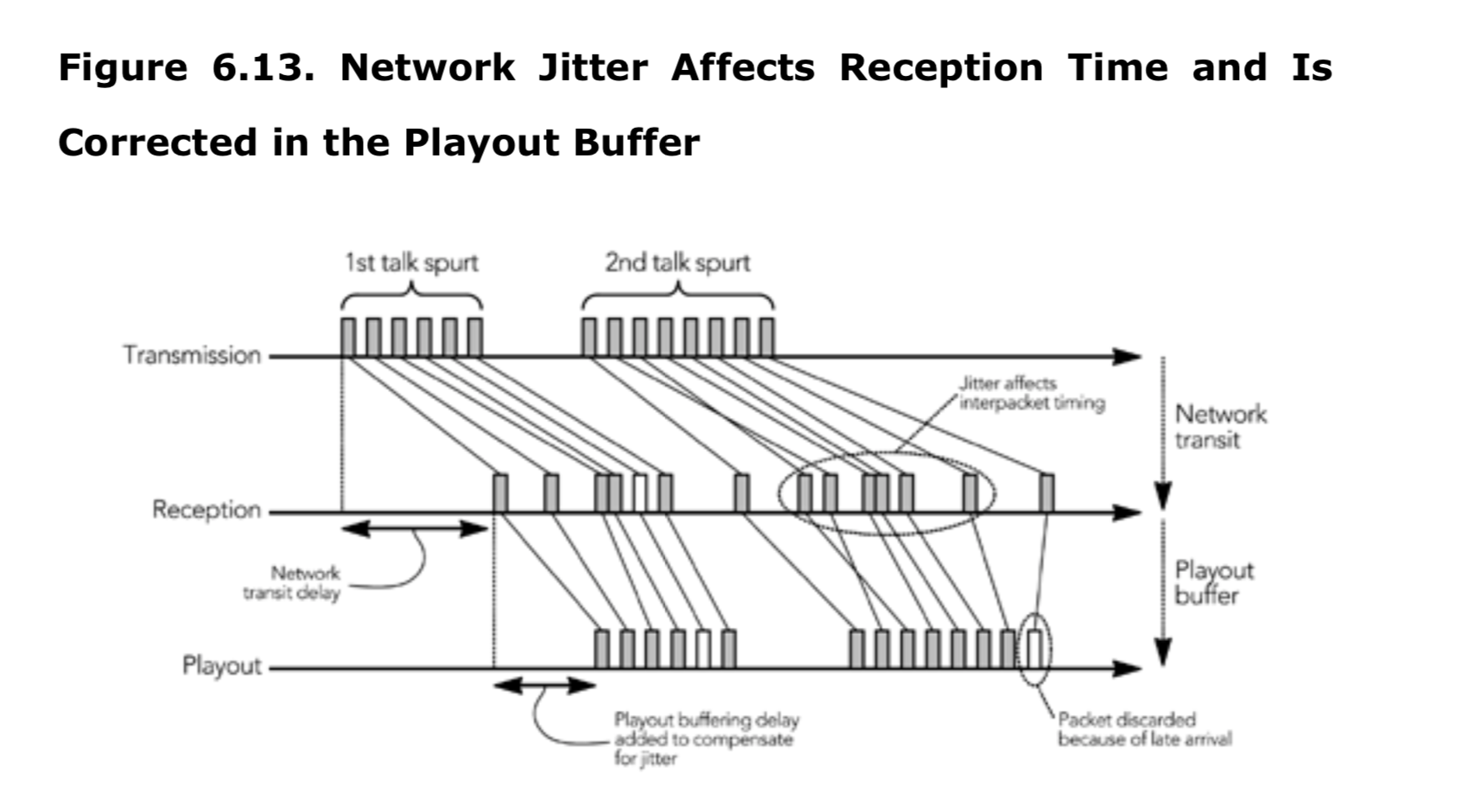
当 RTP 数据包流经真实 IP 网络时,数据包间时序的变化是不可避免的。 这种网络抖动可能很大,接收者必须通过在播出缓冲区中插入延迟补偿,以便可以处理网络延迟的数据包。延迟过大的数据包在其播放时间过去之后到达,会被丢弃; 选择适当的播出算法后,这种情况很少发生。图 6.13 显示了抖动补偿过程。
抖动补偿延迟的计算,没有标准算法;大多数应用程序都希望自适应的计算播放延迟,可以根据应用程序类型和网络条件使用不同的算法。为非交互式场景设计的应用程序可以选择一个远远大于预期抖动的补偿延迟,甚至几秒都是合适的。更复杂的是交互情况下,应用程序希望保持输出延迟尽可能小(考虑到特定的网络和分组延迟,数十毫秒的值也是可能的)。为了使播放延迟最小化,有必要研究抖动的特性,并利用这些特性获得最小的适当播放延迟。
大多数情况,网络引起的抖动基本上是随机的。包间到达时间(interpacket arrival time)与出现频率(frequency of occurrence)的关系图如图 6.14 的高斯分布有点儿类似。大多数数据包仅受到网络抖动的轻微影响,但是某些异常值则明显延迟或与相邻的数据包粘包(neighboring packet);
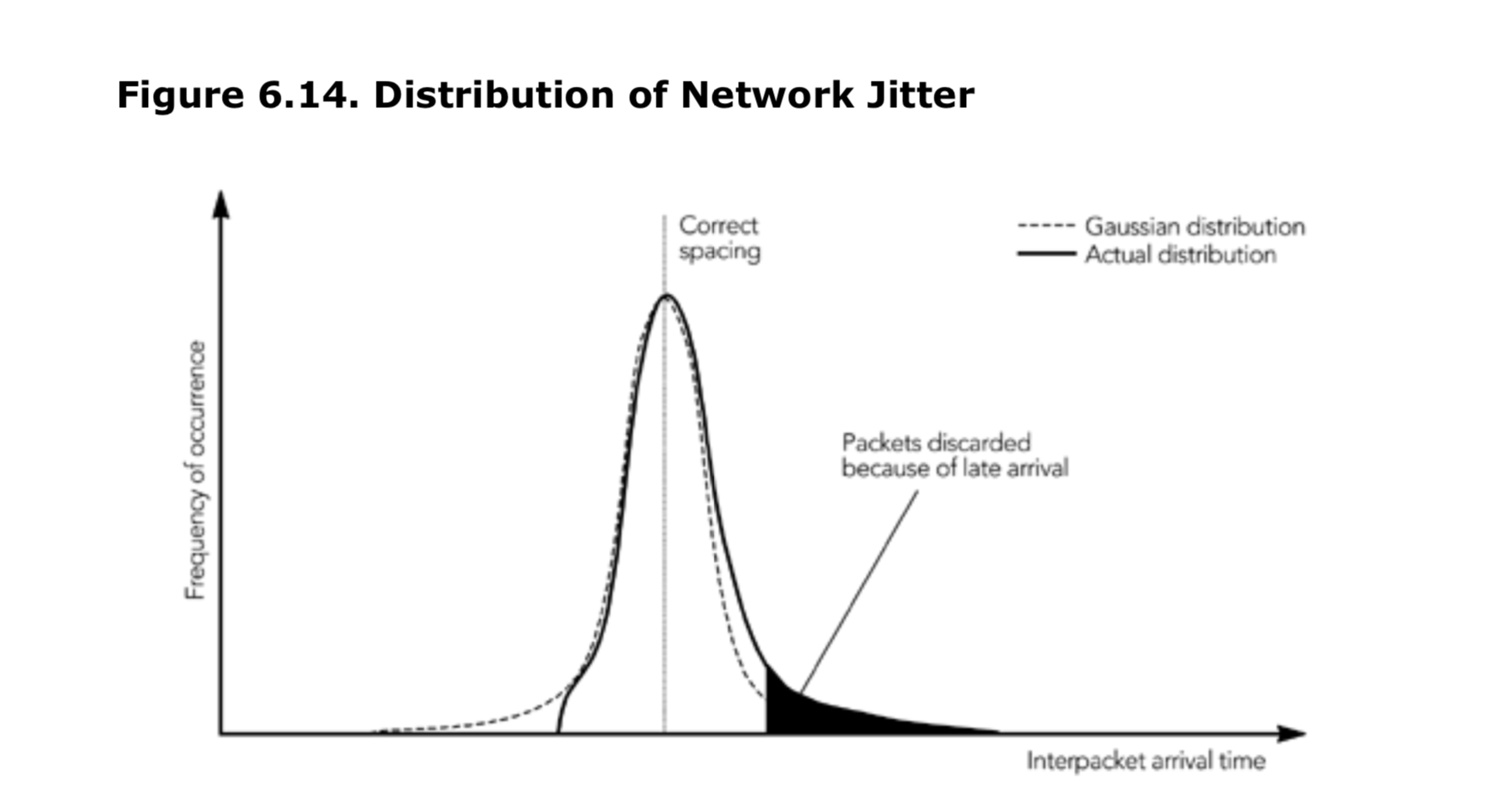
这个近似值有多精确取决于网络的路径,但是我和 Moon 等人进行的测量表明,在许多情况下,这种方案是近似合理的,尽管现实世界中的数据通常会偏向较大的到达时间,并且具有急剧的最小截止值(如图 6.14 的“实际分布”所示)。这种差异通常不是关键的,因为丢弃区域中的数据包数据量很少。
如果可以假设抖动分布近似于高斯正态分布,那么就很容易推导出合适的播放延迟。抖动的标准差是计算出来的。根据概率论,我们知道 99%以上的正态分布在均值(平均值)标准差的三倍以内。一个实现可能会选择一个等于到达间隔时间标准偏差的三倍的播放延迟,并希望由于延迟到达而丢弃少于 0.5%的数据包。如果此延迟过长,则使用延迟时间为标准差的两倍时,由于延迟到达产生的预期的丢弃率将会少于 2.5%,这也是基于概率论。
我们如何测量标准差?计算用于插入 RTCP 接收者报告的抖动值,跟踪网络传输时间的平均变化,该变化可以当作近似标准偏差。根据这些近似值,可以将补偿网络抖动所需的播放延迟预估为源 RTCP 抖动的三倍。新一帧的播放延迟可以设置为:
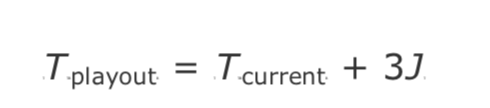
其中 J 为对当前抖动的预估,如第五章 RTP 控制协议所述。playout的值可以按照媒体类型进行相应的修改,如后面所讨论的。真实世界里,使用该值作为播放计算的基础表现出了良好的性能。
抖动分布既取决于流量在网络中的传输路径,也取决于与其共享该路径的其他流量。抖动的主要原因是与其他流量的竞争,导致中间路由器的排队延迟不断变化;显然,其他流量的变化也会影响接收方所感知到的抖动。因此,接收方应定期重新计算所使用的播放缓冲延迟,以适应网络行为的变化,并在必要时进行调整。接收方应该在何时进行适应?这并不是一个简单的问题,因为在媒体播放时改变播放延迟会打断播放,导致要么出现中断,要么迫使接收方丢弃一些数据来弥补时间损失。因此,接收方尽量限制调整播放点的次数。有几个因素可以触发适应:
- 由于延迟而丢弃的数据包的比例显著变化
- 接收几个连续的必须而被丢弃的包,原因是延迟到达(三个连续的数据包是一个合适的阀值)
- 接收到来自长时间不活跃发送者的信息包(10 秒是合适的阀值)
- 网络传输延迟出现尖峰
除了网络传输延迟的峰值外,这些因素应该是不言自明的。如第二章第 2 节的图 2.12 所示,当几个数据包被延迟并突发时,网络有时会导致传输延迟中出现“尖峰”信号。这样的峰值很容易使抖动预估值产生偏差,导致应用程序选择比要求的更大的播放延迟。在许多应用程序中,这种播放延迟的增加是可以接受的,应用程序应该将尖峰视为其他形式的抖动,并增加播放延迟来进行补偿。然后,一些应用程序更喜欢增加丢包而不是增加延迟。这些应用程序应该检测延迟尖峰的开始,并在计算播放延迟时,忽略尖峰中的包。
检测延迟尖峰的开始很简单:如果连续数据包之间的延迟突然增加,就可能发送了延迟尖峰。“突然增加”的规模可以有一些解释:Ramjee 等人认为,到达间隔时间统计方差的两倍加上 100 毫秒是一个合适的阈值;我熟悉的另一个实现,用了 375 毫秒的固定阈值(都是使用 8KHz 语音的 ip 语音系统)。
某些媒体事件还会导致连续包之间的延迟增加,不应将其与延迟峰值开始混淆在一起。例如,音频静音抑制将导致在一个通话突发中的最后一个数据包,与下一个通话突发中的第一个数据包之间出现间隙。同样,视频帧速率的变化也会导致包的时序发生变化。在假定数据包间延迟的变化,就意味着出现了一个尖峰之前,应该先检查此类事件。
一旦检测到延迟脉冲,应该暂停正常的抖动调整,直到脉冲结束。这个操作的结果就是几个包可能会因为延迟到达而被丢弃,但是假设应用程序有严格的延迟边界,那么相比于增加播放延迟,这个结果是可接受的。
定位一个尖峰的末端比探测它的开始要困难。延迟尖峰的一个关键特征是,在尖峰之后,在发送者均匀间隔的数据包将以突发的形式到达,这意味着每个数据包的传输延迟将逐渐减小,如图 6.15 所示:
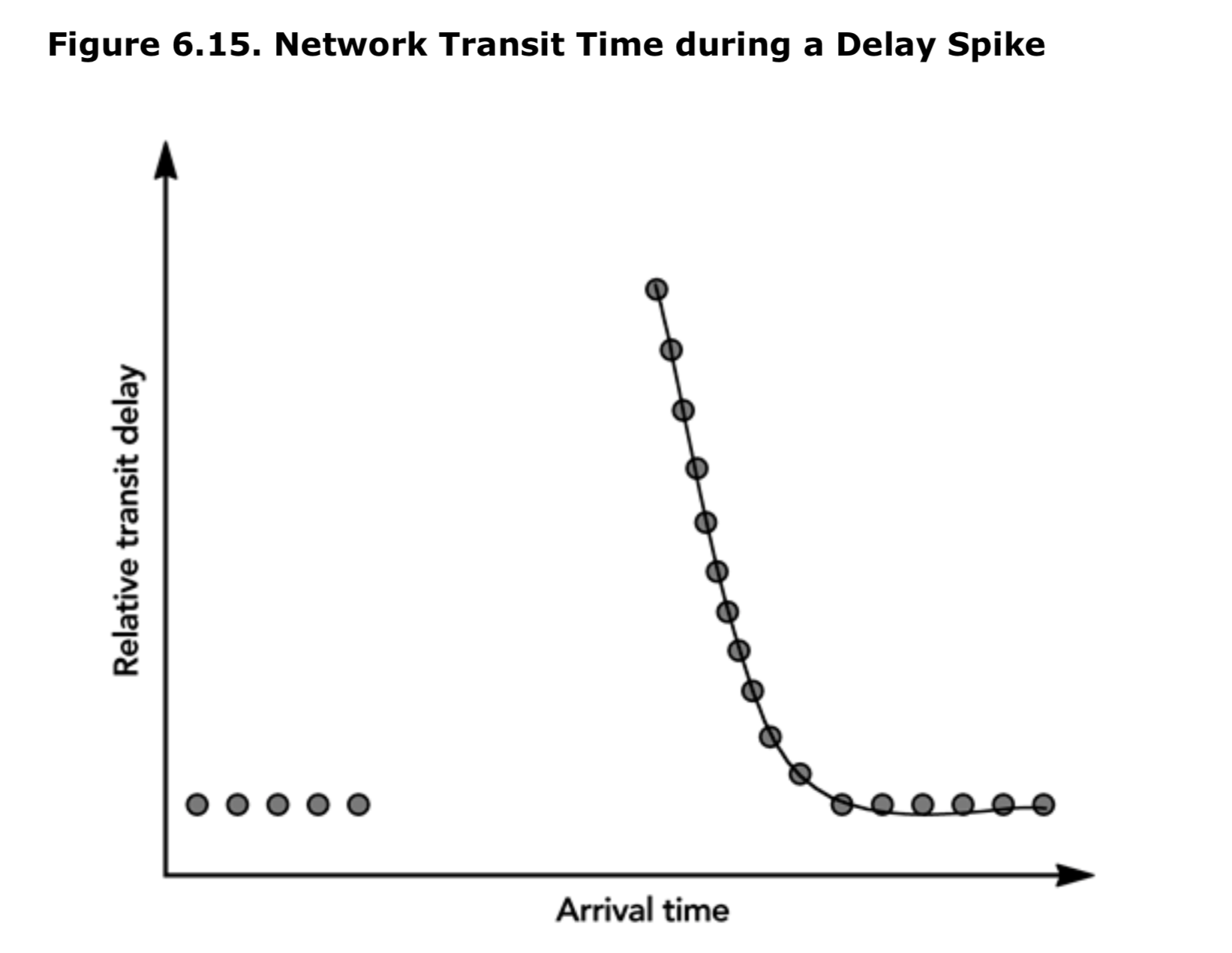
考虑到所有的这些因素,补偿抖动和延迟尖峰影响的播放延迟的伪代码如下:
int
adjustment_due_to_jitter(...)
{
delta_transit = abs(transit – last_transit);
if (delta_transit > SPIKE_THRESHOLD)
{
// A new "delay spike" has started
playout_mode = SPIKE;
spike_var = 0;
adapt = FALSE;
}
else
{
if (playout_mode == SPIKE)
{
// We're within a delay spike; maintain slope estimate
spike_var = spike_var / 2;
delta_var = (abs(transit – last_transit) + abs(transit
last_last_transit))/8;
spike_var = spike_var + delta_var;
if (spike_var < spike_end)
{
// Slope is flat; return to normal operation
playout_mode = NORMAL;
}
adapt = FALSE;
}
else
{
// Normal operation; significant events can cause us to
//adapt the playout
if (consecutive_dropped > DROP_THRESHOLD)
{
// Dropped too many consecutive packets
adapt = TRUE;
}
if ((current_time – last_header_time) > INACTIVE_THRESHOLD)
{
// Silent source restarted; network conditions have
//probably changed
adapt = TRUE;
}
}
}
desired_playout_offset = 3 * jitter
if (adapt)
{
playout_offset = desired_playout_offset;
}
else
{
playout_offset = last_playout_offset;
}
return playout_offset;
}
关键点是在延迟峰值期间,抖动补偿被暂停,而实际的播放时间只在发生重要事件时才会改变。在其他时间,desired_playout_offset被存储,以在特定时间(参见标题为"调整播放点"的部分)恢复。
路由变更补偿
虽然很少发生,但是,由于链路故障或者拓扑结构发生改变,路由更改就会出现在网络中。如果 RTP 包所传输的的路由发生了变化,将表现为网络传输时间的突然变化。这个变化将会打乱播放缓冲区,因为要么数据包到达得太晚而无法播放,要么它们将提前到达并与之前的数据包重叠。
抖动和延迟峰值补偟算法应检测延迟变化,调整播放进行补偿,但这可能不是最优方法。如果接收端直接观测网络传输时延并根据较大变化调整播放延迟,就可以实现更快的自适应。例如,如果传输延迟变化超过当前抖动估计值的5倍,则调整播放延迟。因为网络传输时延用于部分抖动计算,所以这种观测很简单。
对包重新排序的补偿
在极端的情况下,抖动或者路由的更改,可能导致网络中的包被重排序。正如第二章“分组网络上的音视频通信”中所讨论的,这种情况通常很少发生,但是这种情况发生的频度足够引起重视,实现时需要能够补偿它的影响,并平稳的处理包含乱序包的媒体流。
对于设计正确的接收者来说,重新排序应该不是问题,数据包根据它们的 RTP 时间戳插入到播放缓冲区,而不考虑它们到达的顺序。如果播放延迟足够大,则按正确的顺序播放。否则,它们将像其他延迟的包一样被丢弃。如果许多包由于重新排序和延迟到达而被丢弃,抖动补偿算法将负责调整播放延迟。
播放点自适应
调整播放点的方法有两种基本方式:接收方可以对每帧的播放时间进行微调,持续进行小幅度的调整;或者可以在媒体流中插入或删除完整的帧,根据需要进行较少次数的大幅度调整。无论采用哪种方式进行调整,媒体流都会在某种程度上受到干扰。适应的目标是最大程度地减少这种干扰,这需要对媒体流有深入的了解;因此,音频和视频的播放适应策略需要单独进行讨论。
用静音抑制调整音频播放
音频是一种连续的媒体格式,每个音频帧都占用一定的时间,下一个音频帧会在前一个帧完成后立即开始。除非使用了静音抑制技术,否则帧之间不会有间隔,因此没有合适的时机来调整播放延迟。正因为如此,静音抑制对音频播放缓冲算法的设计具有重要影响。
在对话性语音信号中,发言人的说话会间隔几百毫秒,间隙期间为静默期。图6.16展示了语音信号中说话间隔及其间隙的存在。发送方会检测到表示静默期的帧,并抑制为这些帧产生的RTP数据包。结果,数据包序列号连续,但RTP时间戳会根据静默期长度发生跳跃。
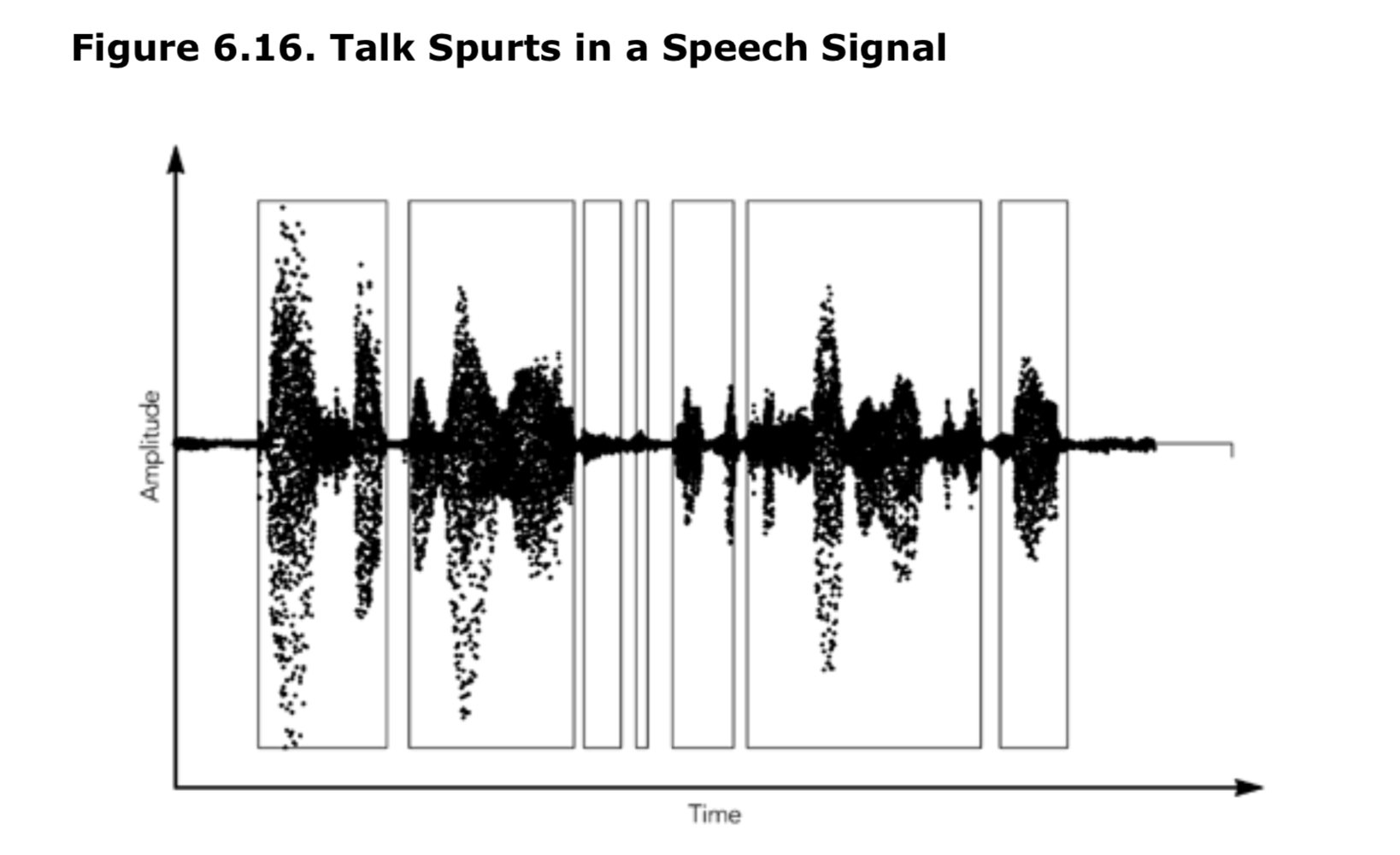
在说话间隔期间调整播放点会在输出中产生明显的故障声,但是在说话间隔之间的静默期长度发生微小变化是不会被注意到的。这是在设计音频工具的播放算法时需要牢记的关键要点:如果可以的话,只在静默期间调整播放点。
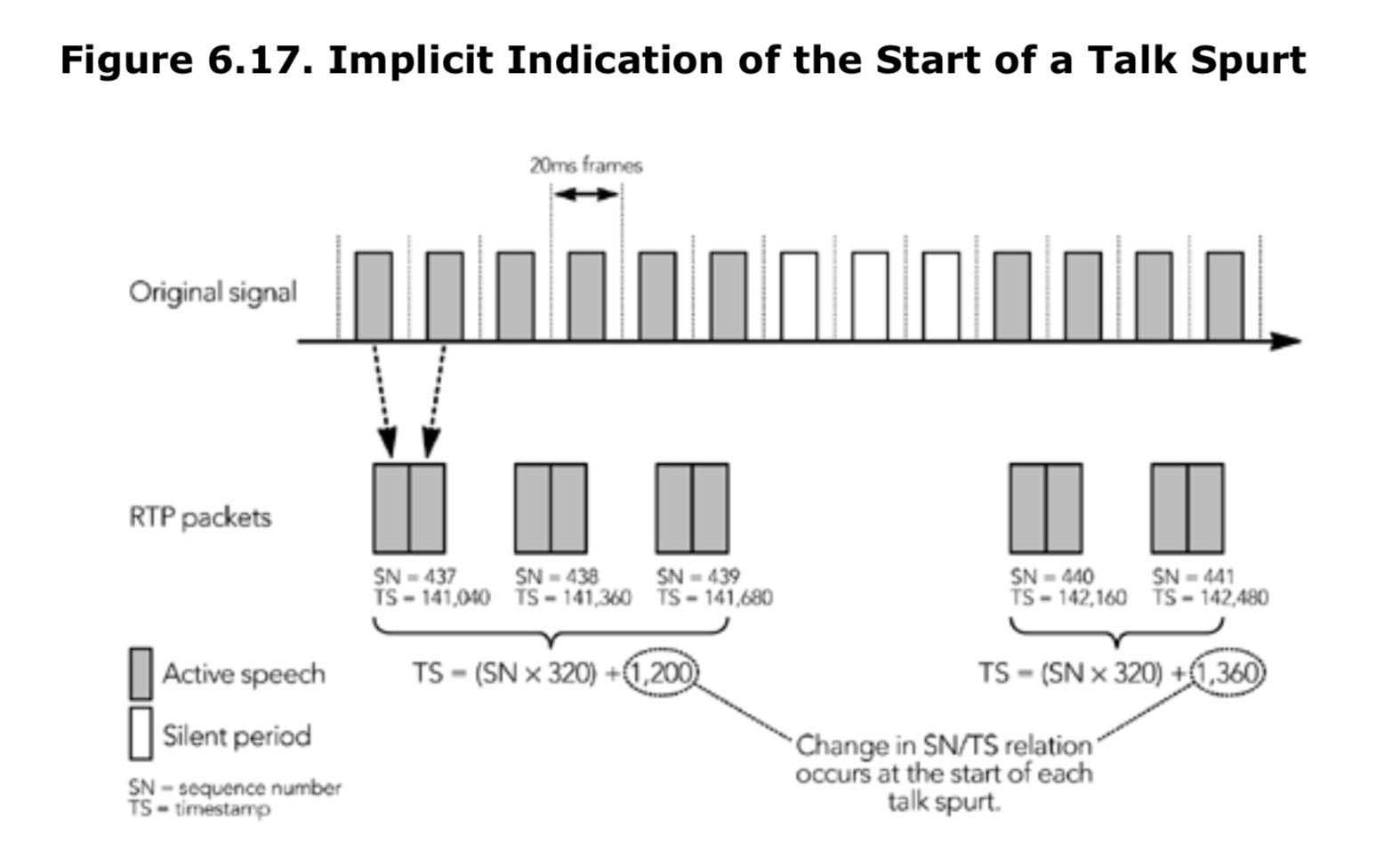
通常情况下,接收方能够很容易地检测到说话间隔的开始,因为发送方在静默期后的第一个数据包上会设置标记位,明确表示说话间隔的开始。有时在说话间隔起始时,第一个数据包可能会丢失。通过序列号和时间戳的变化通常还是可以判断新的说话间隔开始,如图6.17所示,这提供了判断标准。
一旦确定了说话间隔的开始,你可以通过微调静默期的长度来调整播放点。然后,在整个说话间隔中,播放延迟保持不变。在每个说话间隔期间计算出适当的播放延迟,并用于调整接下来的说话间隔的播放点,这是基于一个假设:在说话间隔之间,网络情况不太可能发生显著变化。
一些语音编解码器在静音期间发送低速率的舒适噪声帧,以便接收者可以播放适当的背景噪声,以获得更愉快的收听体验。接收到一个舒适的噪声包表明一个谈话的结束,和一个适当的时间来调整播放延迟时机的开始。舒适噪声周期的长度可以改变,但对音频质量没有显著影响。RTP 有效负载类型通常不会标识出舒适噪声帧,因此,有必要通过检查媒体数据判断是否是舒适噪音。对于不支持本地舒适噪声的旧编解码器,可能会使用RTP有效负载格式来传输舒适噪声,其RTP有效负载类型为13。
在特殊情况下,可能有必要在通话尖峰期进行调整 -- 例如,如果多个数据包由于延迟到达而被丢弃。这些情况预计会很罕见,因为通话尖峰相对较短,网络条件通常变化缓慢。
将这些特性结合起来产生如下伪代码,以确定适当的时间来调整播放点,假设使用了静音抑制,如下所示:
int
should_adjust_playout(rtp_packet curr, rtp_packet prev, int contdrop)
{
if (curr->marker)
{
return TRUE; // Explicit indication of new talk spurt
}
delta_seq = curr->seq – prev->seq;
delta_ts = curr->ts - prev->ts;
if (delta_seq * inter_packet_gap != delta_ts)
{
return TRUE; // Implicit indication of new talk spurt
}
if (curr->pt == COMFORT_NOISE_PT) || is_comfort_noise(curr))
{
return TRUE; // Between talk spurts
}
if (contdrop > CONSECUTIVE_DROP_THRESHOLD)
{
contdrop = 0;
return TRUE; // Something has gone badly wrong, so adjust
}
return FALSE;
}
变量 contdrop 是由于不在适当的播放时间而丢弃的连续数据包的数量。例如,如果路由更改导致数据包到达时间太晚而无法播放。连续丢包阈值CONSECUTIVE_DROP_THRESHOLD 的一个合适值是三个数据包。如果should_playout()返回TRUE,接收端要么处于静音期,要么错误计算了播放点。如果计算的播放点偏离当前值,应通过调整计划播放时间来调整未来包的播放点。无需生成填充数据,直接播放静音或舒适噪音,直到下个数据包调度播放。
当播放延迟正在减少时,需要注意,因为条件的重大变化,可能会使下一个讲话的突然开始时间提前到,与一个讲话突然结束的时间重叠。由于不希望限制通话期的开始,因此可执行的调整量会受到限制
音频无静音抑制的播放调整
当接收到没有静默抑制的音频时,接收方必须在音频播放过程中调整播放点。最理想的适应方式是调整本地媒体时钟以与发送方保持一致,这样数据就可以直接播放出来。如果由于缺乏必要的硬件支持而无法实现这一目标,接收方将不得不通过生成填充数据插入到媒体流中,或者从播放缓冲区中删除一些媒体数据来变化播放点。无论采用哪种方法,都不可避免地会对播放造成一些干扰,因此重要的是要隐藏适应的效果,以确保不会干扰听众。
根据输出设备的性质和接收者的资源,有几种可能的自适应算法:
- 音频可以在软件重采样,以匹配输出设备的速率。标准信号处理教程提供了各种算法,这取决于所需的质量和资源之间的权衡。这是一个很好的通用解决方案。
- 根据对媒体的了解,可以对播放延迟进行逐个样本的调整。例如,Hodson 等人使用模式匹配算法来检测语音中的音调周期,这些音调周期会被删除或复制以适应播放效果(音调周期比完整帧要短得多,因此这种方法可以实现细粒度的适应)。与重采样相比,此方法可以执行得更好,但是它是特定于内容的。
- 完整的帧可以插入或者删除,就像数据包丢失或重复一样。这种算法质量通常不高,但是,如果使用了专为同步网络而设计的硬件解码器,则可能需要这种算法。
在没有静音抑制的情况下,调整播放点的时机并不明显。然而,接收方仍然可以根据情况做出明智的选择,根据编解码器和错误隐藏算法,在相对安静或信号高度重复的时期进行自适应播放。关于错误隐藏的策略,可以在第8章的错误隐藏一章中找到详细的描述。
视频播放自适应
视频是一种离散的媒体格式,在这种格式中,每一帧都在特定的时间点采样,帧与帧之间的间隔不会被记录。视频的离散特性,为播放算法提供了灵活性,可以允许接收者通过稍微改变帧间计时来自适应播放。不幸的是,显示设备通常以固定的速率运行,视频不能在任意时间显示。因此,视频播放成为了一个问题,即如何尽量减小期望的帧呈现瞬间与可能的帧呈现瞬间之间的偏差。
举个例子,考虑一下在刷新率为 85Hz 的监视器上显示每秒 50 帧的视频的问题。在这种情况下,监视器刷新时间将与视频播放时间不匹配,这将不可避免的导致帧呈现给用户的时间发生变化,如图 6.18 所示。只有改变采集设备的帧速率或者显示的刷新率才能解决这个问题。在实践中,这个问题目前是无解的,因为视频采集和回放设备通常对可能的速率有硬件限制。即使采集和回放设备,在名义上具备相同的速率,也可能需要根据抖动或者时钟偏移的影响播放。
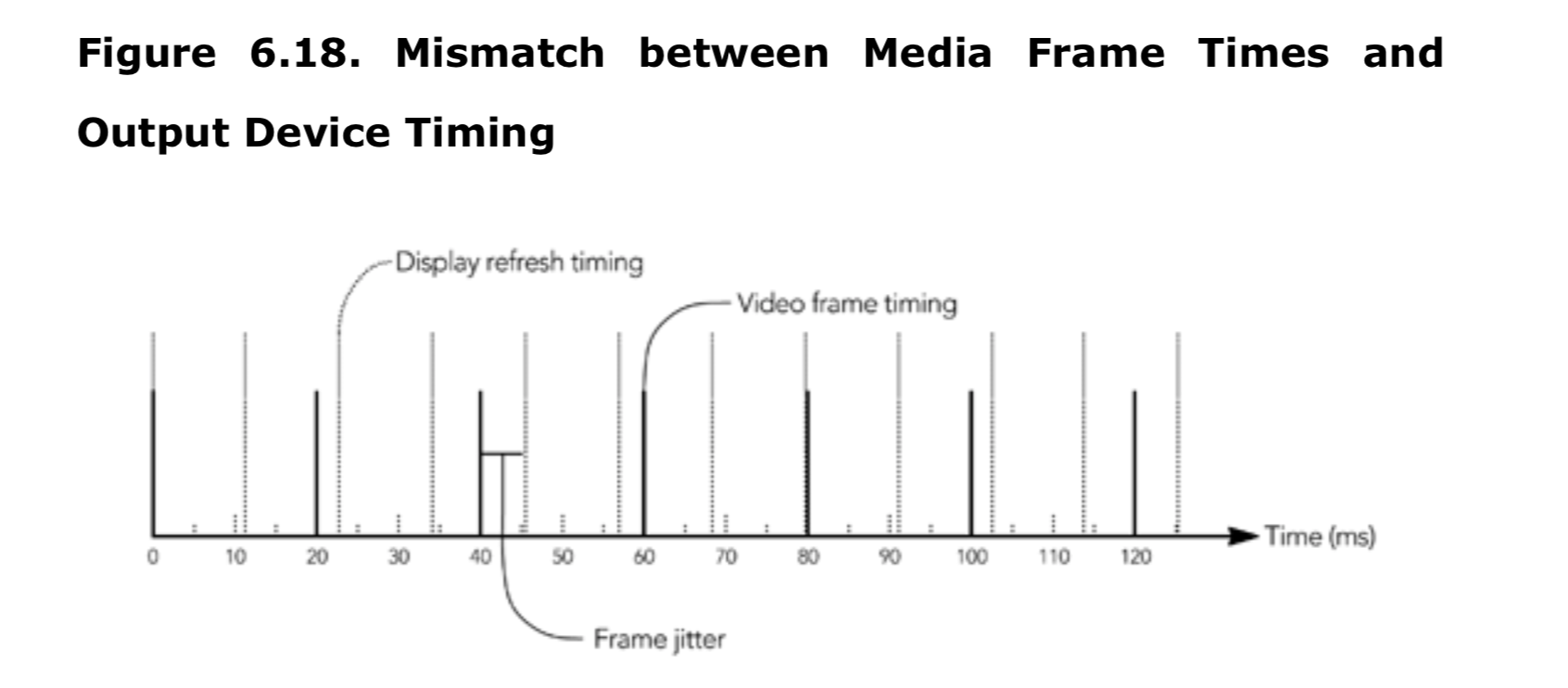
存在三种可能的调整情况:(1)当显示设备的帧率高于采集设备时;(2)当显示设备的帧率低于采集设备时;(3)当显示和采集设备以相同帧率运行时。
如果显示设备的帧率高于采集设备的帧速率,则可能的显示时间将围绕所需时间,并且每个帧都可以映射到唯一的显示刷新间隔。 最简单的方法是以最接近其播放时间的刷新间隔显示帧。可以通过朝任何所需的播放调整方向移动帧来获得更好的结果:如果接收者时钟相对较快,则在其播放时间之后的刷新间隔显示帧,如果接收者时钟较慢则以较早的间隔显示帧。当没有从发送者收到新帧时,可以通过重复前一帧来填充中间刷新间隔。
如果显示设备的帧率低于采集设备,则不可能显示所有帧,并且接收者必须丢弃一些数据。例如,接收者可以计算帧播放时间和显示时间之间的差异,并选择显示最接近可能显示时间的帧子集。
如果显示设备和采集设备以相同的速度运行,则可以滑动播放缓冲区,使得帧的显示时间与显示刷新时间一致,且滑动会提供一定程度的抖动缓冲延迟。这是一种不常见的情况:时钟偏移是常见的,周期性的抖动调整可能会打乱时间轴。根据需要调整方向,接收者必须插入或移除一个帧来进行补偿。
可以通过在播放序列中重复一帧来插入。请注意,人眼对不均匀播放很敏感。接收者应尽量保持帧间播放时间一致,避免干扰。在较小的播放调整被证明不够时,插入或删除帧才最后被选择。
解码、混合和播放
播放过程的最后阶段包括解码压缩媒体、将多个媒体流混合在一起(如果输出通道少于活动源),最后将媒体播放给用户。本节将逐个介绍每个阶段。
解码
对于每个活跃的源,应用程序必须维护媒体解码器的实例,包括解码缩实例以及编码上文的状态。根据系统的不同,解码器可以是实际的硬件设备,也可以是软件实现。它根据帧中的数据和编码上下文,将每个编码帧转换为未编码的媒体数据。当帧被解码时,源的编码上下文将被更新,如图 6.19 所示。
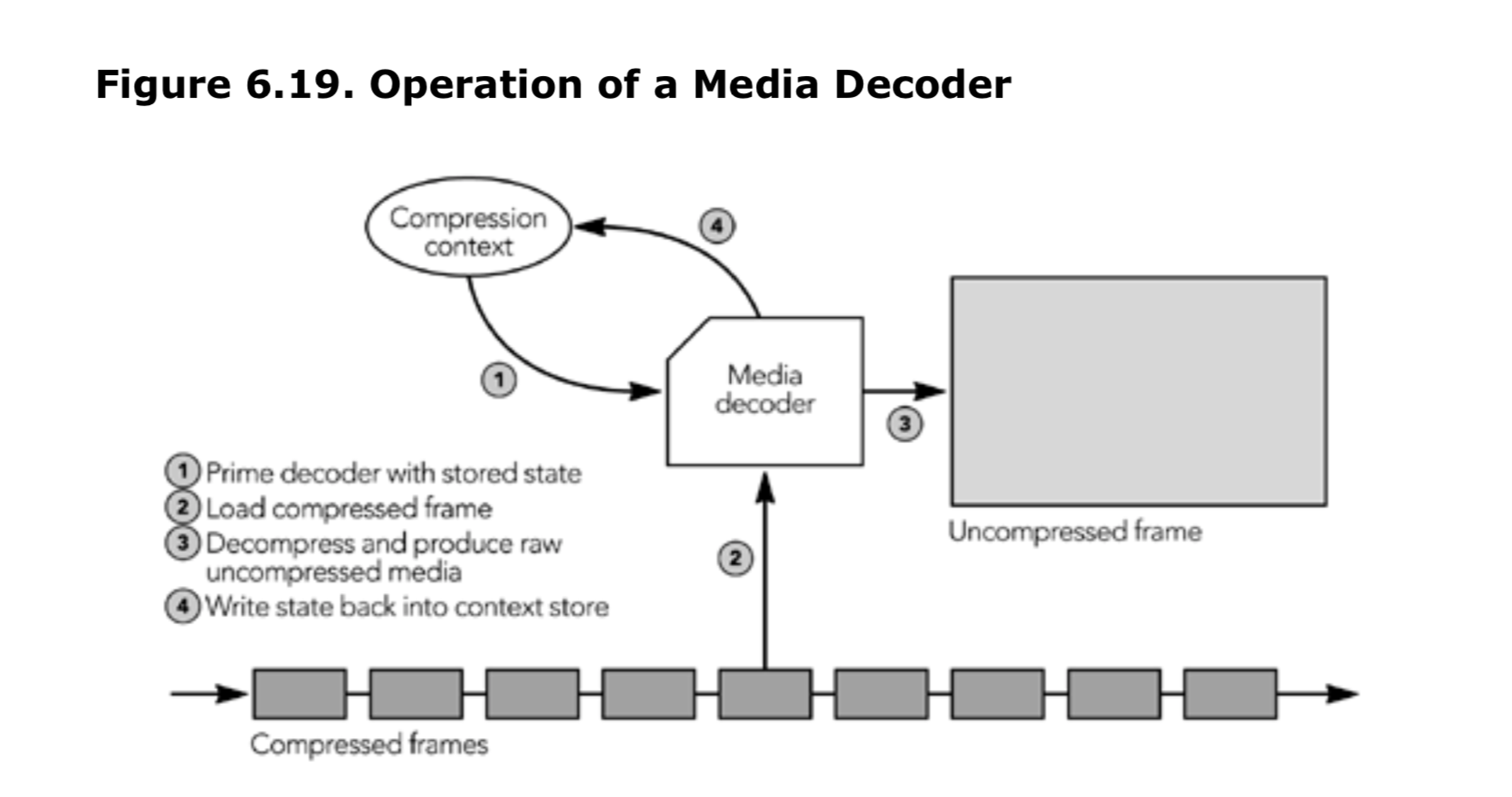
解码器的正确操作依赖于准确的解码上下文状态。如果上下文丢失或损坏,编解码器将产生错误的结果。这是最常见的问题之一,当某些数据包丢失时,会导致无法解码的帧。结果就是在原本应该播放帧的位置会出现空隙,并且解码上下文也会失效,从而影响后续帧的解码
根据编解码器的不同,可以编解码器提供帧丢失的指示,以便解码器更好地修复上下文并减少对媒体流的损坏(例如,许多语音编解码器使用擦除帧来表示丢失)。否则,接收方应尝试修复上下文并掩盖数据丢失的影响,如《第8章,错误掩盖》中所讨论的那样。许多丢失掩盖算法在解码后、混合和播放操作之前对未压缩的媒体数据进行处理。
混音
混音是将多个媒体流合并为一个输出的过程,主要在音频应用中存在问题,因为大多数系统只有一套扬声器,但可能有多个活动源,例如多方电话会议。一旦音频流被解码,它们必须在写入音频设备之前进行混合。音频最后阶段通常的结构类似于 6.20 所示。解码器按照源的方式生成未压缩的音频数据,写入每个源的播放缓冲区,然后混音器将这些结果合并到一个用于播放的单一缓冲区中(如果解码器能够理解混音过程,这些步骤当然可以合并为一个)。混音可以在播放之前任意时间进行。
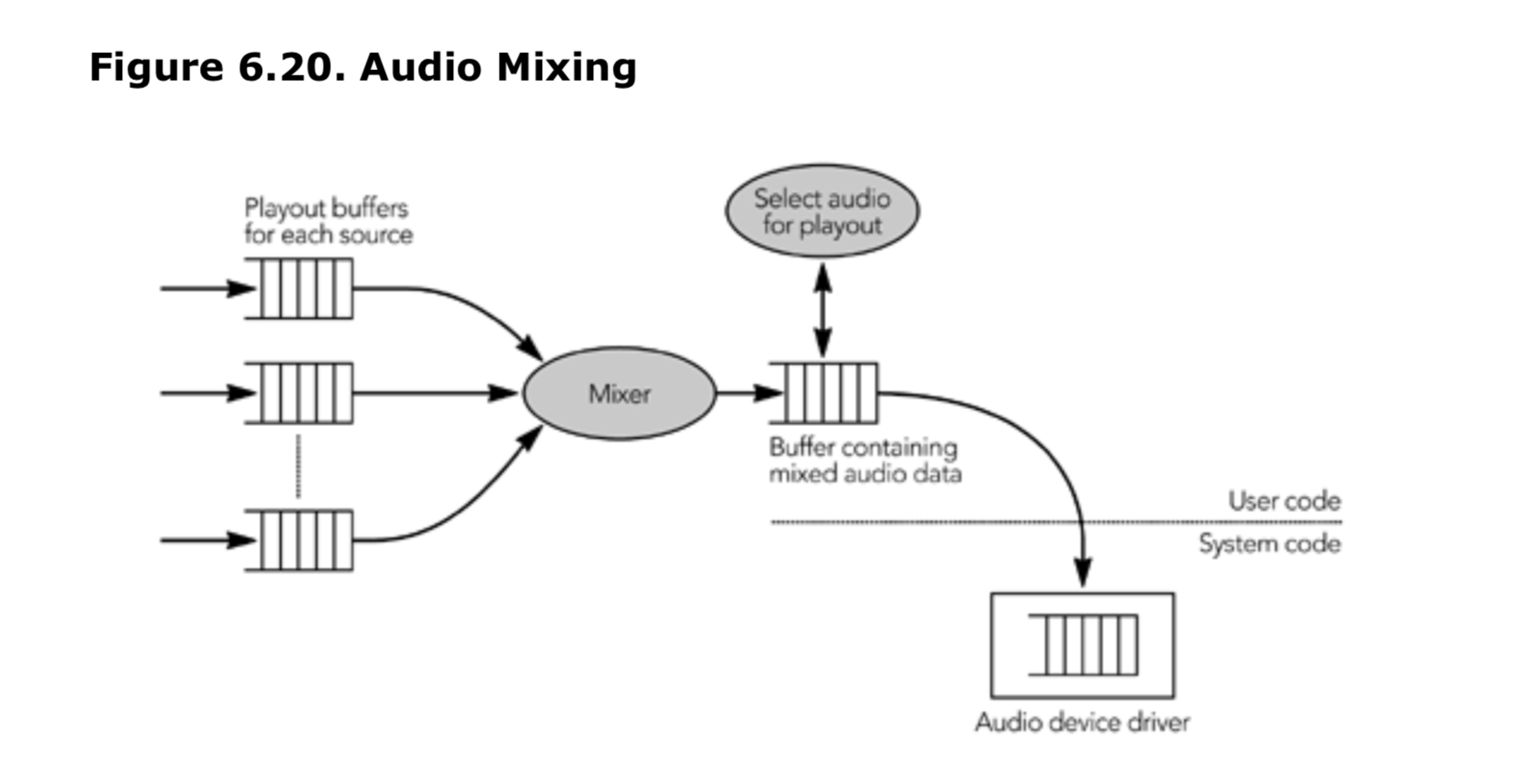
混音缓冲区最初是空的,即充满了静音,每个参与者的音频依次混合到缓冲区中。最简单的混音方法是使用饱和加法,其中每个参与者的音频依次加入到缓冲区中,溢出条件是在极值处饱和。在伪代码中,假设有 16bit 样本,并将一个新的参与(src)混合到缓冲区(mix_buffer)中,这将变成:
audio_mix(sample *mix_buffer, sample *src, int len)
{
int i, tmp;
for(i = 0; i < len; i++)
{
tmp = mix_buffer[i] + src[i];
if (tmp > 32767)
{
tmp = 32767;
}
else if (tmp < -32768)
{
tmp = -32768;
}
mix_buffer[i] = tmp;
}
}
如果需要更高保真度的混音,可以使用其他算法。SIMD 处理器通常有混合采集样本的指令。 例如,英特尔 MMX(多媒体扩展)指令包括饱和加法指令,该指令一次添加四个 16bit 样本,并且由于混合循环不再有分支检查,因此性能最高可提高十倍。
实际的混合缓冲区可以使用循环缓冲区的方式来实现。该缓冲区被实现为一个数组,包含起始和结束指针,通过循环回到起始位置,给人以缓冲区是连续的错觉。
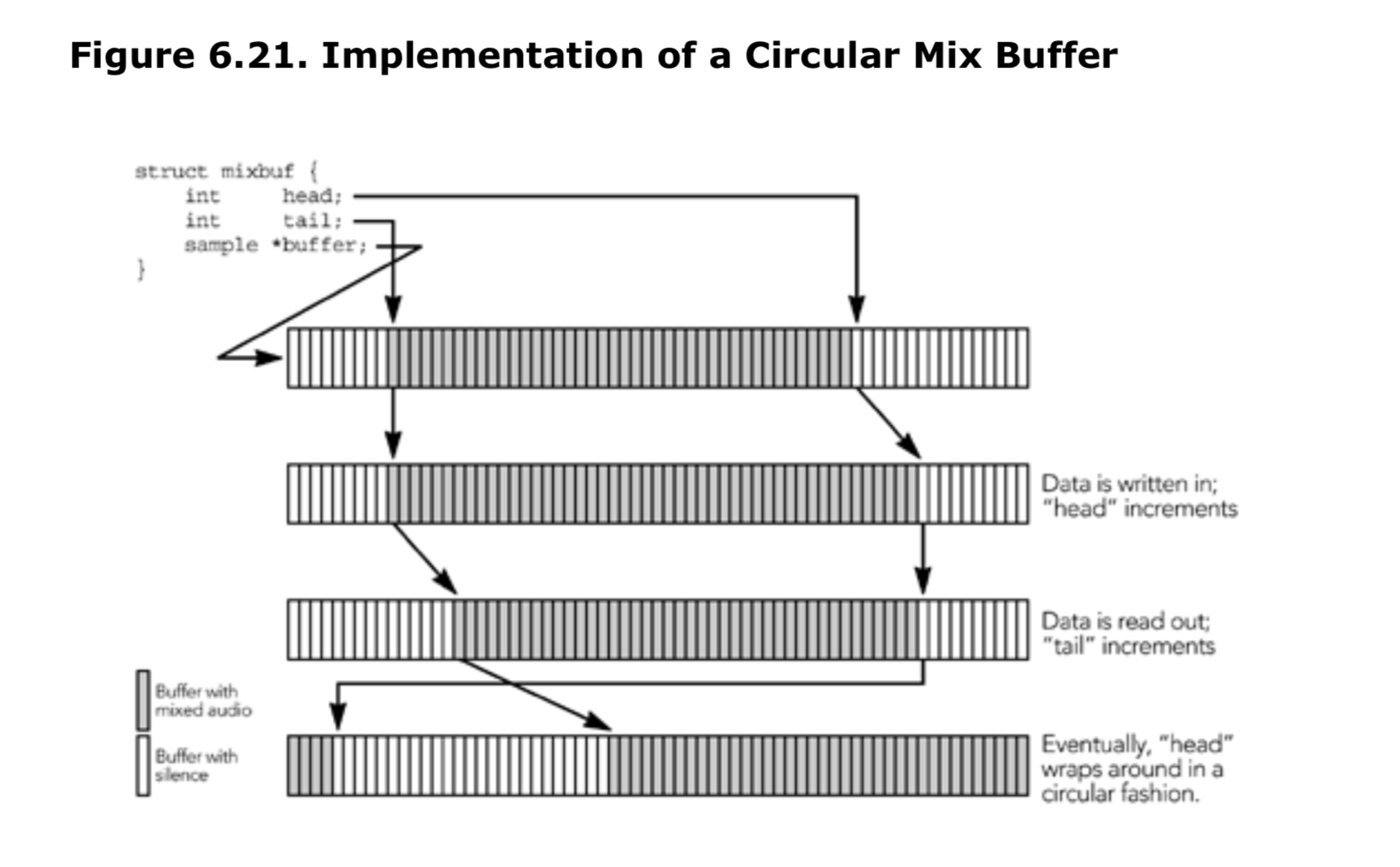
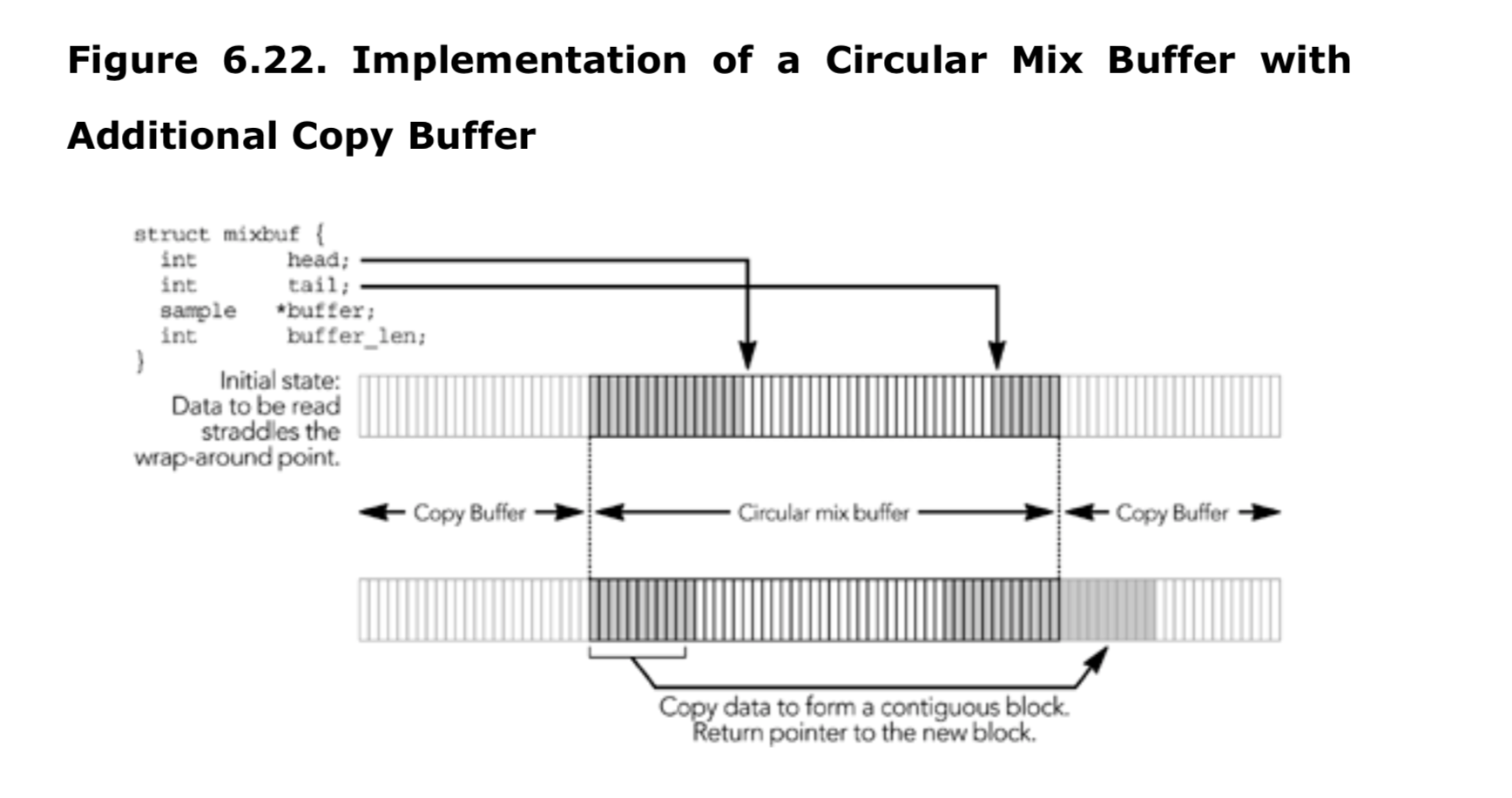
简单的循环缓冲区不能始终提供一个连续的可读取缓冲区,这是它的一个缺陷。当读取接近循环点时,需要返回两个混合数据块:一个来自循环缓冲区的末尾,一个来自开头。如果分配两倍所需大小的数组,则可以避免返回两个缓冲区。如果读取请求的块包含了循环缓冲区的循环点,混音器可以将数据复制到额外的空间,并返回一个指向连续内存块的指针,如6.22所示。这需要额外复制音频数据,最多占循环缓冲区大小的一半,但允许读取返回一个连续的缓冲区,简化了使用混音器的代码。循环缓冲区的正常操作不变,除了在读取数据时会进行一次复制。
音频的播放
音频向用户播放的过程通常是异步的,即系统在处理下一个音频帧时可以播放当前的音频帧。这种能力对于系统正常运行至关重要,因为它可以实现连续播放,即使应用程序忙于RTP和媒体处理。同时,还可以保护应用程序免受系统行为变化的影响,例如由于其他在该系统上运行的应用程序的存在。
在支持有限的通用操作系统上,异步播放对于多媒体应用程序尤其重要。这些系统通常被设计为具有良好的平均响应,但往往在最坏情况下表现不理想,并且无法保证对实时应用程序进行适当的调度。应用程序可以利用异步播放的优势,通过使用音频DMA(直接内存访问)硬件来实现连续播放。如图6.23所示,应用程序可以监测输出缓冲区的占用情况,并根据自上次调度以来的时间调整向音频设备写入的数据量,以确保每次迭代后缓冲区的占用保持恒定。
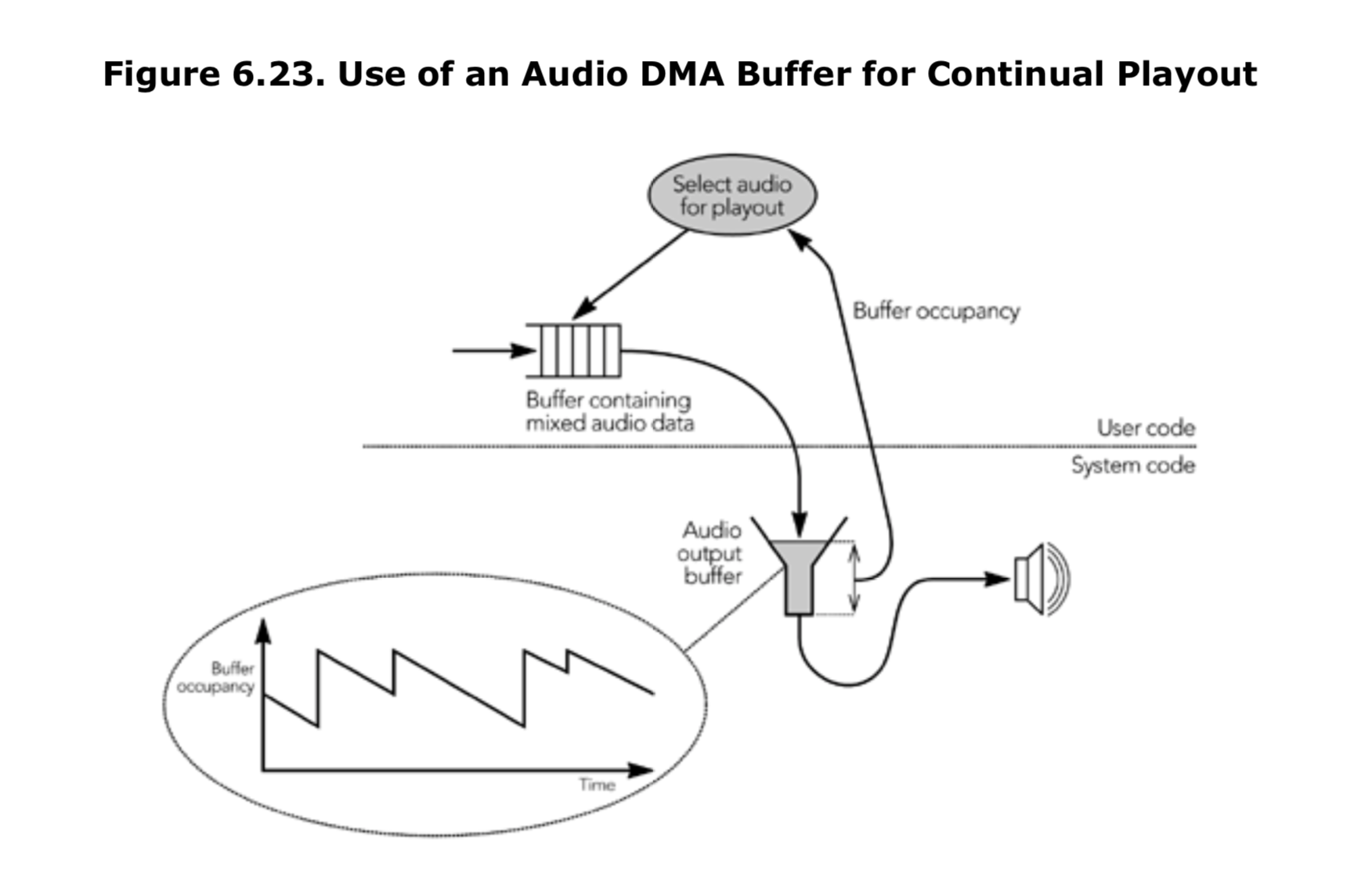
如果应用程序检测到异常的调度延迟期(可能是由于系统上的磁盘活动过大),可以预先增加音频DMA缓冲区的大小。如果操作系统不允许直接监视音频缓冲区的数量和等待播放的情况,可能可以通过应用程序编码端等待读取的音频数量来估算。大多数情况下,音频播放和录制都是由同一个硬件时钟驱动的,因此应用程序可以计算它记录的音频样本数量,并利用这些信息推导出播放缓冲区的占用情况。通过仔细监测音频DMA缓冲区,可以确保在除了极端环境之外实现持续的播放。
视频播放
视频播放很大程度上是由显示器的刷新率决定的,它决定了应用程序写入到输出缓冲区,到将图像呈现给用户之间的最大时间间隔。平滑视频播放的关键是两个方面:(1)帧应该以均匀的速率呈现,(2)在视频呈现时,应该避免帧的变化。第一点是关于播放缓冲区的问题,选择适当的显示时间,如本章前面的视频播放调整部分所述。
第二点与显示有关:帧不是即时呈现的;相反,它们被画成一系列的扫描线,从左到右,从上到下。这种串行表示允许应用程序在显示帧时,可以更改帧,从而会导致输出出现故障。双缓冲可以解决这个问题,一个缓冲区用来组成帧,而第二个缓冲区用来显示。两个缓冲器在帧之间进行切换,并与帧间间隔同步。实现双缓冲的方法依赖于系统,但是,通常是视频显示 API 的一部分。
总结
本章描述了 RTP 发送者和接收者的基本行为,重点介绍了接收者的播放缓冲区的设计。对于,可以接受几百毫秒(甚至几秒)延迟的流式应用程序,播放缓冲区的设计会相对简单。然而,对于为交互使用而设计的应用程序,播放缓冲区对于获得良好的性能至关重要。这些应用程序需要较低的延迟,因此,缓冲区的延迟只有几十毫秒,这就增加了算法设计的工作量,因为算法必须平衡低延迟的需要和避免丢弃延迟的包(如果可能的话)。
RTP 系统在终端系统中设置了很多的技巧(intelligence)使得它们能够弥补在最佳的分组网络中具备固有的可变性。认识到这一点,是获得良好性能的关键:一个设计良好、健壮的实现,可以比一个简单的设计执行的要好得多。